

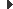
Organització i catalogació de continguts, fonts i mòduls d'informació
Per ser eficient a l’hora de desenvolupar i mantenir un projecte d’aplicacions multimèdia interactives (AMI) complex, cal tenir tota la informació organitzada amb uns criteris clars. Aquesta necessitat es torna més evident quan es treballa en equip. No només ha de quedar normalitzat l’accés al contingut, sinó que el contingut que es produeixi també ha de seguir unes pautes per tal que sigui tan homogeni com sigui possible. En cas contrari, l’usuari final es podria trobar amb productes poc cuidats, on s’evidenciaria la feina de múltiples persones de manera poc cohesionada.
Finalment, és molt important conèixer de manera tècnica com fer servir les eines adients per mantenir segura tota la informació, guardar còpies de seguretat i poder treballar en paral·lel en millores sense molestar la resta de l’equip.
Valoració de la consistència, pertinència i qualitat dels continguts i/o fonts
En qualsevol projecte de desenvolupament mitjanament complex es generen una gran quantitat de documents associats, al marge del desenvolupament i el codi. Per exemple, en jocs hi ha els documents de disseny del joc o GDD (Game Design Documents), que resumeixen el concepte d’un joc, amb prou informació per poder posar d’acord tot un grup i establir-los com una guia bàsica. Aquests documents poden ser molt extensos i plens d’il·lustracions. Altres casos, com ara documents per aplicar a projectes europeus, poden ser inclús més caòtics. Aquest tipus de projectes típicament requereix que diverses institucions, públiques i privades i localitzades en diferents països, treballin conjuntament en els mateixos documents.
És pràcticament impossible que una sola persona escrigui tot el material. Això implica que els continguts s’elaboren en grup. Cada persona pot tenir una opinió i estil diferent, i per tant cal posar-ho en comú. En projectes amb càrrega visual alta, com poden ser els videojocs, aquest és un factor determinant, ja que des del punt de vista de l’usuari cal que tot el joc tingui un estil homogeni. També des del punt de vista de la programació és important, ja que cal definir un patró clar per a les convencions dels noms de classes, atributs i mètodes. En cas contrari, el codi es pot tornar caòtic i es pot perdre molt de temps buscant noms.
A més de les qüestions estètiques i pràctiques, poden sorgir també multitud de problemes tècnics. Els projectes com un videojoc poden tenir una altíssima complexitat, amb multitud de disciplines treballant pel mateix objectiu. Tots els equips han d’estar coordinats respecte als tipus de fitxers, programaris, versions i sistemes operatius que cal fer servir, per evitar incompatibilitats. És més, fins i tot amb tots aquests aspectes sota control, poden sorgir problemes com l’orientació arbitrària d’objectes 3D, els centres o la quantitat de triangles de les malles.
Cal mantenir uns criteris clars en qüestions estètiques (seguir un estil homogeni), pràctiques (treballar conjuntament) i tècniques (evitar incompatibilitats), perquè si no es fa hi pot haver, fàcilment, errors costosos en temps o pèrdua de rendiment per excés de detall.
Unitat estilística (estètica i narrativa)
Des del punt de vista de la unitat estilística estètica, el més important és definir jeràrquicament l’estil del projecte. Una de les primeres decisions que s’ha de prendre és si el projecte és en 2D o en 3D. A partir d’aquesta resolució moltes preguntes estilístiques ja poden quedar resoltes. Per exemple, el nombre de polígons per objecte no és rellevant en projectes en 2D. En aquest cas, el següent pas és decidir el tipus d’art: és un projecte retro que imita antigues consoles de 8 bits o s’utilitza la màxima resolució possible?, quin és l’espai de color que es farà servir?, es tracta d’un projecte amb un estil visualment més aviat fosc o es vol donar un aspecte més de còmic? Totes aquestes preguntes i més qüestions similars han de trobar resposta.
Els projectes en 3D tenen complexitats afegides. A més de preguntar-se el mateix que en el cas de projectes en 2D, els equips que desenvolupin l’aplicació s’han de posar d’acord en altres aspectes tècnics. El nombre de triangles que es mostrarà per pantalla està directament relacionat amb el rendiment d’una aplicació en 3D. Això vol dir que si tenim massa personatges, personatges amb massa detall o escenes massa complexes, l’aplicació perd fluïdesa i l’experiència d’usuari es veu perjudicada ràpidament. També aspectes com la il·luminació i la interactivitat són un factor fonamental que clarament afecta el rendiment. Aquestes qüestions, però, estan lligades a la qualitat visual resultant.
Per exemple, una aplicació en 3D amb unes malles de molt baixa resolució poligonal, una il·luminació amb poc detall i colors plans és coherent. En canvi, si tingués una il·luminació i unes textures realistes, però malles amb un mínim de polígons, no quedaria gens coherent. Per tant, cal tenir en compte els requisits globalment i definir criteris des del punt de vista estètic i tècnic.
La unitat estilística narrativa és probablement més senzilla d’establir en forma de normes, però la més difícil de concretar detalladament. Cal decidir els temps verbals que es faran servir (quin passat, per exemple), si hi ha narrador o no, si l’enfoc és més en els diàlegs o en la descripció del context, si les descripcions són extenses o curtes… Com veieu, alguns d’aquests elements no són sempre senzills d’acotar. Per exemple, és difícil acotar què vol dir una descripció extensa.
També hi ha factors molt específics que es poden definir per homogeneïtzar documents narrativament. Per exemple, les referències a d’altres texts. En documents tècnics és del tot habitual referir-se a contingut ja publicat per reforçar algun argument o per comparar alguna idea, entre d’altres motius. Per no haver de repetir tot el contingut de la font, es pot marcar una referència per tal que el lector pugui trobar fàcilment el text referenciat. Aquestes referències gairebé sempre tenen dues parts:
- Una que queda inserida en el moment en què es necessita fer la referència i
- una altra que és la indicació completa de la font, que queda normalment cap al final, agrupada amb tota la resta de referències del document en una secció que es diu bibliografia.
Com que és una operació molt habitual, hi ha diversos estàndards que marquen de manera molt precisa tant el format de la referència com el de la bibliografia. Per exemple, hi ha el format American Psychology Association (APA) o el Vancouver, que són molt diferents visualment. Com que és bastant feixuc estar pendent de tots els detalls de format de les referències, hi ha moltes eines per a gestionar-les.
Requisits d'adaptació, d'edició o de reelaboració
Un cas que es pot donar freqüentment és començar un projecte que es basi en materials ja existents. En el món dels videojocs aquest cas és del tot comú perquè molts jocs tenen segones, terceres o més parts. En general, en aquests casos, què cal fer-ne dels documents i arxius ja existents? Per contestar aquesta pregunta, es distingeixen clarament dos casos:
Referències bibliogràfiques
Trobareu informació sobre com citar i gestionar la vostra bibliografia a Com citar i gestionar bibliografia.
- Documents explicatius: en aquest cas, cal homogeneïtzar els criteris entre projectes, per tal d’aconseguir una unitat estilística, ja sigui reescrivint i adaptant els documents antics al format nou, o bé modificant els criteris del nou per aconseguir el mateix objectiu. La decisió depèn fonamentalment de la importància dels nous criteris, i de com de fragmentats estiguin els documents anteriors. Es tracta d’estalviar feina innecessària.
- Fonts d’arxius d’altres menes: en el cas dels arxius que no siguin text (imatges, vídeo, so, animacions…) és molt probable que calgui refer-los. La tecnologia avança molt ràpidament, i projectes d’un o dos anys enrere es poden veure antics. De fet, els productors de videojocs o pel·lícules d’animació normalment ja compten que rarament es pot reciclar contingut i dissenyen equips i pressupostos partint d’aquest fet. Per tant, cal afrontar-ho amb la mentalitat de fer-ho tot de nou.
Les excepcions a aquest últim cas són àmplies, però. Les bandes sonores ben produïdes i reconegudes no només es poden reciclar sinó que és molt positiu fer-ho. Repetir banda sonora si és bona causa una associació positiva amb els entusiastes dels productes que no és fàcil de reproduir. També en general es poden reciclar tots aquells arxius per omplir decoració. Per exemple, reciclar animacions de personatges en segon o tercer pla pot tenir un impacte visual mínim i estalviar molt temps de producció. Finalment, aquells projectes molt específics visualment admeten molt fàcilment integrar els arxius existents. Els videojocs amb temàtica 8 bits en són un bon exemple, ja que per molt que la tecnologia evolucioni, els 8 bits de color seguiran sent els mateixos.
Cal dir que, en general, el sentit comú i l’experiència donen respostes senzilles i intuïtives a aquesta qüestió. Depenent del tipus d’arxiu i dels projectes, caldrà adaptar o refer part del material.
Formats adequats d'arxiu
Hi ha moltes aplicacions que treballen amb fitxers per manegar dades. Un exemple molt clar són les aplicacions ofimàtiques. El problema més comú sorgeix quan es fan servir diferents aplicacions o diferents versions que no són compatibles entre elles, o que causen errors. Tot i que cada cop es va resolent més, aquest era el problema més comú de les aplicacions ofimàtiques fa uns anys.
L’arrel del problema és que tot sovint s’introdueixen millores en les aplicacions que no estaven previstes de bon començament. En aquests casos, les novetats només són compatibles amb les versions noves. D’aquesta manera, els fitxers generats amb les versions més modernes deixen de ser compatibles amb les versions antigues. Si bé és impossible preveure exactament el futur, el cert és que hi ha bones pràctiques per evitar aquests problemes. La més comuna és establir una única versió de les aplicacions feta servir per tots els membres d’un equip per a un projecte, i mantenir la versió durant tot el procés.
Alhora, es busca que els desenvolupaments dels projectes tinguin cicles curts per diverses raons, i aquesta n’és una: un desenvolupament que duri massa pot començar amb eines modernes i que en un moment donat aquestes eines ja estiguin fora de mercat. En el millor dels casos, el resultat serà una aplicació pobra visualment, però pot arribar el cas que fins i tot calgui cancel·lar el projecte. Un efecte tan negatiu es podria evitar actualitzant les versions a mig projecte, però les conseqüències poden ser imprevisibles i causar molts problemes i retards. En la gran majoria dels casos, és molt millor planificar separar en diverses versions cada projecte, limitant-ne l’abast i reduint-ne el cicle de desenvolupament.
Criteris d'avaluació, llistes de control i verificació
Avaluar continguts és un procés semblant en molts casos a llançar una aplicació al mercat. Es tracta d’anar iterant i millorant o afegint contingut fins a tenir versions que tinguin prou qualitat per donar-les per bones. Aquest últim pas, donar per bona una versió d’un document o un fitxer, requereix tenir criteris definits. Per exemple, podem diferenciar entre:
- Criteri d’acabament d’un document de text: abans de començar a omplir un document de text, caldria tenir clar quines parts el formen. Formar un índex i definir aproximadament un gruix esperat és una bona pràctica. D’aquesta manera, podem establir un criteri mínim d’acabament.
- Criteri de correcció d’una animació: una animació de caminar es pot considerar completa quan es pugui veure un cicle continu sense salts, de manera que no es vegi la diferència entre passes. També quan totes les animacions secundàries (mans, cara, esquena…) estiguin acabades.
El terme iterar és molt comú en el desenvolupament de projectes, i es refereix a acabar una versió (pot ser incompleta) que tingui sentit com a entitat, i tornar a començar per millorar-la o afegir-hi funcionalitat.
Però la casuística possible de criteris és tan gran que és molt complicat descriure-ho en un curs com aquest. En resum, el que cal tenir en compte és que és fonamental mantenir una consistència dins de tot el material generat per un equip. No només des del punt de vista estètic, sinó també tècnic. Cal definir criteris estètics i tècnics i assegurar-se que se segueixen dins de l’equip.
Determinació dels mòduls d'informació del producte AMI
Un projecte audiovisual multimèdia interactiu (AMI) sol tenir una càrrega narrativa important; per exemple, els videojocs amb mode història s’han de plantejar com afrontar la història que volen explicar. En molts casos es tracta d’explicar una història o ambientar l’usuari en un cert context. És important determinar quin tipus de modalitat narrativa cal utilitzar: lineal o interactiva.
A les seqüències lineals està predefinit el camí que seguirà l’usuari i el final que s’espera. No heu de confondre seqüències lineals amb narratives lineals. Una narrativa lineal es refereix a una progressió temporal de principi a fi sense salts en el temps o referències al passat o futur. Es pot donar que tinguem salts temporals, com en jocs ben coneguts com Prince of Persia, però seguir seqüències lineals. Es pot donar més o menys sensació de llibertat al jugador, però el cert és que haurà de passar per un nombre definit d’etapes fins a acabar el joc, i l’únic que definirà la progressió serà l’habilitat del jugador, a més del temps invertit.
El gran avantatge d’aquesta modalitat és que els projectes són més senzills en gairebé tots els casos. Són més fàcils de produir, de programar, de mantenir, de comunicar… No tot és perfecte, però, i és que els jugadors trobaran a faltar aquesta llibertat de moviments. A més a més, alguns gèneres de jocs, com els RPG, difícilment encaixen amb seqüències lineals.
En canvi, les seqüències interactives són bastant més complexes, però encaixen en gairebé tot tipus de gèneres de joc, i els jugadors ho saben apreciar. De fet, des de fa un temps moltes de les produccions amb més tirada comercial opten per aquesta modalitat. Aquí cal definir bé l’abast de la interactivitat, com es produeix, i quines conseqüències té.
Per exemple, el Knights of the old republic ofereix una narrativa interactiva limitada: el jugador pot fer accions bones i prendre el camí de la llum, o accions dolentes i prendre el camí de l’obscuritat. La diferència no és gaire gran ja que el joc té les mateixes etapes i només afecta cap al final, on és capaç de fer servir algunes habilitats en comptes d’unes altres. El cas oposat, un dels exemples més interessants de narrativa interactiva amb més possibilitats per al jugador, és el joc The Stanley parable. En aquest cas, hi ha una combinatòria realment gran d’accions que pot fer el jugador i que porten a finals totalment diferents.
La tria de la narrativa final té un gran impacte dins del desenvolupament i hi pot afegir una gran complexitat. Per tant, cal rumiar quina és la millor opció. A més a més, cal determinar quina interactivitat s’atorga a l’usuari, i quina és la manera de controlar l’acció dins del projecte.
Graus d'interactivitat i de control
La qüestió fonamental és definir quin tipus d’interacció pot tenir el jugador. Es poden agrupar en dos tipus:
- Un únic final: aquelles produccions que tinguin un únic final poden també introduir interactivitat per donar la sensació de llibertat d’escollir el destí del jugador. Un mètode que ja comença a ser comú és definir un mapa ampli on el jugador és lliure d’anar on vulgui. En punts concrets del mapa, però, s’activen diferents mecanismes d’interacció. Aquest és un exemple d’una manera híbrida d’abordar les seqüencies lineals introduint interactivitat.
- Multitud de finals: els projectes que tenen diferents finals introdueixen situacions on el jugador ha de prendre una decisió que afecta la resta del joc. En aquest cas, un dels problemes és que pot ser que molts jugadors no gaudeixin mai de bona part del joc, ja que no sempre repetiran per fer diferents eleccions.
Pel que fa a la interacció en si amb els elements d’un joc, el procés més senzill és examinar jocs i projectes AMI amb temàtiques semblants. Les maneres que té un usuari d’interactuar amb l’entorn estan molt ben estudiades, i trobar-ne una de nova que funcioni bé és molt molt difícil. No només és difícil de desenvolupar i posar en marxa, sinó de comunicar als usuaris.
Malauradament, la majoria d’usuaris rebutgen haver d’aprendre noves interaccions, i aquest fet sol ja pot tombar un projecte amb una gran qualitat. En molts casos és preferible invertir recursos en la resta del projecte i fer servir modes d’interacció ben coneguts.
Classificació, reestructuració i organització de la informació
Les produccions amb diferents tipus d’arxius i dades, com podrien ser els videojocs, són un repte perquè abasten una gran quantitat de casos. Per això és important tant l’organització de la informació, com la seva classificació, catalogació i indexació.
Catalogar consisteix en descriure un contingut de manera succinta o establir un criteri d’organització per tal que es pugui trobar fàcilment. Per exemple, un criteri de catalogació pot ser ordenar alfabèticament o de manera jeràrquica: ordenar per tipus d’arxiu (documents, multimèdia, animació…) i dins de cada categoria, fer-ho per nom. En qualsevol cas, per ser eficient, la catalogació ha de complir una sèrie de requisits:
- Ha de ser unívoca, és a dir, que seguir els criteris ha de portar a un únic arxiu.
- Ha d’aconseguir una uniformitat del contingut.
- Ha de poder fer que sigui senzill tant guardar com extreure contingut, des d’un sol sistema o des de sistemes diferents.
Poder trobar la informació necessària en qualsevol moment és vital per a la gran majoria de projectes. Per fer-ho, és necessari tenir eines i criteris per organitzar i catalogar les dades.
Un cop establerts els criteris, cal ser sempre metòdics amb les dades i arxius. És molt fàcil que a mesura que creix un projecte s’hi comencin a afegir molts arxius, i la prioritat deixi de ser tenir les dades ben organitzades. Això, però, a la llarga és molt perjudicial per als equips. D’altra banda, ser massa estrictes amb l’estructura pot causar una rigidesa innecessària i una lentitud o sobretreball que només endarrereixen el projecte.
Una manera d’evitar aquests problemes és que els equips facin servir repositoris, i els individus puguin fer totes les proves necessàries en local o amb les branques de desenvolupament, i després organitzar-ho tot abans d’incloure-ho a les branques comunes. Una altra manera és fent servir eines d’administració de mitjans digitals.
Eines d'administració de mitjans digitals
Administrar fonts de diversos tipus és més complex del que pot semblar a primera vista. No només es tracta de tenir-los disponibles, sinó d’assegurar-se que només hi puguin accedir els membres d’un equip que siguin necessaris, que es guardin diverses versions, que es puguin compartir…
A més a més, no sempre es vol restringir l’ús dels arxius per un únic projecte o inclús un únic grup. Arxius de gran qualitat tenen un valor intrínsec al marge de cada projecte, i es poden oferir a d’altres persones a canvi de diners o d’algun acord. D’aquesta manera, podeu ingressar diners o expandir la vostra marca no només amb productes, sinó amb els arxius que conformen aquests productes.
Teniu diverses eines de Digital Asset Management (DAM) que fan aquesta feina. Per exemple, Bynder té una versió gratuïta. Aquesta eina permet guardar arxius al núvol, compartir-los amb més usuaris i fer cerques avançades. També hi ha eines integrades dins d’eines de desenvolupament. Per exemple, Unity incorpora una botiga on desenvolupadors i artistes poden penjar la seva feina de manera gratuïta o cobrant a Unity Asset Store.
A més a més d’oferir aquests intercanvis, els DAM solen oferir també estadístiques per tal que els autors puguin saber què millorar, i també eines per poder parlar amb els usuaris.
Reagrupament i reestructuració de la informació
Tot i ser meticulosos amb les pautes i els criteris definits, és molt possible trobar-se que cal canviar alguns aspectes de l’organització. És impossible predir-ho tot de bon començament, i per tant poden sorgir canvis de requisits a mig desenvolupament, o bé simplement veure que una proposta no funciona.
Donada la necessitat de fer canvis, cal afrontar-ho de manera ordenada. El primer pas és establir quins són els problemes que han sorgit, o quines noves necessitats són necessàries. Després cal consensuar amb l’equip les noves normes i finalment assegurar-se que tothom les ha entès.
La casuística possible és massa àmplia per fer una descripció detallada de totes les passes necessàries en aquests processos. Això si, podem destacar bones pràctiques a la implementació de reestructuracions, sobretot per a aquells projectes que són públics, o que tenen milers d’usuaris o més:
- La primera bona pràctica és escollir un moment per executar el canvi que no sigui crític. L’ús de qualsevol aplicació massiva o dels fitxers d’un projecte amb molts membres fluctua. Els treballadors deixen de treballar després de la seva jornada laboral, i els usuaris tenen en general un comportament diferent els dies festius que els dies feiners. Heu d’escollir un moment on es pugui predir que la demanda d’informació serà mínima, ja que molt probablement caldrà restringir o tallar l’accés durant el procés.
- La segona pràctica és no introduir canvis ni reestructurar just abans d’un període on no hi haurà ningú per mantenir-ho. Per exemple, els divendres solen ser dels dies prohibits a moltes empreses per a publicar canvis, ja que si hi ha un error, durant el cap de setmana no hi haurà ningú per arreglar-lo.
Metadades: processament i recuperació de la informació
Qualsevol arxiu conté bastant més informació que no només el seu contingut. Per exemple, cada arxiu té una mida, un tipus, un autor, un autor de l’última modificació, una data de creació i de modificacions, una sèrie de permisos, quin programa s’ha utilitzat per modificar o crear… A més, depenent del tipus d’arxiu, hi pot haver més metadades. Per exemple, els vídeos tenen una llargada, un còdec, un bit rate, una resolució…
Les metadades són un recull d’informació addicional (com per exemple, data de creació, autor, mida…) que estan associades a un arxiu digital o recurs.
Tota aquesta informació pot fer-se indispensable. Per exemple, molts projectes tenen diferents versions segons el dispositiu o la gamma de dispositius als quals es dirigeixen. Per exemple, no té gaire sentit fer servir gràfics en alta definició si la pantalla del dispositiu amb què s’està gaudint no ho és.
A banda, moltes d’aquestes metadades s’omplen i es processen automàticament. Gràcies a això, es poden establir criteris de catalogació senzills, ràpids i eficaços que minimitzin l’acció dels usuaris. També hi ha molts sistemes automatitzats que poden llegir aquestes metadades molt ràpid, per tant és molt eficient a l’hora de fer cerques i recuperar informació.
Avui en dia les metadades són cada cop més presents gràcies a la intel·ligència artificial. Aquests sistemes comencen a ser capaços d’analitzar el contingut i extreure patrons i conclusions d’alt nivell. Per exemple, ja és habitual trobar serveis que puguin distingir tipus d’animals a fotografies. Aquesta informació es pot incorporar al conjunt de metadades, per accelerar les cerques.
Diagramació dels continguts organitzats
Com que els criteris de catalogació poden ser jeràrquics, es poden dibuixar perfectament en diagrames senzills i ben entenedors. Aquesta és una molt bona manera de comunicar-ho a un equip o al públic en general.
Vegeu ara un exemple d’un diagrama d’organització dels fitxers d’un videojoc. Imagineu que es vol fer un joc de simulació de futbol. Com podeu imaginar, hi haurà una gran diversitat de fonts. Contindrà models en 3D dels jugadors, les seves textures, les seves animacions, el so, la intel·ligència artificial… A més, el projecte tindrà el so dels comentaristes, en diferents idiomes, les textures de les interfícies, tutorials…
La pregunta pot ser: com cal començar a organitzar-se? No hi ha una única resposta vàlida. Depèn de les dinàmiques de treball dels equips. En projectes tan grans els equips solen ser petits i tenir líders que es comuniquen amb altres líders d’equips, i les estructures de fitxers poden reflectir aquesta organització. Per tant, la figura podria ser una solució inicial, de manera simple.

El problema d’aquesta organització és que no facilita la col·laboració. Per exemple, simular un futbolista és més que un model 3D. Li calen les animacions, les textures… De fet, a l’hora de dissenyar i provar el comportament d’un futbolista cal poder visualitzar el resultat i fer les modificacions apropiades. Per tant, tot i que aquests criteris són clars, no faciliten els projectes multidisciplinaris.
Una alternativa més adient en aquests casos és formar unitats autocontingudes. Per exemple, tot el que és necessari perquè un equip pugui dissenyar un jugador de manera completa. En el diagrama de la figura figura es pot veure un exemple d’aquesta organització.

Però encara es pot millorar. Els equips que treballen amb models 3D o textures normalment ho fan de manera indiferent de si es tracta d’un model o un altre. A més a més, un partit de futbol no té només un jugador, sinó fins a 28. I també els equips solen estar en una lliga, que al seu torn també té unes característiques. Per tant, es pot jerarquitzar encara més. En el diagrama de la figura figura es poden veure en plural totes aquelles classificacions que tindran múltiples instàncies. Per exemple, un equip tindrà múltiples jugadors, i una lliga múltiples equips.
En resum, és fonamental determinar els mòduls d’informació dels projectes AMI. Establir criteris per organitzar i classificar la informació de manera consistent i sistemàtica no només és una bona pràctica, sinó que és clau per establir processos eficients. Penseu que no hi ha una única solució a cada context, sinó que depèn de les dinàmiques de cada equip o conjunt d’equips. El mateix projecte amb un abast més petit o més gran pot requerir diferents maneres d’estructurar els fitxers i diferents criteris d’organització.
Els drets d'autor i les seves característiques
Per protegir un projecte o una idea hi ha els següents mecanismes:
- Patent: serveix per garantir el dret exclusiu d’ús d’una idea per part del grup que obté la patent. A canvi, cal publicar com a part de la patent una explicació entenedora que descrigui com arribar a desenvolupar la idea o solució. El requisit fonamental és que aquesta idea sigui nova (no hagi estat publicada anteriorment) i que no sigui trivial. A més, cada geografia (cada país o regió) té algunes particularitats, però el concepte és el mateix. Una particularitat molt propera és la de la Unió Europea: no es poden patentar aplicacions directament. Una manera de poder patentar aplicacions és que formin part d’una solució més global, com per exemple si està associada a una màquina.
- Copyright: és semblant a una patent, però és menys restrictiu. Es pot protegir contra la còpia pràcticament qualsevol concepte. Ja pot ser la lletra d’una cançó o una aplicació, no hi ha restriccions. Això sí, el projecte ha de ser nou. També és un intercanvi, en el sentit que es garanteix aquesta protecció a canvi de publicar el concepte.
- Trademark: no protegeixen idees, sinó la marca. Per exemple, es pot protegir un disseny, un nom, un logotip… Cal tenir en compte, però, que si no es fan servir es perden.
- Trade secret: no és realment una protecció, sinó que és mantenir en secret i no divulgar les idees clau. Lògicament, aquesta no és una protecció ferma perquè els secrets es poden filtrar i acabar en mans de competidors. Aquests casos se solen donar quan membres dels equips o treballadors d’una empresa canvien d’empresa o creen la seva pròpia, perquè ningú pot ser obligat a oblidar el que ha après. En aquestes situacions la forma més habitual de protecció és un contracte amb clàusules que prevenen treballar per competidors durant un cert temps, i també responsabilitzar legalment els treballadors per mantenir els secrets.
Com es pot veure, les opcions per protegir un projecte o són diverses, i cadascuna té avantatges i inconvenients, com també camps concrets d’actuació. En aquest sentit, ens podem fer una sèrie de preguntes:
- La primera pregunta és si es pot assumir que allò que es vol protegir sigui públic. Per exemple, en contractes amb agències de defensa, o amb tecnologies capdavanteres, aquesta no és una opció. Per tant, les patents i el copyright no es poden aplicar. Els trademarks, en aquest cas, són irrellevants.
- La segona pregunta és si ja s’ha publicat i si serà útil la protecció, tenint en compte que es converteix en domini públic. Qualsevol publicació explicativa pot ser suficient per anul·lar una sol·licitud de patent. El copyright, en canvi, funciona de manera diferent. Aquest últim mètode de protecció protegeix allò que se sol·licita, de manera pràcticament literal. És a dir, que si voleu que el codi de la nostra aplicació tingui copyright cal enviar el codi i es protegirà contra codis massa semblants. Val a dir que la frontera respecte al fet que un codi s’assembli a un altre és molt fina, i no sempre es convertirà en una protecció útil. També cal tenir en compte que el codi gairebé mai s’estabilitza en una versió fixa, sense canvis. Per tant, en l’evolució d’aquest codi és molt probable que es perdi l’essència del copyright, o que calgui fer-lo de nou. A més a més, convertir el codi en públic vol dir exposar-se a que els competidors aprenguin, el millorin i hi trobin errades. Per tant cal valorar si aquestes són les proteccions més adients, tenint en compte com es transforma en un bé públic.
- La tercera pregunta és quina zona geogràfica ens interessa protegir. Resulta bastant costós sol·licitar i mantenir patents a cada país. Per tant, si no teniu previst entrar i operar en alguns països, podem deixar-los de banda i enfocar els recursos en les zones que sí que seran rellevants. Això sí, com que hem fet públiques les nostres dades, ens arrisquem a que competidors d’àrees desprotegides desenvolupin els seus projectes als seus països d’origen. En el cas, però, de voler ampliar la protecció dels nostres projectes a d’altres països, hi ha diversos mètodes.
- Finalment, cal preguntar-se si realment cal invertir recursos en protecció de drets d’autor. En una indústria tan ràpida com la tecnològica, aquests processos lents i costosos poden alentir el desenvolupament dels productes, que al final són el que decidiran el futur de cada projecte. És important fer un pas enrere i tenir ben clar què és important protegir i què no, i sempre consultar experts.
En resum, hi ha diversos mètodes per protegir les nostres creacions. Cadascun d’ells té les seves característiques i limitacions, per tant, cal examinar quin tipus de protecció és possible i adient. També cal examinar detalladament quines són les zones geogràfiques que cal protegir i prendre les decisions adients.
No sempre protegir tot el possible serà la millor opció, ja que implica invertir en uns recursos aliens al producte que, d’altra manera, es podrien invertir en el producte en si.
Sistemes d'emmagatzematge, còpies de seguretat i control de versions
Feu ara un exercici de memòria i recordeu tots els suports físics on hàgiu guardat arxius. Des de CD, DVD, pen drives, discs durs, emmagatzemament al núvol, i més antigament també disquets o cassets. Segur que heu tingut a casa molts d’aquests sistemes, però amb el pas del temps ja no serieu capaços de recuperar la informació. En alguns casos, perquè s’ha perdut el suport, en d’altres perquè ja no funciona, o fins i tot perquè ja no teniu cap aparell capaç de llegir el contingut, perquè han quedat desfasats.
Tot sistema de transmissió i emmagatzemament de dades està subjecte a errades. Les transmissions es poden tallar degut a una àmplia varietat de motius, des de físics (tallades de cables, que se’n vagi l’electricitat, tempestes electromagnètiques…) fins a per errades humanes, passant per atacs maliciosos. L’emmagatzemament té el mateix problema, i és que qualsevol sistema al final es pot trencar i pot sofrir el pas del temps. De fet, tots els suports físics d’emmagatzemament tenen una garantia i uns períodes estimats de duració. Pel desgast que pateixen els materials al fer escriptures i lectures, com més operacions d’aquesta mena es facin, abans deixaran de funcionar. Tot i semblar que un disc dur està en perfectes condicions, poden haver-hi parts que no funcionin correctament. El resultat serà que de tant en tant la informació no es podrà guardar o llegir correctament.
Quan hi ha un problema amb un suport físic, tant de lectura com d’escriptura, el resultat és que quan es volen llegir les dades el resultat és incoherent. L’aplicació encarregada d’utilitzar les dades o el sistema operatiu, doncs, en el millor dels casos emet un missatge d’error dient que les dades no es poden interpretar. En el pitjor, però, causarà un error i l’aplicació o el sistema operatiu sencer es pararan. La primera conseqüència d’aquest procés és que com a programadors heu de ser conscients que aquests casos es poden donar. Per tant, heu de controlar sempre cada lectura per possibles errors d’integritat.
La solució més òbvia a aquest problema podria ser tenir còpies de seguretat, guardant diversos cops cada fitxer en diferents carpetes o suports físics. Això, però, no és una solució gens eficient, ja que voldria dir ocupar el doble d’espai sempre, mentre que aquests errors són molt poc freqüents. A més a més, no seria una solució fiable del tot, ja que si de dos fitxers se’n llegeixen dades diferents, tampoc es tindria cap criteri per decidir quin és el fitxer correcte. I, evidentment, afegir un tercer fitxer només faria el sistema més complex.
Una altra solució podria ser anar escrivint sempre fitxers diferents, i conservar sempre el fitxer anterior. En aquest cas, perdre un dels fitxers antics no suposaria cap problema, però no serviria de res en cas de pèrdua del més recent. I també suposa un ús encara menys eficient dels recursos, ja que potencialment hi hauria una infinitat de còpies de qualsevol fitxer.
Aquests sistemes estan àmpliament superats pels sistemes moderns de còpies de seguretat, de protecció de dades amb redundància i pels repositoris. Amb aquests sistemes no només es poden guardar fitxers amb molta més seguretat respecte a fallades, sinó de manera eficient, i fins i tot transparent de cara al sistema operatiu. Les còpies de seguretat i els repositoris funcionen de manera molt diferent, però són complementaris. Si bé conèixer el detall complet de tots els sistemes no és necessari d’entrada, és important conèixer-ne la base.
Com a programadors heu de vetllar per la integritat i la disponibilitat de la informació. Hi ha dos problemes extremadament comuns que, en el pitjor dels casos, poden enfonsar qualsevol empresa o projecte: la pèrdua de dades i introduir canvis que continguin errades. Per solucionar aquests problemes teniu dues eines ben provades al món real: les còpies de seguretat i els repositoris.
Sistemes de suport i recuperació de dades
El cas ideal de protecció contra la pèrdua de dades és aquell que no requereix cap tipus d’intervenció de l’usuari ni del programador. Però, com aconseguir-ho? Recordeu l’origen de les fallades d’escriptura o lectura: tot es basa al final en el fet que els suports físics es degraden al cap del temps i de l’ús. Però no tot deixa de funcionar de cop. De fet, la gran majoria de vegades, només una petita part dels suports físics deixa de funcionar. Per exemple, un disc dur internament està dividit en petites parcel·les de memòria permanent, que es diuen sectors. I cada disc dur té milions de sectors. Doncs un sector dins d’un disc dur es pot espatllar i donar sempre error. I un fitxer pot ocupar diversos sectors, milers, fins i tot, i per tant deixar de ser llegible només pels errors produïts en un sector. Com s’evita aquest problema?
Els sistemes Redundant Array of Independent Discs (RAID) s’aprofiten del fet que no tot deixa de funcionar de cop, i que dos discs durs no comencen a donar errades alhora. De fet, es pot esperar que hi hagi un marge prou gran de solapament on, si un falla, l’altre encara funcionarà durant un temps suficient per recuperar la informació i arreglar el disc dur que falli.
Hi ha diferents configuracions de RAID, segons les necessitats i els components que es configurin, però el concepte en el fons és el mateix. La idea és tenir la informació distribuïda i de manera redundant en diversos discs durs. Però oi que tenir redundància amb les dades porta a errors i problemes? Sí, la redundància amb les dades és molt problemàtica i té un cost, però en aquest cas la gestió es fa en l’àmbit del maquinari i a un nivell molt primitiu dels controladors dels discs durs. D’aquesta manera, fins i tot el sistema operatiu pensa que és un únic disc dur i no una unitat més complexa. I com que és compatible amb discs durs de gammes baixes, l’augment de cost pel fet de necessitar més discs durs per la mateixa quantitat d’informació no és tan alt, i es pot justificar bé pels beneficis que se n’obté.
Cal dir també que no totes les configuracions RAID estan pensades per salvaguardar la integritat de les dades, i per tant cal que les conegueu i les sapigueu aplicar quan convingui:
- Per exemple, la primera configuració RAID, el RAID 0, està pensada per a augmentar la velocitat d’accés a les dades. La manera com ho fa és fent servir dos discs durs i posant la meitat de la informació en cadascun. D’aquesta manera, quan es vol llegir un fitxer, es demana la informació als dos discs durs alhora, i el resultat és que la informació arriba el doble de ràpid. Com a nota important, en aquest sistema, si es perd un disc dur o inclús una part, es perd tota la informació.
- RAID 1 és una configuració simple però eficaç a l’hora d’assegurar la protecció de les dades. En aquest cas, el sistema simplement utilitza un dels disc durs com a còpia exacta de l’altre. Aquí el sacrifici és que necessitarem el doble de discs durs, i que el sistema només podrà oferir tant d’espai com la mida del disc dur més petit. A canvi, si s’espatlla qualsevol dels dos discs durs es pot continuar i recuperar les dades sense cap problema. La resta de configuracions treballen a base de tenir com a mínim tres discs durs, on un d’ells emmagatzema el resultat d’una combinació de les dades dels altres discs durs. L’avantatge d’aquestes configuracions és que no cal duplicar la capacitat dels discs durs, sinó que amb només un disc dur extra ja n’hi ha prou.
- Finalment, també hi ha configuracions niades, en les quals es poden dividir parts dels discs durs per configurar-les com algun tipus de RAID, mentre que la connexió entre els diversos discs durs es configura com un altre RAID. Per exemple, es pot tenir un RAID 0+1, on dos discs durs estan configurats en RAID 1, i alhora cada disc dur està subdividit en RAID 0 internament.
Respecte als sistemes físics que s’utilitzen actualment en els entorns laborals, la resposta és que depèn molt de les necessitats de cada projecte o servei, i concretament de si les dades es necessiten habitualment. Per exemple, en entorns com els bancs, en la gran majoria de casos es necessita només una informació recent. Les transaccions antigues, aquelles fetes anys enrere, gairebé mai es consulten (reflexioneu si cerqueu habitualment les vostres transaccions més antigues, el més probable és que només consulteu el que hagi passat en els darrers mesos o setmanes). En canvi, dades com el perfil d’usuari d’una xarxa social han d’estar llestes en qualsevol moment, i a més la velocitat d’accés pot determinar l’èxit de la xarxa. Imagineu si faríeu servir una xarxa social on haguéssiu d’esperar un minut per cada perfil que volguéssiu mirar. I tampoc seria un problema crucial trobar-se amb un perfil no actualitzat.
Aquestes diferències marquen el tipus d’emmagatzemament i l’estratègia de seguretat i recuperació de dades. En aquells casos on les dades són crítiques, però no necessàries en qualsevol moment, els suports físics que es fan servir habitualment són discs durs amb configuracions RAID 1 i còpies de seguretat amb sistemes de cintes magnètiques. Els sistemes magnètics fa temps que no es veuen dins l’àmbit particular i domèstic, però és una tecnologia molt provada, barata i que ocupa molt poc espai físic per byte (són molt semblants a les cassets de ja fa uns anys). En canvi, els sistemes que necessiten donar resposta immediata actualment fan servir discs durs SSD professionals en configuracions RAID 3+0 o 5+0. També és habitual que ho combinin amb sistemes de seguretat basats en cintes, però d’una manera menys metòdica i regular que l’altre cas.
En empreses més petites, però, des de fa un temps la solució és més senzilla. Es poden fer servir serveis d’emmagatzemament al núvol. Aquests serveis típicament consisteixen en definir una carpeta concreta on tot el que hi hagi dins es copia a un espai remot, establint una connexió via internet. Aquest espai remot està gestionat per empreses com Google o Dropbox, i de manera transparent per a l’usuari fan servir els mateixos sistemes que les empreses grans amb necessitats importants d’accés a les dades (configuracions RAID o còpies de seguretat amb cintes, per exemple). En aquests casos, un avantatge afegit és que els arxius o carpetes es poden compartir amb diversos usuaris, i que qualsevol canvi es sincronitza després amb tots els usuaris.
En tot cas, qualsevol equip preocupat per protegir les dades pot seguir una sèrie de bones pràctiques ben senzilles, com ara:
- La regla del 3-2-1, que indica que heu de procurar que hi hagi tres còpies de les dades més sensibles, en dos dispositius diferents, on almenys un sigui fora del lloc habitual de treball. Si només teniu dues còpies d’un arxiu i són diferents, no sereu capaços d’identificar la correcta, però amb tres sí. Aquest procés es pot automatitzar amb scripts o programes específics, independentment de les possibles configuracions RAID. De fet, ni la millor configuració de seguretat és capaç de protegir contra possibles errades humanes, com esborrar arxius per error. Per tant, és important tenir aquestes tres còpies i ser metòdic o automatitzar-ho.
- Copiar les dades en dos dispositius diferents protegeix contra les fallades en un dispositiu concret. Si bé és cert que les configuracions RAID poden ser molt robustes pel que fa a errors, no ofereixen cap protecció contra robatoris, pèrdues, actes de vandalisme, o desastres naturals entre d’altres. Justament per això també és important que com a mínim un d’aquests dispositius estigui en un altre lloc físicament.
- Per implementar aquestes bones pràctiques, es poden fer servir serveis en el núvol, que ja fan la feina automàticament. En ocasions algunes empreses tindran normatives que els impedeixin utilitzar núvols comercials, però això no és cap problema. Hi ha múltiples solucions ja preparades, com per exemple Resilio, per tenir serveis amb la mateixa funcionalitat, però sota el control total de l’administració de l’empresa que ho configuri.
Cal preguntar-se també amb quina freqüència cal fer còpies de seguretat, si se’n fan. No hi ha una única resposta: depèn molt de cada cas. Per exemple, en entorns amb equips de poques persones on la velocitat de canvi no és gaire gran, es pot fer setmanalment. En el pitjor dels casos es perdrà una setmana de feina de tots els integrants de l’equip, però aquest cas és molt poc probable, sobretot si es fa servir la regla 3-2-1. Cada membre tindrà còpies de seguretat en local als seus dispositius, i n’hi hauria d’haver algun que no estigui al mateix entorn físic. Per tant, és poc probable i l’impacte no seria tan gran. D’altra banda, amb equips molt grans, perdre potencialment una setmana de treball seria tan car que justifica una despesa major en còpies de seguretat, i per tant fer-les de manera diària. Finalment, en entorns amb una generació molt alta de dades que costen molt de generar (com per exemple en centres d’investigació) les còpies de seguretat podrien ser inclús més freqüents. En tot cas, analitzeu l’entorn i reflexioneu sobre les necessitats.
En el cas, però, de perdre dades tot i tenir les proteccions adequades heu de saber reaccionar i ser capaços de recuperar les màximes dades possibles. Afortunadament hi ha moltes eines que ajuden en aquesta tasca. De fet, fins i tot hi ha blogs amb entrades dedicades a comparar diversos programes de recuperació de dades, com LifeWire. La idea de tots aquests sistemes és que en moltes ocasions tot i que el disc dur no sigui capaç d’entendre que té informació, els sectors del disc dur la tenen. Això pot ser perquè el disc dur ha sofert algun tipus de problema parcial, i ha calgut canviar-ne alguna part. Molt sovint aquests problemes ocasionen que el disc dur deixi de funcionar correctament, tot i tenir la informació correctament emmagatzemada.
Els programes dedicats a recuperar dades solen ser molt senzills d’utilitzar. Es configuren indicant quins són els discs durs a analitzar, i per als més avançats cal indicar si hi ha algun tipus de configuració RAID. Un cop iniciat el procés només cal esperar, i normalment no triguen gaire. Cal dir que, de vegades, per a algunes dades no queda bé la lectura (al cap i a la fi és normal, esteu intentant recuperar dades d’un disc dur que havia deixat de funcionar correctament). Per tant, els programes poden generar diversos resultats amb diverses interpretacions. Com a usuaris haureu d’examinar els resultats manualment i determinar quin és el millor. Seria molt optimista desitjar una recuperació completa de totes les dades i sense errors, tot i que no és descartable. El cas més probable serà una recuperació de la majoria de dades, però alguns arxius es perdran.
Tipus de còpies de seguretat
Una còpia de seguretat es pot fer de diverses maneres. La més senzilla i evident és copiar cada arxiu sencer, i fer-ho així per cada modificació. Aquest sistema funciona i és molt fàcil d’implementar i automatitzar, però és perfectible. Té l’inconvenient de duplicar la necessitat d’espai d’un sol fitxer i de no mantenir versions antigues.
En comptes de fer una còpia completa, alguns sistemes fan còpies de seguretat incrementals. D’aquesta manera, només es guarden els nous valors, i no cal tornar a guardar tot el fitxer sencer. Aquesta és una pràctica molt comuna en sistemes on en principi el passat és immutable. Per exemple, les transaccions bancàries un cop fetes queden registrades i ja no poden canviar. De fet, en cas d’error els bancs enregistren una nova operació desfent l’errada, però no modifiquen les dades inicials. Un altre exemple poden ser els videojocs. Molts estudis volen veure com els jugadors fan servir els seus productes. Per fer-ho, enregistren totes les accions rellevants a mesura que els usuaris les activen. Lògicament, aquí interessa fer còpies incrementals d’aquests registres perquè les accions passades ja no es poden canviar.
El problema d’aquest sistema és que per calcular l’estat més actual, cal llegir tots els fitxers des del començament. Això pot significar una pèrdua de rendiment important, i un temps de resposta molt baix. A més a més, si es perd fins i tot només un dels fitxers, inclús dels antics, ja no es pot calcular l’estat més actual. La solució a aquests problemes és fer còpies d’estats actuals de manera regular, de manera que no calgui llegir gaires fitxers fins a tenir les dades més recents.
Una còpia de seguretat diferencial és un concepte senzill. Es basa en guardar només els canvis entre versions d’un mateix fitxer. D’aquesta manera es minimitza l’espai necessari per a cada còpia de seguretat. Té l’avantatge respecte a les còpies de seguretat incrementals que funciona en qualsevol tipus d’entorn. No cal que siguin dades amb un ús concret, sinó que pot ser molt eficient per a fitxers tan canviants com el codi d’un projecte. De fet, és el tipus de còpia de seguretat que es fa servir en tots els sistemes de control de versions. A més a més, permet tornar fàcilment a una versió antiga i comparar-la amb l’actual. D’aquesta manera, es poden fins i tot assignar comentaris a cada còpia de seguretat, de manera que es pugui identificar ràpidament quins canvis representen.
De totes maneres, cal entendre que no tots els casos són òptims per a aquest tipus de còpies de seguretat. Per exemple, els fitxers binaris de dades molt canviants o les dades encriptades o comprimides representen tants canvis als fitxers que no val la pena fer còpies diferencials. L’ús més adient és per a text, perquè és comprensible pels humans, i perquè permet veure molt fàcilment els canvis.
Tant els sistemes de còpies diferencials com els sistemes de còpies incrementals poden no ser sostenibles a llarg termini. Es tendeix a acumular massa informació innecessària, i en algun moment cal netejar. Una pràctica comuna és establir còpies de seguretat dels arxius sencers i de l’estat actual un cop per setmana, i començar repositoris nous amb versions totalment noves.
Integritat i disponibilitat de la versió adequada dels productes
Tot sovint, canvis de versions de programes signifiquen deixar de ser compatibles amb les dades disponibles. O se n’afegeixen de noves, o es modifica el significat, o s’elimina la necessitat… Per tant, com a programadors heu de ser conscients que alguns usuaris poden estar fent servir còpies de seguretat.
Una manera de facilitar la compatibilitat enrere és guardant dins de les dades la versió del model de dades que esteu fent servir. És a dir, si la versió del vostre programa canvia però les dades no es modifiquen, el model de dades no canvia. Però si canvien els camps que es guarden o el tipus d’estructures, llavors es pot considerar que és un model nou de dades. Tenint en compte això, es poden fer diferents lectures dels fitxers depenent del model de dades, i evitar així molts errors. Com a alternativa, es poden programar conversors. Són petits programes que transformen els formats antics a formats nous, de manera que les versions més noves també siguin compatibles. Aquest és el mètode més emprat en els paquets de programari més coneguts.
El cas més complicat és quan cal donar servei a diferents usuaris que poden intercanviar-se dades. Les aplicacions mòbils i els jocs són casos molt habituals perquè el ritme d’actualitzacions és prou alt, i molta gent s’ha acostumat a actualitzar sempre que es pugui totes les seves aplicacions. En canvi, hi ha molta gent que prefereix no fer-ho. Per tant, és inevitable trobar-se amb una fragmentació de les dades. En aquests casos, la millor solució és treballar amb connexió a internet i col·locar les dades a algun servei al núvol. Molts dels serveis inclouen bases de dades NoSQL, amb les quals es pot interoperar entre versions diferents, i ja se n’encarreguen els proveïdors dels serveis, de fer les còpies de seguretat correctament.
El terme model de dades es refereix a les estructures de dades que es guarden i la forma com es guarden; és a dir, quines dades es guarden i amb quina seqüència.
Sistemes de control de versions: diferències, estat i traça de productes
Quan un equip està treballant amb els mateixos fitxers poden sorgir dubtes i problemes, com ara: com es poden compartir els fitxers?, com es pot assegurar la qualitat del producte?, com cal assignar responsabilitats?, com es pot tornar a una versió estable si es troba un error?
Totes aquestes preguntes es resolen en l’actualitat amb els repositoris de versions. Conceptualment, no són més que un dipòsit on es guarden totes les versions de tots els fitxers de manera ordenada, perquè qualsevol persona pugui consultar la versió més recent o una d’antiga, i un membre d’un equip pugui també guardar els seus canvis en privat sense afectar tothom. Els més populars són SVN, Mercurial i Git. De fet, el concepte amb el qual treballen és molt similar, i cada cop es tendeix més a fer servir Git.
Aquests tres sistemes es basen en definir una sèrie de fitxers i carpetes que formen part d’un projecte, i guardar-los de manera centralitzada en un arxiu que es diu repositori. Com que està tot centralitzat es pot gestionar més fàcilment l’ús compartit. A més a més, els sistemes han de poder detectar cada cop que un usuari faci canvis. Aquests canvis, però, no es guarden automàticament sinó que són els usuaris els que decideixen quan tot està llest per enviar-ho al repositori. En aquest moment, l’usuari executa una sèrie d’ordres, depenent del protocol, i s’emmagatzemen no només les diferències dels fitxers actuals amb les versions del repositori, sinó també els comentaris que escrigui l’usuari. Aquestes petites notes serveixen per descriure d’una manera molt breu quina és la intenció dels canvis introduïts.
Vegem ara com fer servir el tipus de repositori més popular avui en dia: el Git. Primer cal descarregar Git d’internet, de la pàgina oficial: GIT Downloads. Cal fer una distinció entre Git i GUI, que veureu a la pàgina de descàrregues. Git és el protocol que controla totes les operacions amb el repositori. La GUI, o Graphical User Interface, és un programa que mostra una sèrie de pantalles per facilitar la comprensió a l’usuari del que està passant a cada moment. I és que molts usuaris no estan acostumats a treballar amb ordres i prefereixen veure gràficament les seves operacions. Treballar amb ordres, però, té múltiples avantatges:
- La primera és que per molt ben dissenyada que estigui una interfície, amb la pràctica escriure ordres és molt mes ràpid.
- La segona és que un és molt més conscient de què està passant. Cada proveïdor de programes de interfícies de Git té un llenguatge visual diferent, un disseny diferent i en general una usabilitat diferent. Però les ordres de Git són les mateixes en qualsevol entorn, i no es preveu que canviïn.
- Finalment, perquè és molt més fàcil treballar en remot. Connectar-se a una consola d’un ordinador al núvol és molt més senzill que carregar tot l’entorn gràfic i treballar remotament amb aquest. De fet, en moltes ocasions això no és ni possible, degut a les configuracions de l’equip o del sistema operatiu.
Per aquest motiu, a continuació veureu com fer servir Git amb línia d’ordres. El primer pas és crear un repositori. L’opció més senzilla és treballar amb el Git Bash. A Windows podeu utilitzar el vostre explorador d’arxius i fer clic amb el botó dret a la carpeta que contingui els arxius que voleu incloure en el repositori. De les opcions que apareixen, escolliu Git Bash here (en altres sistemes operatius, l’operació serà semblant). Us hauria de sortir una pantalla semblant a la de la figura figura. Si no us surt, repasseu la instal·lació de Git. Per veure tota la llista de possibles ordres i una petita descripció de què fan, podeu escriure l’ordre git i prémer la tecla Enter. La llista que us sortirà serà com la de la figura figura.


El primer cop que feu servir Git, no tindreu configurat el vostre usuari. No és estrictament necessari per treballar-hi, però és útil fer-ho un cop i ja deixar-ho fet. Per configurar el vostre nom, heu d’escriure l’ordre: git config —global user.name i el vostre nom entre cometes. Per exemple, pel meu nom queda de la següent manera: git config —global user.name “Rodrigo Pizarro”. Un cop escrita l’ordre només cal prémer la tecla Enter i el nom ja quedarà registrat. La vostra adreça electrònica la podeu configurar d’una manera molt similar, i és amb l’ordre git config —global user.email més l’adreça entre cometes. A la figura figura podeu veure com queda un exemple.

Com veieu, les ordres de Git consten de diferents parts. Per fer-les servir, cal escriure primer git, després l’acció que es vol executar, després opcionalment algun modificador assenyalat amb dos guions mitjans, seguit de la configuració de l’acció si cal, i finalment els valors que calguin.
En el cas de la configuració, l’acció és config, l’atribut opcional és global (perquè en aquest cas no és la configuració d’un projecte concret sinó de tots els projectes) i la configuració de l’acció és user.name. Per això l’ordre per configurar el nom queda: git config —global user.name “nom cognom”. Els valors estan entre cometes perquè és una manera senzilla de marcar que és tot allò que es troba dins de les cometes. Si no s’hi posessin, no seria fàcil entendre si és un nom i cognom o només és un nom i després hi ha algun paràmetre més o és un error.
A més d’una línia d’ordres que entén les ordres de Git, el Git Bash entén també les ordres d’UNIX. Si bé aquest curs no se centra en les ordres d’UNIX, és interessant saber que es poden fer servir i poden ser útils. Per exemple, l’ordre clear esborra totes les ordres de la pantalla, i us serveix per tenir una pantalla neta i organitzar-vos millor.
Repasseu les ordres disponibles. Tal com diu la descripció, l’ordre git init serveix per crear un repositori nou o per reinicialitzar-ne un d’existent. Aquesta acció crearà també una carpeta privada dins del directori que s’està versionant anomenada .git i que conté una estructura interna per mantenir la configuració del repositori. La descripció detallada dels continguts d’aquesta carpeta queda fora de l’abast d’aquest temari, però cal remarcar que els fitxers i directoris generats són necessaris i que esborrar-los o modificar-los pot causar problemes o fins i tot fer que deixi de funcionar el sistema. De fet, una manera simple de treure un repositori d’una carpeta és esborrant el directori .git. Per tant, simplement comprovant que el directori .git s’ha creat, ja podeu continuar.
Un cop creat el repositori, veureu també que la línia d’ordres inclou al final, en un blau clar, la indicació que és a la branca master, com veieu a la figura figura.

El concepte de les branques és senzill. Cada cop que algun membre d’un equip vol fer un desenvolupament i el vol guardar sense estar acabat, es crea una branca per a ell o ella i guarda la informació a la branca. D’aquesta manera, la informació queda ben guardada i no es molesta la resta de l’equip.
Un repositori en si mateix, però, no té cap utilitat. Un cop creat el que heu de fer és fer-lo servir per guardar dades. Per aconseguir-ho heu de seguir un procés en dues etapes:
- La primera és dir-li a Git que voleu que observi alguns directoris o fitxers.
- La segona és dir-li que voleu guardar l’estat en què es trobi.
Per aconseguir la primera etapa, dir-li a Git quins són els fitxers i directoris que formen part del projecte, heu de fer servir l’ordre git add i el fitxer o directori que voleu afegir al repositori. A la imatge veureu un exemple de com fer servir la comanda per afegir el directori actual. El directori actual se simbolitza amb un punt, i el directori pare amb dos punts seguits. Qualsevol subdirectori s’afegeix amb el nom de la carpeta. Per facilitar-vos la vida, podeu posar tots els fitxers necessaris en un directori i afegir-lo al repositori amb una única comanda. A la figura figura es mostra com afegir la carpeta actual.

La raó per la qual cal dir-li a Git quins són els fitxers i directoris necessaris és perquè molts projectes fan servir fitxers de configuració que depenen de l’entorn concret on s’està executant o programant. Si aquests fitxers s’afegissin a un repositori comú per a un equip, seria impossible treballar, perquè cada membre de l’equip hauria de canviar aquests fitxers cada cop que obtingués l’estat del repositori. D’aquesta manera, la manera de treballar és molt més senzilla, només s’afegeixen al repositori tots aquells fitxers i directoris que són comuns, i tot allò que depèn de l’entorn s’exclou. També s’exclouen totes les dependències i llibreries de tercers que calguin per fer a servir el projecte.
Aquesta situació és molt comuna en projectes complexos. Molts cops una llibreria desenvolupada per algú i distribuïda per internet ja fa la feina que es necessita, i per tant no cal reinventar la roda. És molt més senzill integrar la llibreria i fer servir les funcions dins del vostre projecte. Els problemes arriben quan la llibreria s’actualitza i pot deixar de ser compatible amb part del vostre projecte. També pot passar que alguns membres de l’equip vulguin provar versions diferents per veure els canvis o per qualsevol altre motiu. Si estiguessin dins del repositori es complicarien aquestes operacions. Finalment, quan un projecte creix, el seu repositori creix en la mateixa mesura, i alleugerir les operacions pot arribar a ser crític. Quan hi ha milers de fitxers en un repositori, les operacions es tornen més lentes i hi ha un impacte en l’espai ocupat en el disc dur.
La segon etapa per guardar els fitxers al repositori és fer servir l’ordre git commit. Per provar que aquesta ordre funciona, primer haureu de crear un fitxer de prova, que en aquest cas anomenarem exemple.txt i veureu què passa. El concepte de commit és guardar un estat actual al repositori. D’aquesta manera, es va treballant a base d’anar guardant els estats del projecte a mesura que es va progressant, i si algú detecta algun error o vol comprovar alguna cosa d’alguna versió anterior ho pot fer tornant a un estat anterior. La comanda està formada per les primeres paraules clau git commit, i després l’opció -m i un text per descriure què representa l’estat que s’està guardant.
Si només tenim dues o tres versions no hi ha problema per saber què representa cada versió. Però si tenim un projecte on treballen 30 persones durant mesos, serà impossible tenir un control mental de què conté cada versió. Per tant, serà imperatiu que treballeu amb uns criteris clars de com descriure cada versió i quins canvis aporta. Tant és així que Git no deixa fer un commit si no hi ha un comentari.
A la imatge figura es pot veure el resultat de fer un primer commit de la carpeta on esteu treballant.

En aquest cas hem posat un comentari d’exemple que diu que aquest és el primer commit. Com podeu veure, el sistema ens torna un missatge que informa que hi ha un fitxer que s’ha afegit i un fitxer que s’ha modificat. Lògicament, és el mateix fitxer.
Per comprovar el resultat i l’estat del sistema, podeu fer servir l’ordre git status. El resultat d’aquesta ordre és la branca en la qual esteu treballant actualment i també si queda algun canvi per enviar al repositori. A la imatge figura podeu veure com queda el resultat de git status a l’exemple, per exemple, si els fitxers s’han modificat o no s’han afegit al repositori.

Vegeu ara què passa si afegiu un parell de fitxers nous. Creeu dos fitxers anomenats segon.txt i tercer.txt i torneu a la consola de Git Bash. Torneu a fer l’ordre de git status. El resultat ha de ser el mateix que el de la figura figura.

En aquest cas, podeu veure que git status retorna que hi ha dos fitxers que no estan seguint, que són justament els fitxers que acabeu de crear. També us indica que per afegir els fitxers heu de fer servir l’ordre git add i el nom dels fitxers. Proveu ara d’afegir el segon fitxer. Ho podeu fer amb l’ordre git add ‘segon.txt’. Si després escriviu git status veureu que Git us indica que hi ha un fitxer amb canvis i que cal enviar-lo al repositori. També indica que hi ha un fitxer, tercer.txt, que no està afegit al repositori. A la figura figura es veu com hauria de quedar:

Ara, per guardar l’estat, heu de fer servir l’ordre git commit -m i el comentari entre cometes. En el moment en què feu el commit, l’estat quedarà guardat al repositori, i Git interpretarà que no queda res per fer. L’únic que no farà serà cap operació amb el fitxer tercer.txt, perquè interpreta que no és rellevant per al repositori. De fet, si després de fer el commit feu un git status, us sortirà que tot està actualitzat, però que hi ha un fitxer anomenat ‘tercer.txt’ al directori que no està afegit al repositori. El resultat de les dues operacions es pot veure a la figura figura.

De fet, tots els passos pels quals passen els fitxers tenen un nom tècnic concret. Els fitxers que hi ha al directori però no estan afegits al repositori (no s’ha fet cap ordre amb ells i es veuen en vermell quan es crida l’ordre git status) estan en un estat que es diu working copy. Un cop s’executa l’ordre git add per a un fitxer, passa a l’estat de staging area. En aquest moment, encara no està guardat al repositori, però Git està configurat per afegir-lo a la següent ordre git commit, i es veuen en verd amb l’ordre git status. Un cop executada l’ordre git commit per a un fitxer, el fitxer és al repositori. El fitxer tornarà a ser al working copy si es modifica; caldrà executar l’ordre git add per afegir-lo a staging area, i tornarà a estar sincronitzat amb el repositori quan es faci un git commit. Aquests últims passos són il·limitats sempre que no s’esborri un fitxer del repositori amb l’ordre corresponent.
Això sí, cal tenir present que això són els estats lògics pels quals passen els fitxers dins de Git. El fitxer en si mateix no pateix canvis. És a la carpeta on s’hagi creat i no es modifica ni es mou ni es destrueix amb les ordres de git add o git commit. Hi ha una ordre de Git, però, que sí que afecta realment els fitxers. L’ordre git rm més el nom del fitxer esborra el fitxer realment de la carpeta on estigui. Aquesta ordre és equivalent a esborrar el fitxer manualment a través del sistema operatiu. A la figura figura podeu veure un exemple de l’ordre, que també esborra el fitxer segon.txt de la carpeta.

La particularitat de l’ordre git rm és que aquest canvi encara no s’ha enviat al repositori. És a dir, el repositori ha anat guardant progressivament totes les versions a mesura que heu anat fent git commit, i per tant un canvi com esborrar un fitxer es guarda també quan s’executi l’ordre git commit. Per ser més precisos, el fitxer realment no s’esborra del repositori, sinó que s’indica que ja no hi ha aquell fitxer dins del projecte. Però si es volgués recuperar per qualsevol motiu, es podria fer amb l’ordre corresponent.
Repositoris i còpies de treball: resolució de conflictes
Una de les operacions més interessants de tot el sistema de control de versions i repositoris és la de tornar a una versió més antiga. Quan ens adonem que hi ha errors i que és més fàcil solucionar-los tornant enrere, Git ens ho facilita amb l’ordre git checkout. Aquesta ordre serveix per a posar estats del repositori al working copy, és a dir, posa fitxers que s’hagin guardat anteriorment dins del repositori a la carpeta del projecte que s’estigui versionant.
Per poder indicar a Git quina és la versió que es vol recuperar, cal indicar-li el codi de la versió. Aquest codi apareix amb l’ordre git log, al costat de cada commit. Aquests codis són autogenerats, i són prou llargs perquè sigui pràcticament impossible que hi hagi dos commits amb el mateix codi. Normalment amb els primers caràcters ja n’hi ha prou per identificar una versió, i amb aquests primers caràcters s’indica a l’ordre git checkout quina és la versió que es vol recuperar.
Exemple d'ús de l'ordre 'git checkout'
Feu ara un projecte amb tres versions dins del repositori, fent servir l’ordre git commit tres cops. Hauria de quedar com a la figura següent:

Ara feu servir l’ordre git checkout amb el codi de la segona versió. En aquest cas el codi per al segon commit del projecte d’exemple és d80b24. Cal també indicar quins fitxers es volen recuperar, i per recuperar-los tots es pot escriure un punt, com a la figura següent:

Però, què passa si algú vol guardar una versió que encara és inestable o no ha estat provada? Per això hi ha les branques: qualsevol persona pot crear una branca per guardar canvis sense afectar els altres; la idea és que després les branques o s’abandonen perquè ja es veu que no porten a cap millora, o bé es fusionen amb els canvis de la resta. Cada branca es pot anomenar de la manera que es vulgui, tot i que les bones pràctiques indiquen que el nom hauria de ser indicatiu d’allò en què s’està treballant. La branca principal es diu master, i es fa servir com la branca de la qual tothom està d’acord que és la més estable, i l’objectiu de totes les branques és que els canvis més rellevants acabin a la branca master.
Per crear una branca, podeu fer servir l’ordre git branch més el nom de la branca. Aquesta comanda crea una branca com una còpia de la branca on estigueu (és a dir, tot l’estat serà el mateix), però, no fa cap més canvi. Si voleu començar a treballar amb la nova branca, heu de fer git checkout més el nom de la branca. Per fer les dues operacions alhora, podeu fer servir l’ordre git checkout -b més el nom de la branca.
Una pràctica molt comuna és crear branques per cada funcionalitat nova que es vulgui afegir, i assignar-les a cada persona. D’aquesta manera, no s’entorpeix el treball de ningú. Per agregar tots els canvis en una versió comuna cal fusionar les branques. Per fer-ho, cal fer servir l’ordre git merge més el nom de la branca que volem fusionar. Aquesta ordre afegeix tots els canvis de la branca que es vol fusionar amb la branca pare. És a dir, una branca sempre es crea a partir d’una altra, que és la branca pare. Al fusionar-la, es veuen tots els canvis i, si no hi ha conflictes, s’afegeixen a la branca pare. Un conflicte és un canvi en un fitxer que no sigui evident de fusionar.
Exemple de conflictes a l'hora de fusionar branques
Tenim una branca que es diu pare i una branca que es diu fill i un fitxer que es diu A.txt, i dues persones en un equip. Suposeu que una persona edita el fitxer A.txt a la branca pare, fa commit i l’altra persona de l’equip també edita les mateixes parts del fitxer A.txt i també fa commit, però a la branca fill. Ara, al fusionar la branca fill el problema és que Git no sap escollir si ha de quedar-se amb la versió d’A.txt de la branca pare o de la branca fill.
Si no es resolen els conflictes, no es poden fusionar les branques. Per resoldre els conflictes hi ha moltes eines. Un exemple d’ordre per resoldre-ho és git mergetool —tool=kdiff3. Totes les eines funcionen de manera similar. Bàsicament ensenyen el canvi d’una branca, el canvi de l’altra, i cal que l’usuari decideixi quin canvi es converteix en definitiu.
Treballar amb repositoris adquireix una dimensió molt més important quan es treballa en equip. Quan membres d’un grup poden fer canvis i veure els canvis dels altres és quan s’entén la rellevància de tot el sistema de control de versions. Per organitzar-ho, hi ha molts serveis que ofereixen poder treballar amb repositoris Git allotjats al núvol. Vegeu ara com fer servir Github amb les ordres:
- El primer pas és crear-se un compte de Github per tenir un usuari.
- Un cop creat, podeu crear un repositori públic dins de Github per fer proves com veieu a la figura figura.
- Després, simplement cal seguir les ordres que s’indiquen a la pàgina i ja tindreu el repositori al vostre ordinador.

El concepte de serveis com Github és que ofereixen una sincronització dels repositoris, és a dir, qualsevol usuari que tingui accés a un repositori remot pot anar fent canvis en local a la seva màquina i, quan vegi que té una versió que vol compartir, pot enviar els canvis del seu repositori local al repositori remot. Per fer-ho, pot fer servir la comanda git push -u origin i la branca que vulgui pujar.
Per veure quins canvis han fet els altres, cal primer descarregar-los del servei en remot. Això es fa amb l’ordre git pull, i el que fa és fusionar el repositori local amb el repositori remot. D’aquesta manera, es podran veure tots els canvis que s’hagin fet en altres ordinadors i que s’hagin pujat al repositori remot.
En resum, treballar en projectes en equip és una feina complexa i que pot generar errors. Eines com els repositoris ens permeten no només tenir còpies de seguretat, sinó també una manera molt adequada per resoldre problemes i per no destorbar en la feina d’altres companys o companyes.