


Generació de serveis en xarxa
L’èxit de la xarxa global no ha estat només el desenvolupament d’una connectivitat barata i eficient. De fet, des dels inicis, a la connectivitat van afegir-se un nombre creixent d’aplicacions, suportades pels operadors d’Internet, que intentaven donar respostes genèriques a les necessitats d’intercanvi d’informació demandades pels usuaris.
Es tracta d’aplicacions distribuïdes més o menys especialitzades en algun tipus d’intercanvi, que segueixen el model client-servidor i que s’han popularitzat amb el nom de serveis de xarxa.
Podem dir que un servei de xarxa és aquell procés que executa una tasca predeterminada i ben definida dirigida a respondre les peticions concretes realitzades des de dispositius remots que actuen a mode de clients.
L’encert d’Internet ha estat l’estandardització d’un conjunt de serveis que podríem anomenar “bàsics”, que són capaços de suportar nous serveis de més alt nivell, garantint així la interoperabilitat de tots ells, sense necessitat de noves instal·lacions ni canvis de programari en cap dels clients que hagi d’utilitzar-los.
L’estandardització ha permès un creixement exponencial d’Internet amb una infraestructura comuna relativament reduïda i totalment descentralitzada en subxarxes propietat d’empreses i organitzacions sense ànim de lucre. D’aquí que Internet rebi el nom de xarxa de xarxes. Podeu veure un mapa que il·lustra l’estructura d’Internet a la figura.

La majoria dels serveis estàndards existeixen des dels inicis de la xarxa i responen a funcionalitats específiques d’intercanvi d’informació. Alguns poden facilitar l’ús de la pròpia xarxa com per exemple els serveis de sistemes de noms de domini anomenats també serveis DNS que permeten obtenir les adreces IP associades a un nom de domini concret, o com el servei de sincronització horària que aconsegueix mantenir en hora els dispositius que ho sol·licitin. D’altres serveis permeten que diferents usuaris intercanviïn informació, com ara els serveis de correu electrònic, els fòrums o els serveis de xat. Internet també disposa de serveis per obtenir recursos emmagatzemats en línia. Ens referim als serveis d’aplicacions web o als serveis FTP que permeten gestionar l’intercanvi de fitxers. Existeixen també serveis prou oberts com ara telnet sense funcionalitat específica definida. De fet el servei emula una consola de text a través de la qual el client pot rebre missatges i enviar comandes que seran executades remotament en el servidor.
Els serveis d’aplicacions web utilitzen tecnologies específiques, com ara el protocol de comunicació HTTP, el llenguatge HTML, etc.
Actualment telnet està en desús en favor dels serveis d’aplicacions web, perquè disposen de bones interfícies gràfiques, d’un temps de resposta eficient i de la possibilitat de realitzar crides realment complexes, cosa que els ha permès transformar-se en l’eina base en la qual fer créixer altres serveis de nivell més alt que puguin adaptar-se a les limitacions que la tecnologia implicada imposa.
Avui trobem molts serveis basats en les aplicacions web, perquè així s’asseguren l’accés de qualsevol client que disposi d’un navegador. Tots els cercadors ofereixen serveis d’indexació i cerca basats en web. De forma similar molts llocs i plataformes web enriqueixen la seva potencialitat amb xats o fòrums basats també en aquestes tecnologies. Les tecnologies web són tan versàtils que darrerament s’està popularitzant la implementació de serveis que fan servir HTTP com a protocol de transferència i els llenguatges associats a la tecnologia web, com ara XML, per donar estructura a la informació transmesa.
Serveis i protocols estàndards
D’entre la gran quantitat de serveis d’Internet destacarem, per la seva importància, 3 serveis que sens dubte han marcat i encara marquen l’evolució de la xarxa de xarxes. Per ordre d’importància són el servei WWW, els serveis de correu electrònic i els serveis de transferència de fitxers. La importància esdevé sobretot per la utilització que se’ls dóna en el desenvolupament d’aplicacions més grans, ja sigui com a complements o com a suport base de la seva implementació.
Podeu trobar una llista de tots els documents RFC existents a http://www.ietf.org/download/rfc-index.txt
La documentació que descriu els serveis estàndards d’Internet és aprovada i publicada per un organisme anomenat IETF (Internet Engineering Task Force) format per voluntaris que discuteixen i regulen totes les regles i missatges utilitzats a Internet. La documentació estàndard s’identifica mitjançant les sigles RFC (Request For Comments) seguides d’un valor numèric únic per a cada especificació. Per exemple, el format dels missatges de correu electrònic es defineixen al document anomenat RFC-2822, mentre que el protocol que regula la consulta i gestió dels missatges arribats a les bústies dels destinataris és el RFC-1939.
Només el compliment de la documentació estàndard assegura la compatibilitat entre clients i servidors i la plena interoperativitat de la xarxa.
Servei de transferència de fitxers
Aquest servei, tal com indica el seu nom, permet gestionar la transferència de fitxers entre dos llocs situats en diferents dispositius. El protocol estàndard utilitzat aquí és l’anomenat FTP (File Transfer Protocol) que es troba especificat al document RFC-959. El protocol corre sobre TCP. Es basa en un model client-servidor i contempla un conjunt de comandes que permetran al client gestionar un sistema de fitxers remot. El protocol contempla comandes a validar i autenticar, per demanar informació referent al sistema de fitxers controlat pel servidor, per fer peticions de modificació del sistema de fitxers remot o per iniciar una transferència d’un fitxer en qualsevol de les dues direccions possibles. L’especificació descriu també els paràmetres obligatoris i opcionals de les comandes, la seva funcionalitat i les possibles respostes que es poden esperar dels servidors.
En general podem dir que se segueix el patró petició-resposta de la majoria d’aplicacions client-servidor. En aquest cas les peticions són les comandes que el client envia i les respostes les genera el servidor associant un codi i un missatge que informa de si la comanda ha tingut o no èxit.
Cal tenir en compte, però, que algunes comandes, a més de la resposta, requeriran un traspàs extra d’informació que pot arribar a ser força considerable (imagineu la transferència d’un fitxer gran). També cal considerar que les comandes i les respostes associades s’envien sempre en forma de cadenes de caràcters, però les dades extres procedents de fitxers poden tenir una gran varietat de formats. Finalment cal tenir en compte que els tractaments usats per enviar gran quantitat d’informació poden resultar poc eficients en aquells casos que sigui necessari fer enviaments curts de forma puntual.
Són arguments amb els quals el protocol justifica la raó per la qual FTP estableix l’ús de canals de comunicació diferents pel tractament de les comandes pròpies del protocol i per la transferència d’informació extra derivada de la resolució d’algunes d’aquestes comandes (vegeu la figura).

El canal usat pel diàleg comandes-respostes s’anomena també canal de control. Es tracta d’una connexió que romandrà oberta mentre el client es trobi connectat. Per contra el canal de dades és temporal, només es crearà quan sigui necessari iniciar una transferència i es tancarà automàticament en el moment en què totes les dades hagin estat transmeses.
El servidor acostuma a fer servir el port 21 pel canal de control. Pel canal de dades, en canvi, el protocol dóna la possibilitat de treballar en dos possibles modes que anomenen respectivament mode actiu i mode passiu. El mode actiu preveu que el client indiqui al servidor l’adreça IP i el port en el qual desitja iniciar la transferència i sigui el servidor l’encarregat de fer la connexió (vegeu la figura). En canvi el mode passiu implica que el client sol·licita al servidor les dades de connexió, amb la resposta del servidor serà el client l’encarregat de fer la connexió (vegeu la figura).


És important entendre la seqüència de cada mode si hem d’implementar el servei ja que el bon funcionament dependrà de la correcta coordinació entre client i servidor. Fixeu-vos que el client, abans de realitzar una comanda que requereixi transferència de dades, indicarà al servidor el mode amb el qual vol treballar. Només un cop finalitzada la petició del mode i amb el canal de dades creat, el client demanarà l’execució de la comanda. En cas de fer la petició d’una comanda que requereixi transferència sense demanar el mode (passiu o actiu) el servidor enviarà una resposta d’error amb el codi 425.
L’ús de connexions actives i passives permet gestionar la còpia entre dos servidors des d’un client. Només caldrà que el client demani un connexió passiva a un dels servidors. Això li farà arribar al client la IP i el port que el servidor estarà preparant per a la connexió. Amb la IP i el port rebut indicarà al segon servidor que desitja un connexió activa, la qual cosa farà que el segon servidor es connecti al primer. Finalment el client enviarà una comanda a cada servidor per indicar a l’un que ha d’iniciar la transferència del fitxer desitjat i a l’altre que ha d’emmagatzemar les dades rebudes.
Les comandes FTP són cadenes de text que simbolitzen el nom d’una operació i poden anar seguides dels paràmetres que la comanda necessiti. Els paràmetres se separen amb comes. La comanda es finalitza i s’envia amb un final de línia per tal que el servidor detecti el final de la petició. Les respostes segueixen el mateix format de text. El servidor envia una línia de text en la qual la primera paraula serà un codi numèric de 3 xifres seguit d’una cadena informativa.
Així per exemple, en sol·licitar la connexió inicial al servei del port 21, el servidor respondrà amb el codi 220 indicant que cal que ens autentiquem. FTP disposa de les comande user <nom_suauri> i pass <contrasenya> per poder realitzar l’autenticació. El codi 230 ens informarà que la validació del nom i contrasenya de l’usuari ha tingut èxit o, en cas contrari, arribarà el valor 530.
Els servidors FTP solen donar accés a una zona limitada del sistema de fitxers i acostumen a treballar amb els permisos propis del sistema operatiu, executant les comandes com l’usuari autenticat. Tot i així, el servidor pot mantenir també un sistema de permisos propi i decidir el que cada usuari pot fer o no.
Les comandes FTP ens ajuden a moure’ns pel sistema de fitxers remot, obtenir informació, transferir fitxers d’una banda a l’altre, eliminar-los, reanomenar-los, crear nous directoris, etc. A la taula taula trobareu una relació de les principals comandes.
| Comanda | Paràmetres | Acció |
|---|---|---|
| PWD | - | Mostra el nom del directori actual |
| CWD | nom_directori | Canvia al directori indicat en el paràmetre |
| CDUP | - | Canvia al directori pare |
| PORT | bytte_1_IP, byte_2_IP, byte_3_IP, byte_4_IP, byte_1_port, byte_2_port | Demana iniciar una transferència de dades en mode actiu a la IP i port indicats. Tant la IP com el port s’expressen com a cadenes de bytes |
| PASV | - | Demana iniciar una transferència de dades en mode passiu. Si tot va bé, es rebrà una resposta amb el codi 227 que indicarà la IP i port de connexió seguint el format (n1, n2, n3, n4, n5, n6) i que indicarà els 4 bytes de la IP i el dos del port |
| NLST | - | Envia pel canal de dades la llista de noms dels fitxers continguts al directori actual |
| LIST | - | Envia pel canal de dades la llista de fitxers continguts al directori actual i informa dels seus atributs |
| STOR | nom_fitxer | Emmagatzemarà les dades rebudes a través del canal de dades en un fitxer que anomenarà com indica el paràmetre |
| STOU | - | Emmagatzemarà les dades rebudes a través del canal de dades en un fitxer que anomenarà automàticament de forma única |
| APPE | nom_fitxer | Emmagatzemarà les dades rebudes al final d’un fitxer existent anomenat com indica el paràmetre |
| RETR | nom fitxer remot | Envia pel canal de dades el fitxer remot indicat per paràmetre |
| ABOR | - | Interromp la transferència en curs |
| DELE | nom_fitxer | Elimina el fitxer indicat pel paràmetre |
| MKD | nom_directori | Crea un nou directori situat al directori actual amb el nom del paràmetre |
| QUIT | - | Es demana abandonar el servei i tancar la connexió |
Serveis de correu electrònic
Quan parlem de serveis de correu electrònic, bàsicament ens referim a dos serveis diferents que col·laboren per aconseguir transmetre un missatge digital des del dispositiu de l’autor (remitent) al dispositiu del destinatari. Autors i destinataris són particulars que no mantenen el seu dispositiu permanentment obert i connectat, cosa que podria impedir la recepció si el dispositiu destinatari es trobés desconnectat en el moment de la transmissió. La solució passa per emmagatzemar els missatges en dispositius als quals s’hi pugui accedir des del destinatari per acabar de realitzar la transmissió. Fent un símil amb la vida real, els dispositius d’emmagatzematge s’anomenen bústies de correu electrònic. Cada destinatari ha de tenir una bústia diferenciada en la qual trobar només els seus missatges.
La transmissió efectiva dels missatges electrònics s’aconseguirà doncs realitzant una transmissió des del dispositiu de l’autor fins a la bústia del destinatari, en una primera fase, i des de la bústia fins al dispositiu del destinatari en una segona. La primera fase dóna lloc al servei de transferència de missatges. La segona al servei d’accés a les bústies i recepció del contingut.
El format del missatge juga un paper fonamental en l’automatització d’ambdós serveis. Es troba especificat al document RFC-2822, en el qual s’indica que els missatges de correu electrònic es composaran de dues parts, la capçalera de caràcter obligatori i el cos del missatge de caràcter opcional.
Format del missatge de correu electrònic
La capçalera conté la informació que ajudarà a automatitzar la transmissió. De fet, seria equivalent a la informació que en una carta postal se situa en el sobre, nom i adreça del destinatari, nom i adreça del remitent, etc. En la versió electrònica, la informació es troba estructurada en un conjunt de camps específics, organitzats com a parelles nom-valor.
El cos del missatge conté només la informació que el remitent vol fer arribar al destinatari. Seria doncs l’equivalent a l’escrit que trobem dins del sobre en una carta postal.
A la taula trobareu els principals camps de capçalera definits a l’RFC-2822.
| Nom | Funció |
|---|---|
| Date | Informa de la data en la qual s’ha enviat el missatge. La data presenta la forma: DD MMM AAAA hh:mm:ss <latex>\pm</latex>hhmm on DD són els dos dígits del dia del mes, MMM l’abreviació de tres lletres del nom del mes en anglès, AAAA, els 4 dígits de l’any, hh:mm:ss l’hora i <latex>\pm</latex>hhmm, 4 dígits precedits d’un signe més o un signe menys indicant la diferència horària respecte l’hora UTC (hh són hores i mm, minuts) |
| From | Indica l’adreça del remitent i opcionalment també el seu nom. Si s’indica el nom, l’adreça es delimitarà amb els símbols “menor que” < marcant l’inici i “major que” > el final |
| To | Informa de l’adreça del destinatari (o adreces si n’hi ha més d’una) i opcionalment també del seu nom. Segueix el mateix format que el camp From. Si hi ha més d’un destinatari se separaran usant el símbol coma ”,” |
| Cc | Especifica nom i adreça de destinataris als quals se li ha d’enviar una còpia del missatge. A la pràctica l’enviament és idèntic al dels destinataris, però permet informar als usuaris del servei que aquests no són els destinataris. És un camp opcional |
| Bcc | Aporta la mateixa informació que Cc, però el valor d’aquest camp mai es farà arribar als usuaris. Per això aquest camp s’anomena còpia oculta (blind carbon copy en anglès). És tracta d’un camp opcional |
| Subject | És un text explicatiu que resumeix el contingut del missatge. És opcional i té per objectiu informar al destinatari del que es trobarà quan llegeixi el contingut del missatge |
| Reply-to | Permet indicar l’adreça a la qual cal contestar el correu en cas que no coincideixi amb l’adreça expressada al camp From |
Entenem per espai en blanc qualsevol caràcter que representin un o més espais tipogràfics de comportament horitzontal o vertical. Així, són espais en blanc l’espai, el tabulador, el salt de línia, etc.
Els camps de la capçalera separen les parelles nom-valor intercalant el caràcter dos punts ”:”. El nom del camp no pot contenir espais en blanc, ni abans, ni després. Els valors, en canvi, sí que poden contenir espais en blanc en qualsevol posició. En general cada camp ocuparà una única línia, però si convé podem fer que ocupin diverses línies posant un espai després de cada salt de línia. Un salt de línia sense cap espai, significarà que comença un nou camp de capçalera.
Exemples de camps de capçalera
El següent camp:
Date: 29 Apr 2014 19:30:09 +0200 From: your@domain.org
és equivalent a:
Date: 29 Apr 2014 19:30:09 +0200 From: your@ domain.org
El cos del missatge se separarà de la capçalera afegint una línia de text buida. Els missatges de correu electrònic fan servir com a salts de línia la combinació de dos caràcter especials CR (de codi ASCII 10) i CF (codi ASCII 13), per tant entre el darrer camp de la capçalera i l’inici del missatge trobarem sempre 4 bytes corresponents a la seqüència CR-LF-CR-LF.
Dins del missatge poden haver-hi tants salts de línia seguits com sigui necessari. Només el primer parell de salts separen la capçalera del missatge. Veieu l’exemple:
Exemples de missatge de correu electrònic
Date: 10 Jun 2013 18:01:23 +0200 From: professor@ioc.cat To: El Teu Nom <your@domain.org>, Més Gent <another@domain.org> Subject: Exemple que il·lustra el format d'un correu electrònic Cc: El Cap <boss@domain.org> Bcc: El Cap Major <big_boss@domain.org> Aquest és un exemple en el qual es pot veure el format en text pla d'un correu electrònic, tal com s'envia per la xarxa. A dalt podeu veure la capçalera i aquí teniu el cos, separat de la capçalera amb un salt de línia. Cordialment El Professor
Adjunció de fitxers i format HTML en el cos del missatge
L’enviament de missatges de text presenta moltes limitacions. Sovint tenim dades a enviar que es troben en altres fitxers, en formats diversos o volem expressar èmfasi al nostre escrit afegint recursos estilístics que l’ajudin a llegir i interpretar. Aquesta limitació, va forçar a crear un sistema independent capaç de suportar qualsevol dada en qualsevol format. El resultat es va materialitzar en l’estàndard que es coneix com a MIME (Multipurpose Internet Mail Extension). Aquest estàndard identifica i anomena tots els tipus de formats existents, per tal que puguin identificar-se sense confusió usant el nom.
Podeu trobar una llista dels tipus MIME a wikipedia.
L’especificació de MIME no modifica l’estàndard RFC-2822 sinó que l’estén. Bàsicament afegeix nous camps de capçalera que ajudaran a identificar el tipus de contingut, el joc de caràcters usat quan es tracti de text, el tipus de codificació utilitzada per enviar la informació quan aquesta s’enviï codificada, etc. Així, quan el client de correu rebi un missatge amb una camp a la capçalera especificant “Content-Type: text/html”, ja sabrà que el cos del missatge es trobarà formatat usant HTML i podrà fer-ne una interpretació correcta.
L’extensió MIME, a més, ofereix una forma de poder enviar informació de diversos tipus dins d’un mateix missatge. Es tracta de la mateixa fórmula que permet l’adjunció de fitxers dins un missatge. MIME preveu un tipus de contingut especial anomenat multipart, compost de blocs d’informació de diferents tipus (els fitxers a adjuntar), els quals es concatenaran l’un darrere l’altre formant el cos del missatge. Cada bloc estarà format per una capçalera de bloc en la qual es descriurà el tipus de contingut i l’altra informació necessària per interpretar el bloc. Entre bloc i bloc, MIME preveu intercalar una cadena de text única que faci de separador i que s’anomena frontera o boundary. Els blocs es trobaran delimitats per davant i per darrera per dos guionets ”–” seguits de la cadena frontera. La darrera cadena frontera haurà de finalitzar també amb dos guionets (a més dels dos que la precediran) per tal de reconèixer el final del cos.
La cadena frontera pot ser qualsevol valor. Cal assegurar, això sí, que es tracta d’un valor únic i que no serà possible trobar la mateixa seqüència repetida entre les dades. Per tal que el servidor sàpiga quina cadena farem servir com a frontera, inclourem el valor de la mateixa com a extensió del camp Content-Type, sota el nom de boundary.
Exemples de missatge de correu electrònic amb fitxers adjunts
Date: 10 Jun 2013 18:01:23 +0200 From: professor@ioc.cat To: El Teu Nom <your@domain.org>, Més Gent <another@domain.org> Subject: Exemple que il·lustra el format d'un correu electrònic amb fitxers adjunts Cc: El Cap <boss@domain.org> Bcc: El Cap Major <big_boss@domain.org> Content-Type: multipart/mixed; boundary=_123_abc_987_zyx_ --_123_abc_987_zyx_ Content-Type: text/html Aquest és un exemple en el qual es pot veure el <em>format d'un correu electrònic</em> que segueix l'especificació MIME per donar format d'estil al seu missatge i per adjuntar fitxers independents. El tipus del missatge ha de ser <i>multipart/mixed</i>. Després cada bloc contindrà una capçalera pròpia en la qual s'indicarà el tipus de cada fitxer i també el del missatge. Cordialment El Professor --_123_abc_987_zyx_ Content-Type: image/gif; name="ioc_logo.gif" Content-Transfer-Encoding: base64 PGh0bWw+CiAgPGhlYWQ+CiAgPC9oZWFkPgogIDxib2R5PgogICAgPHA+VGhpcyBpcyB0aGUg Ym9keSBvZiB0aGUgbWVzc2FnZS48L3A+CiAgPC9ib2R5Pgo8L2h0bWw+Cg== --_123_abc_987_zyx_--
Per tal d’assegurar la compatibilitat de la transmissió, els fitxers que no siguin de caràcter, normalment es codifiquen usant el mecanisme anomenat base64 que transforma la informació binària en seqüències de 7 bits (codi ASCII).
Servei de transmissió de missatges
És el servei encarregat de transmetre els missatges de correu electrònic. Fa servir el protocol anomenat SMTP (Simple Mail Transfer Protocol), especificat en el document estàndard RFC-2821. El port assignat a aquest servei sol ser el 25. Generalment, cada usuari d’Internet fa servir un únic servidor SMTP que sol coincidir amb el proveïdor que li subministra la bústia de correu electrònic.
Per dur a terme la transmissió d’un missatge entren en joc 3 actors diferents, l’usuari remitent, un servidor de correus (habitualment el del proveïdor del remitent) i el proveïdor de correus del destinatari. El remitent usarà un emissor SMPT (inclòs en el client de correus local) per enviar el missatge al servidor SMTP del seu proveïdor (receptor). En ser rebut, serà reenviat als proveïdors de correus als quals estiguin subscrits els destinataris. El servidor del destinatari es reconeix analitzant la part dreta de la seva adreça de correu, la que es troba a continuació del símbol @. Aquesta part de l’adreça es pot resoldre contra un servidor DNS especificant que es tracta de registres MX. Quan els servidors SMPT reben correus adreçats als seus abonats analitzen la part esquerra de l’adreça, la qual els indicarà el nom de la bústia en la qual caldrà emmagatzemar-los. Mireu l’esquema de la figura.

La connexió entre client i servidor es realitza també a través de comandes de text acabades amb un salt de línia. Cada comanda es contesta amb una resposta composta d’un codi de 3 xifres i una frase informativa que acabarà també amb un salt de línia. Quan la resposta a una comanda ocupi més d’una línia caldrà incloure un guió entre el codi i la frase excepte en la darrera línia que hi apareixerà un espai, tal com es mostra al patró que segueix:
CODI-frase1 CODI-frase2 CODI frase3
A la taula trobareu les principals comandes dels protocol SMTP.
| Comanda | Paràmetres | Descripció |
|---|---|---|
| HELO | Nom domini | Cal usar-la sempre a l’inici de la connexió i informa al servidor del domini des del qual el client s’està connectant |
| MAIL FROM | Adreça del remitent | Informa al servidor de l’adreça del que envia el missatge |
| DATA | Missatge de correu electrònic (capçaleres i cos) a enviar | Per finalitzar el missatge caldrà escriure la seqüència formada per un salt de línia un punt i un altre salt de línia |
| QUIT | - | Indica al servidor que l’emissor vol tancar la connexió |
Exemple que il·lustra un connexió entre un client i un servidor SMTP
Comença el servidor
220 smtp.xtec.cat SMTP server ready HELO ioc.xtec.cat 250 Hello, please to meet you MAIL FROM: <ioc@xtec.cat> 250 Ok RCPT TO: <destinatari1@undomini.org> 250 Ok RCPT TO: <destinatari2@unaltredomini.org> 250 Ok DATA 354 End data with <CR><LF>.<CR><LF> Date: 10 Jun 2013 18:01:23 +0200 From: professor@ioc.cat To: El Teu Nom <your@domain.org>, Més Gent <another@domain.org> Subject: Exemple que il·lustra el format d'un correu electrònic Cc: El Cap <boss@domain.org> Bcc: El Cap Major <big_boss@domain.org> Aquest és un exemple en el qual es pot veure el format en text pla d'un correu electrònic, tal com s'envia per la xarxa. A dalt podeu veure la capçalera i aquí teniu el cos, separat de la capçalera amb un salt de línia. Cordialment, El Professor . 250 Ok: Mail accepted quit 221 Bye
Servei d'accés a les bústies d'usuari
Aquest servei s’encarrega només de gestionar l’accés a les bústies i la recepció dels correus emmagatzemats. Actualment molts proveïdors ofereixen accés web a través d’una aplicació que retorna les dades en una pàgina HTML i que no necessita que el servidor es descarregui cada correu. Tot i així continuen vigents com a alternativa les aplicacions d’accés a les bústies amb l’objectiu de fer una descàrrega local. El protocol més popular d’aquestes característiques és l’anomenat POP3. En aquest servei només intervenen l’usuari abonat i el proveïdor del servei POP3. Mireu l’esquema de la figura.

Aquest servei preveu sempre l’autenticació en realitzar la connexió, ja que cada usuari ha de poder accedir només a la seva bústia. L’autenticació es realitzarà amb les comandes USER i PASS. Un cop l’usuari aconsegueixi autenticar-se, podrà consultar el nombre de missatges que té a la bústia. El servei POP3 no sap diferenciar entre un missatge llegit i un no llegit, per això aquesta informació ha de córrer a càrrec del client que mantindrà una referència per poder fer-ne la distinció. Tot i així, val a dir que POP3 no està pensat per mantenir a les bústies un gran volum de missatges i per tant és convenient que l’usuari es descarregui el correu en local i l’esborri del servidor.
L’usuari podrà també demanar una llista dels missatges de la bústia usant la comanda LIST. Això retornarà un identificador numèric per a cada missatge juntament amb el nombre de bytes que ocupen. La comanda TOP permetrà rebre la capçalera d’un missatge i el nombre de línies especificat per paràmetre i la comanda RETR permetrà recuperar tot el missatge sencer. A més, amb la comanda DELE aconseguirem eliminar el missatge indicat de la bústia.
Les respostes del servidor començaran sempre per la seqüència +OK si la comanda s’ha executat amb èxit o -ERR si hi ha hagut algun error. Generalment les respostes contindran també frases informatives per l’usuari.
Exemple d'un diàleg entre client i servidor de POP3
+OK POP3 server ready. USER alumne +OK password required. Send PASS command. PASS 1234 +OK alumne you has 3 messages LIST +OK 3 messages 1 513 2 1825 3 1019 . TOP 1 0 +OK Top of message (1) whith 0 lines of body Date: 10 Jun 2013 18:01:23 +0200 From: professor@ioc.cat To: El Teu Nom <your@domain.org>, Més Gent <another@domain.org> Subject: Exemple que il·lustra el format d'un correu electrònic Cc: El Cap <boss@domain.org> Bcc: El Cap Major <big_boss@domain.org> . RETR 1 +OK 1801 octets Date: 10 Jun 2013 18:01:23 +0200 From: professor@ioc.cat To: El Teu Nom <your@domain.org>, Més Gent <another@domain.org> Subject: Exemple que il·lustra el format d'un correu electrònic Cc: El Cap <boss@domain.org> Bcc: El Cap Major <big_boss@domain.org> Aquest és un exemple en el qual es pot veure el format en text pla d'un correu electrònic, tal com s'envia per la xarxa. A dalt podeu veure la capçalera i aquí teniu el cos, separat de la capçalera amb un salt de línia. Cordialment El Professor . DELE 1 +OK message (1) deleted QUIT +OK bye alumne. POP3 server signing off.
Implementació del client usant la biblioteca JavaMail
És probable que ja tingueu la versió J2EE activada, però si no fos així, podeu consultar l’annex Instal·lació de J2EE 7 per saber com poder activar-la.
Per implementar clients de correu Java posa a la nostra disposició la biblioteca JavaMail. La biblioteca només es troba disponible si usem la plataforma J2EE que, tal com sabeu, és una extensió del JDK. JavaMail és una biblioteca que treballa sobre la majoria de protocols, ja sigui de transmissió o d’accés a les bústies. Per descomptat reconeix els protocols SMTP i POP3 i aconsegueix una programació força neta en ambdues funcionalitats.
L’estructura de la biblioteca és de molt alt nivell i amb això aconsegueix independitzar la programació del protocol realment utilitzat. La classe Session contribueix a aquesta abstracció. Es tracta de la classe que dóna accés a un dels protocols disponibles i representa una sessió de correu oberta contra un proveïdor dels serveis de correu. La classe Session es configura a través de Properties ja que resulta una forma molt versàtil d’associar atributs i valors que es pot adaptar a gairebé qualsevol necessitat.
Exemple de configuració d'una sessió
Disposeu de la relació de propietats acceptades a: http://connector.sourceforge.net/doc-files/Properties.html
Si ens cal realitzar transferència de correus, Session treballarà amb una instància de la classe Transport. Aquesta és una classe abstracta materialitzada per una classe que s’adapta a un protocol concret. Per defecte, la biblioteca JavaMail suporta SMTPTransport, però el fet de treballar amb la classe abstracta permet en un futur incorporar noves classes. És important, doncs, que totes les instàncies que calgui crear estiguin declarades com a Transport si volem construir una aplicació escalable i de llarga durada.
Les classes de la jerarquia Transport bàsicament tenen la funcionalitat d’enviar missatges seguint el protocol que suportin i fent servir una instància oberta de Session. Per evitar crear instàncies temporals que ens puguin carregar la memòria, Transport té el mètode static send per aconseguir realitzar l’enviament sense haver de crear cap instància. Aquest mètode obre i tanca una connexió cada cop que l’invoquem.
Exemple d'enviament d'un missatge usant el mètode estàtic anomenat send
El mètode send accepta diversos paràmetres. Per defecte enviarà el missatge passant en el primer paràmetre les adreces incloses en el missatge, però també es pot especificar les adreces com a segon paràmetre i en aquest cas no es consultarà el missatge.
L’objecte de l’enviament, que haurem d’haver construït prèviament, és una instància de la classe Message, que és estesa per la classe MimeMessage. La classe Message és una classe abstracta que no podem instanciar. Usarem sempre la classe MimeMessage per instanciar l’objecte. MimeMessage suporta l’especificació MIME. És a dir, podem enviar missatges de contingut divers i adjuntar fitxers, d’acord amb aquesta especificació.
Aquesta classe disposa dels mètodes adequats per crear un missatge compatible amb l’especificació RFC-2822. Per exemple, disposa del mètode setFrom per afegir el remitent, dels mètodes setRecipient, setRecipients o addRecipient per afegir destinataris de qualsevol dels camps que el format permet (To, Cc o Bcc). Per evitar problemes de sintaxi, les dades de les adreces de correu dels paràmetres dels mètodes esmentats seran del tipus InternetAddress, una classe que representa una adreça de correu electrònic però que analitza la cadena passada i llança excepcions quan detecta incorreccions en la cadena.
Message disposa també d’altres mètodes d’entrada de dades com ara setSendDate, setSubject, setText o setReplyTo per facilitar la composició.
Exemple de creació d'un missatge de correu simple
Per instanciar el missatge cal passar-li una sessió per paràmetre en el constructor.
JavaMail també simplifica molt la creació de missatges MIME de tipus multipart, per exemple per adjuntar documents.
Exemple de creació d'un missatge de correu multipart
L’accés a la bústia de correu personal i la seva gestió s’aconsegueix treballant amb una instància d’ Store. La classe Store seria l’equivalent a Transport però pel procés d’accés a les bústies. Igual que Transport, és una classe que es materialitzarà amb extensions que implementin un protocol específic. Així trobem Pop3Store i IMAPStore. De forma semblant al que fèiem amb Transport, caldrà configurar la sessió indicant almenys el nom del host i el port si el servidor no utilitzés el port 110.
La classe Store representa la bústia remota i gestionarà la connexió puntual invocant el mètode connect, al qual caldrà passar-li per paràmetre el nom d’usuari i contrasenya per autenticar-se en el servidor. A partir d’un objecte Store aconseguirem un objecte Folder que representa una carpeta de la bústia. Cal explicar que POP3 no permet gestionar carpetes però altres protocols com ara IMAP4 si que ho fan. JavaMail és una biblioteca genèrica que ha d’adaptar-se a qualsevol protocol. Per això els correus es recullen sempre en una carpeta (objecte Folder).
Treballant amb el protocol Pop3, caldrà recupera la capeta usant el nom INBOX i seguidament obrir-la en mode de lectura o en mode d’escriptura. El mode de lectura no permetrà realitzar cap alteració de la bústia. En canvi el mode d’escriptura ens deixarà eliminar remotament els missatges.
Obtenció i obertura d'un objecte Folder
La carpeta ens permetrà recuperar els missatges invocant getMessages. També podrem fer una recuperació parcial o eliminar aquells missatges que indiquem. El missatges arriben com a objectes Message i, per tant, el seu accés al contingut i capçaleres resultarà ràpid o fàcil.
Servei WWW
Aquest servei, que normalment es troba associat al port 80, ha esdevingut el més important dels tres en els darrers anys, ja que ha acabat convertint-se en el servei que sustenta la comunicació i presentació de les dades d’una gran quantitat d’aplicacions distribuïdes i fins i tot de nous serveis que se sobreposen al primer. La gran versatilitat d’aquest servei ha acabat desbancant totalment altres serveis, com ara Telnet, pensats específicament per donar suport a l’execució d’aplicacions remotes i de serveis de nivell superior.
HTML és l’acrònim de Hipertext Makup Language (Llenguatge de marcatge d’hipertetx) i HTTP el de Hipertext Transfer Protocol (Protocol de transferència d’hipertext)
L’objectiu originari del servei web era només facilitar la difusió de documents tècnics entre la comunitat científica. Per aconseguir-ho van idear un llenguatge de presentació del contingut, que van anomenar HTML i un protocol per formalitzar la localització, la petició i la transferència de documents, l’HTTP. Cada lloc d’Internet podia disposar d’un servei web i controlar un conjunt limitat de documents HTML. L’usuari podia adreçar-se als diferents documents indicant el nom del servei i el nom del document. És el que ha acabat derivant en el que es coneix com a URL o Unified Resource Location. És a dir, un sistema per identificar de manera unívoca la localització dels documents. El protocol HTTP definia la manera d’interaccionar amb els serveis WWW a l’hora de requerir l’obtenció d’un document localitzat per mitjà de la seva URL. El servei rebia les peticions de l’usuari, cercava el document que acabava enviant de nou al client seguint les indicacions del protocol HTTP. A la banda client, la rebuda del contingut es realitzava amb una aplicació especial capaç d’interpretar el llenguatge HTML i de presentar-lo adequadament a l’usuari.
El llenguatge HTML deu el seu nom a l’ús de vincles específics que permetien adreçar d’altres documents i van acabar per batejar-se amb el nom d’hipervincles. La facilitat de passar d’un document a un altre, sense necessitat de fer noves peticions, va propiciar que les aplicacions encarregades de la visualització dels document formatats usant el metallenguatge de l’hipertext s’acabessin denominant navegadors.
La meteòrica evolució de l’HTML ha propiciat el canvi d’orientació del servei que n’ha determinat l’èxit rotund. Cap a les darreries del segle XX van començar a desenvolupar-se servidors de pàgines HTML que es generaven dinàmicament. El funcionament era ben simple, s’aprofitava la infraestructura dels serveis web, afegint una aplicació extra capaç d’interpretar les peticions del protocol HTTP i generar a partir d’aquesta una pàgina inexistent amb dades extretes d’una base de dades i formatar-les d’acord amb el llenguatge HTML per tal de ser enviades igual com s’enviaria un document HTML existent.
A ulls de l’usuari final no hi havia diferència entre ambdós sistemes. La petició o la visualització es realitzava des del mateix navegador i la presentació de les dades en fer servir també el mateix llenguatge que els documents estàtics resultava molt similar. Els servidors dinàmics de pàgines web podien coexistir amb els serveis antics de les pàgines estàtiques.
Els llenguatges de programació script són llenguatges de programació interpretats que no requereixen compilació.
Aviat va arribar la revolució a la banda dels navegadors. Van independitzar la visualització de determinats estils i formats de text especificant un sistema de creació d’estils de format anomenat CSS i van enriquir la interpretació del llenguatge de marques HTML, amb un llenguatge de programació script que permetia processar dades, atendre esdeveniments i modificar dinàmicament la pròpia estructura HTML, des de la banda del client, sense necessitat de baixar ni generar noves pàgines remotes. La combinació de tots aquest elements (Javascript, CSS i HTML) han permès la creació d’interfícies gràfiques d’usuari cada cop més potents i ràpides. Això ha fet decantar la balança a favor d’aquest servei a l’hora de desenvolupar aplicacions remotes en detriment de Telnet que només suportava formats textuals.
El protocol HTTP
El protocol HTTP és l’estàndard usat per establir la comunicació entre clients i servidors d’un servei web. Es troba especificat en el document RFC-2616. Es tracta d’un protocol que pot funcionar tant sobre UDP com sobre TCP, malgrat que la majoria d’implementacions es troben realitzades sobre TCP perquè ofereix una major qualitat.
El protocol defineix que la comunicació s’estructura sempre en dues fases, la petició i la resposta. Els clients realitzen les peticions i els servidors els tornen la resposta. D’acord amb el protocol, les peticions dels clients han de ser independents entre sí, de manera que no hauria de ser necessari que el servidor hagi de recordar les peticions realitzades amb anterioritat per poder respondre’n una. Si el servidor al qual el client envia la petició manté aixecat el servei WWW, generarà sempre una resposta amb les dades demanades o amb el motiu pel qual no s’ha pogut satisfer la demanda.
El protocol HTTP estableix que el final de línia es genera usant dos caràcters especials, el caràcter simbolitzat amb CR (carriage return) i el caràcter simbolitzat per LF (line feed). Respectivament responen als valors ASCII 10 i 13 i usant el llenguatge Java s’aconsegueixen també amb els literals ‘\r’ i ‘\n’.
Tant les peticions com les respostes són missatges de text estructurats en dos blocs i separats cada un d’ells per una salt de línia. El primer bloc s’anomena capçalera i el segon bloc cos. El cos del missatge és opcional, la capçalera és obligatòria. La mida de les capçaleres és variable. Per tant, cal enviar sempre els separadors CRLF per indicar al servidor que ja s’ha acabat la capçalera malgrat que el missatge no disposi de cos.
Les peticions HTTP contenen almenys una línia que explicita la petició del client, situada a la primera línia de capçalera del missatge. Opcionalment a la capçalera s’hi afegiran camps que podran matisar la resposta del servidor. El format del cos dependrà del tipus de petició. A la figura podeu veure un diagrama que esquematitza aquesta estructura.

La petició pròpiament dita, situada a la primera línia, contindrà sempre 3 elements separats entre sí per espais i acabarà amb un final de línia (CR-LF). La primera paraula coincidirà amb la denominació d’un dels possibles mètodes acceptats pel protocol: GET, HEAD, POST, PUT, DELETE, OPTIONS o TRACE. Cal escriure la denominació dels mètodes en majúscula. El segon element indicarà la ruta absoluta en la qual es troba el recurs demanat a la petició dins el servidor. La ruta s’expressarà com una URL, a la qual s’eliminarà la denominació del host o domini. El tercer element indicarà el protocol i la versió utilitzada. Normalment usarem sempre HTTP/1.1.
Exemple de petició HTTP
GET /index.html HTTP/1.1
Fixeu-vos com la URL no conté el nom del domini ni el port. Per fer la petició del recurs www.xtec.cat/index.html caldria connectar-nos a través d’un sòcol al port 80 de l’adreça www.xtec.cat i un cop connectats enviar la petició de l’exemple.
Tipus MIME
L’especificació dels tipus MIME defineix una forma única de denominar cada un dels diferents tipus de recursos que es poden localitzar o enviar a través Internet. Podeu trobar una llista dels tipus MIME a wikipedia.
Els camps suportats a la capçalera són comuns a tot els mètodes. Cada camp ocupa una línia de la capçalera i cal especificar-los escrivint el nom del camp i el valor del mateix, separats ambdós pel caràcter dos punts :. Cada parella camp valor donarà al servidor informació per poder elaborar una resposta ajustada al client peticionari. Per exemple, el camp Accept permet indicar quins tipus de documents acceptarà el client. El contingut d’aquest camp ha de seguir l’especificació dels tipus MIME. Cada tipus acceptat anirà separat per un caràcter coma ,. De forma semblant, el camp Accept-Language, permetrà informar de la llista de llenguatges acceptats pel client. D’aquesta manera, si el servidor disposa de recursos internacionalizats, podrà escollir l’adequat. El camp Host informa del nom del servidor o domini al qual el client està adreçant la petició, el camp User-Agent informarà del tipus de navegador que disposa el client, i amb el camp Cookie serà possible fer arribar al servidor les galetes (cookies) del client. Cal prestar atenció també als camps condicionals que permeten oferir una dada crítica que pugui fer decidir al servidor sobre si fer certa acció. Per exemple, el camp if-Modified-Since indicarà que només caldrà fer efectiva la petició si el recurs s’ha modificat posteriorment a la data indicada en el valor del camp.
Pel que fa a mètodes, els més usats són GET i PUT.
El mètode GET indica al servidor que el client demana la informació del recurs referenciada per la URL que es troba a continuació. És el mètode amb el que el navegador farà la petició quan escrivim directament l’adreça a la barra d’eines. El mètode GET no usa cos de missatge. Podeu provar aquesta sintaxi obrint una aplicació client de tipus Telnet, realitzant la connexió a un servei WWW d’algun servidor existent i seguidament, un cop connectat, fer algunes peticions per observar la resposta dels servidor. Recordeu que un cop introduïda la darrera línia de la capçalera cal confirmar amb un nou salt de línia per tal que el servidor sàpiga que no s’enviarà cap més dada i que ha de processar la petició rebuda.
Exemple de peticions GET fent servir un client Telnet
usuari:~$ telnet telnet> open ioc.xtec.cat 80 Trying 213.176.163.218... Connected to ioc.xtec.cat. Escape character is '^]'. GET /educacio/en/cicles-formatius HTTP/1.1 Host: ioc.xtec.cat Accept-Language: CA-ES, en-us
Obtindrem una resposta semblant a:
HTTP/1.1 200 OK
Date: Wed, 17 Jul 2013 00:30:08 GMT
Server: Apache/2.2.22 (Unix) PHP/5.3.10 mod_ssl/2.2.22 OpenSSL/0.9.7d
...
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en-gb" lang="en-gb" dir="ltr" >
<head>
<base href="http://ioc.xtec.cat/educacio/en/cicles-formatius" />
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
...
</body>
</html>
El mètode POST en canvi, serveix per enviar dades específiques al servidor en el cos del missatge. Aquest sol ser el mètode escollit per enviar les dades d’un formulari, per pujar un fitxer o per enviar qualsevol altra dada des del client al servidor. El mètode admet també els camps opcionals de la capçalera i el seu ús indica al servidor que haurà d’esperar dades al cos del missatge. Cal informar de la mida en bytes de les dades del cos fent servir el camp de la capçalera anomenat Content-Length i del tipus de contingut usant el camp Content-Type amb un dels tipus especificats per la norma MIME. Això permetrà al servidor saber quants bytes li cal esperar en el cos, un cop passat el salt de línia de separació posterior a la capçalera. Si les dades del cos provenen d’un formulari, aniran aparellades de dos en dos. El primer element de la parella representarà el nom del paràmetre i el segon el seu valor. Ambdós elements aniran separats per un símbol = i entre paràmetre i paràmetre (parella de nom valor) s’intercalarà un salt de línia (CR-LF). El tipus de contingut que caldrà especificar és application/x-www-form-urlencoded i s’ha de tenir en compte les limitacions dels caràcters especials com ara l’espai que caldrà canviar pel seu valor numèric (expressat en hexadecimal) precedit del caràcter %.
Exemple de petició HTTP amb el mètode POST
POST /cgibin/escolx.pgm HTTP/1.1 Accept:text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language:ca,es;q=0.8,en-US;q=0.6,en;q=0.4,en-GB;q=0.2 Content-Length:36 Content-Type:application/x-www-form-urlencoded Host:www.grec.cat GECART=protocol USUARI=dictioman
Cal explicar també que és possible enviar dades al servidor fent servir el mètode GET. L’especificació URL (Uniform Resource Locator) preveu afegir immediatament després de la ruta que identifiqui un recurs en una domini, el símbol ? seguit de la concatenació de les parelles de paràmetres (nom valor) separades per el símbol &. Per tant, usant el mètode GET, l’exemple anterior hauríem d’escriure’l:
Exemple de petició HTTP amb el mètode GET i enviament de dades
GET /cgibin/escolx.pgm?GECART=protocol&USUARI=dictioman HTTP/1.1 Accept:text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language:ca,es;q=0.8,en-US;q=0.6,en;q=0.4,en-GB;q=0.2 Content-Length:36 Content-Type:application/x-www-form-urlencoded Host:www.grec.cat
Trobareu més informació sobre el tipus MIME multipart al subapartat anomenat Serveis de correu electrònic de l’apartat Generació de serveis en xarxa.
Com a darrera característica del mètode POST, cal comentar que MIME preveu un tipus de dada especial anomenat multipart per poder concatenar gran quantitat d’informació de diversos tipus provinent de diferents fonts. La informació s’organitza en blocs i és possible especificar el tipus de cada bloc.
Malgrat que no és exclusiu, aquest sistema sol fer-se servir per enviar gran quantitat de dades recollides des d’un formulari HTML o per enviar fitxers des del client al servidor. Els formularis HTML associen un valor a un paràmetre, però si es tracta d’una interfície per seleccionar un fitxer entraran en joc 3 elements: el nom del paràmetre, el nom del fitxer i el seu contingut. En aquests casos es preveu l’ús de del camp Content-Disposition amb el valor form-data i enriquit amb els complements name i opcionalment filename. El cos de cada bloc es destinarà al valor. Heu de tenir en compte que aquí no es barregen diferents tipus de contingut, de manera que si un valor és molt llarg i necessita definir-se com a multipart, la resta de valors també es formataran de la mateixa manera. Un exemple ens ho clarificarà:
Exemple de petició HTTP amb el mètode POST usant el tipus MIME multipart
En el següent exemple s’envia al recurs /copy/copier tres fitxers. Un fitxer de text pla anomenat res.txt, una imatge anomenada logo.jpg que s’ha codificat usant l’algoritme Base64 que transforma qualsevol seqüència de bytes en una tira de caràcters alfanumèrics, i un HTML anomenat hola.html. A més s’envien les dades d’un camp simple anomenat overwrite que pren un valor lògic.
Observeu que els paràmetres que enriqueixen els camps de la capçalera són parelles de nom valor separades pel símbol = i entre elles pel símbol ;.
POST /copy/copier HTTP/1.1 Accept:text/html,application/xhtml+xml,application/xml Accept-Language:ca,es, en-US, en, en-GB Content-Type:multipart/mixed; boundary=78942734hdfkipiriepiryewi7979rb213cxzb Host:www.securityCopy.com --78942734hdfkipiriepiryewi7979rb213cxzb Content-Disposition:form-data; name="file1"; filename="res.txt" Content-Type: text/plain Aquest és el contingut del fitxer res.txt --78942734hdfkipiriepiryewi7979rb213cxzb Content-Disposition:form-data; name="file2"; filename="logo.jpg" Content-Type: image/jpg Content-Transfer-Encoding: base64 PGh0bWw+CiAgPGhlYWQ+CiAgPC9oZWFkPgogIDxib2R5PgogICAgPHA+VGhpcyBpcyB0aGUg Ym9keSBvZiB0aGUgbWVzc2FnZS48L3A+CiAgPC9ib2R5Pgo8L2h0bWw+Cg== --78942734hdfkipiriepiryewi7979rb213cxzb Content-Disposition:form-data; name="file3"; filename="hola.html" Content-Type: text/html <html><body>HOLA</body></html> --78942734hdfkipiriepiryewi7979rb213cxzb Content-Disposition:form-data; name="overwrite" true --78942734hdfkipiriepiryewi7979rb213cxzb--
Podeu consultar la llista de codis de l’estatus i les seves definicions a: http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html
D’altra banda, les respostes HTTP generades pel servidor han de seguir també un format determinat. L’estructura genèrica del missatge és la mateixa que la usada per a les peticions (vegeu figura). Ara bé, en aquest cas la primera línia indicarà l’estatus de la petició per tal que el client pugui saber en rebre la resposta si s’ha pogut satisfer i en cas que no s’hagi pogut, quin n’ha estat el motiu. La línia d’estatus conté també tres elements. El primer es correspon amb la versió del protocol utilitzat. De la mateixa manera que a la petició, caldria fer servir el valor actual HTTP/1.1. Separat per un espai seguirà un codi de 3 xifres corresponent al tipus de resposta generada. Així el codi 200 indica que la petició s’ha pogut servir amb èxit, el codi 301 significa que el recurs ha canviat d’adreça, el 403 que l’usuari no té suficients permisos i el 404 que no s’ha trobat el recurs demanat. Podeu trobar el detall de tots els codis al document RFC corresponent. Finalment el tercer element inclourà una frase explicativa del codi de format lliure per tal que pugui utilitzar-se per visualitzar l’estatus en cas que fos necessari.
Podeu consultar la llista de camps de capçalera i les seves definicions a: http://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html
La resposta tindrà també camps de capçalera similars als de la petició que permetran al client reconèixer el tipus de contingut, la mida o d’altra informació que pot ser utilitzada per facilitar la presentació, valorar si cal emmagatzemar una còpia en local (memòria cau), etc. Els principals camps de la capçalera seran: Server per informar de l’aplicació que executa el servei WWW, Set-Cookie per mantenir actiu l’estat d’una connexió entre peticions consecutives, Content-Length, per indicar la mida del cos, Content-Type per determinar-ne el tipus, Last-Modified per indicar la data de la darrera modificació, Expires per controlar la data màxima que es podria emmagatzemar a la memòria cau, etc.
El cos es reserva pel contingut demanat o per la informació generada pel servei WWW amb indicacions a l’usuari. Cal clarificar que els documents HTML que contenen incrustades dades multimèdia, no solen subministrar-se al mateix temps que el document malgrat que es trobin emmagatzemades en el mateix servidor. De fet és el client el que decideix de fer les crides necessàries per acabar obtenint tot el document complert.
Exemple de resposta HTTP
Seguidament podeu veure dues respostes d’un servei WWW. La primera obtinguda amb una petició que ha tingut èxit i la segona amb una petició que contenia una URL inexistent.
Resposta amb èxit:
HTTP/1.1 200 OK
Date: Wed, 17 Jul 2013 18:32:48 GMT
Server: Apache/2.2.22 (Unix) PHP/5.3.10 mod_ssl/2.2.22 OpenSSL/0.9.7d
Set-Cookie: 5170f26bccc1e56c8e292c74405ffb45=en-GB; expires=Thu, 17-Jul-2014 18:32:48 GMT; path=/
Cache-Control: no-cache, max-age=604800
Expires: Wed, 24 Jul 2013 18:32:48 GMT
Content-Type: text/html; charset=utf-8
Set-Cookie: BIGipServerphp-ioc23-pool=346921738.20480.0000; path=/
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en-gb" lang="en-gb" dir="ltr" >
<head>
<base href="http://ioc.xtec.cat/educacio/en/cicles-formatius" />
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
...
</head>
<body>
...
</body>
</html>
Recurs no trobat:
HTTP/1.1 404 Not Found Date: Wed, 17 Jul 2013 22:38:37 GMT Server: Apache/2.2.22 (Unix) PHP/5.3.10 mod_ssl/2.2.22 OpenSSL/0.9.7d Set-Cookie: 5170f26bccc1e56c8e292c74405ffb45=en-GB; expires=Thu, 17-Jul-2014 22:38:37 GMT; path=/ Status: 404 Article not found Cache-Control: no-cache, max-age=604800 Content-Length: 5537 Content-Type: text/html; charset=utf-8 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en-gb" lang="en-gb" dir="ltr"> <head> <meta http-equiv="content-type" content="text/html; charset=utf-8" /> <meta name="language" content="en-gb" /> <title>404 - Error: 404</title> ... </head> <body> <div id="wrapper2"> <div id="errorboxbody"> <h2>An error has occurred.<br /> The requested page cannot be found. </h2> <div id="searchbox"> <h3 class="unseen">Search</h3> <p>You may wish to search the site or visit the home page.</p> </div> <div> <p><a href="/educacio/index.php" title="Go to the Home Page">Home Page</a></p> </div> </div> </div><!-- end wrapper --> </body> </html>
El llenguatge HTML
HTML és un llenguatge de marques que permet crear documents web. Va ser ideat per l’equip de Tim Berners-Lee amb la intenció de facilitar la compartició de la gran quantitat de documentació científica i tècnica que s’anava generant al CERN. Es va dissenyar un llenguatge d’etiquetes de text prou senzill com perquè els autors poguessin crear els documents amb un editor de text. Com que els autors no eren editors, ni havien de tenir coneixements d’edició, es va optar per un llenguatge de marques eminentment semàntic en el qual aquestes representaven parts lògiques del document com ara els títols o els paràgrafs.
Des que va veure la llum a principis dels anys 90, fins avui, l’HTML ha patit molts canvis, ha incrementat intensament la seva funcionalitat i s’ha consolidat com una clara iniciativa, no només de creació de documents web, sinó també de definició d’interfícies gràfiques d’usuari. En la darrera versió publicada i recomanada pel W3C recentment (2012), es fa una aposta forta per una especificació clarament estructural (semàntica) capaç però d’absorbir múltiples tecnologies perifèriques (CSS, SVG, MathMl, llenguatges script, connexions asíncrones, etc.) que li donen una gran projecció de futur i una alta modularització. Això facilita, sens dubte, l’escalabilitat de la proposta.
En general, qualsevol document necessita una estructura interna que li doni coherència per poder ser llegit i entès. HTML permet definir aquesta estructura, identificant cada una de les seves parts. Es tracta d’una composició recursiva perquè a la vegada algunes d’aquestes parts poden definir-se també com una composició, formada d’altres parts més petites. El resultat pot visualitzar-se com una estructura jeràrquica en forma d’arbre en la qual cada node conté altres nodes (composició) a excepció de les fulles, en les quals trobarem el contingut propi del document, sigui contingut textual, gràfic o d’un altre tipus.
Estructura d'un document
Qualsevol document o pàgina multimèdia pot estructurar-se en diversos components, inclosos uns dintre d’altres seguint un esquema en forma d’arbre en el qual l’arrel es correspon amb la pàgina sencera, les fulles amb el contingut pròpiament dit i els nodes intermedis amb els contenidors que configuraran l’estructura interna del document (figura).

Consulteu el mòdul anomenat Llenguatges de marques i sistemes de gestió d’informació de DAM per conèixer més detalls sobre els llenguatges de marques.
En l’argot dels llenguatges de marques, els components de l’estructura, els nodes de l’arbre, s’anomenen elements. Els llenguatges de marques com HTML disposen d’etiquetes de text per poder marcar els límits de cada element, no els límits físics sinó els estructurals. És a dir, quins elements estaran inclosos dins de quins altres. Les etiquetes determinaran l’estructura tancant el contingut entre una marca que indicarà l’inici de l’element i una que n’indicarà el final. El client decidirà la millor manera de mostrar el contingut a l’usuari donant forma a cada element. La funcionalitat i el comportament visual de les etiquetes pot modificar-se usant atributs i definicions d’estils de text (CSS).
Malgrat que el llenguatge HTML deriva originàriament de l’SGML (Standard Generalized Markup Language), hi ha una clara intenció d’anar-lo acostant a la forma més restrictiva de l’XML (eXtensible Markup Language). XML és una variant de l’SGML més restrictiva que simplifica el procés d’anàlisi dels documents que segueixen les seves especificacions. Per exemple, les etiquetes XML són sensibles a majúscules, és obligatori incloure sempre una única etiqueta que faci d’arrel de l’estructura, no es poden cavalcar etiquetes, cal deixar ben clar si un element es troba o no inclòs dins d’un altre, etc. Quan un document compleix les restriccions imposades per l’XML direm que es troba ben format. Els documents HTML ben formats tenen totes les seves etiquetes en minúscula i segueixen les seves restriccions, com les esmentades.
En versions anteriors a l’HTML 5, l’etiqueta DOCTYPE pot canviar el seu atribut ja que és necessari indicar quin és el DTD que segueix el document. La versió 5 ha intentat simplificar-ho ja que es tractava d’una dada molt infrautilitzada perquè els navegadors intenten sempre acceptar qualsevol document malgrat no compleixi el DTD indicat.
Per tal de poder reconèixer de forma senzilla un document HTML d’altres documents de text, caldrà començar indicant el tipus amb la etiqueta <!DOCTYPE HTML>. Es tracta d’una etiqueta opcional que ha d’estar situada, si hi és, a la primera línia i que no necessita tancament. L’etiqueta arrel de qualsevol document HTML s’anomena html i conté dos elements opcionals, head i body. L’element head conté metainformació adreçada a l’aplicació encarregada d’analitzar els documents. No és informació que calgui mostrar a l’usuari. A l’element body, en canvi, hi trobarem tot el contingut visible del document i la seva estructura interna.
Els principals elements de head són title, meta, link o script. El primer permet informar al client del títol amb el qual es coneix el document. No ha de coincidir amb el títol visible que podrà encapçalar el format visual, sinó que identifica el nom amb el qual es vol donar a conèixer el document. L’element meta conté informació diversa pel client. Es tracta d’informació que no es mostrarà a l’usuari però pot ser útil pel automatitzar alguns processos del navegador. L’element link permet vincular informació continguda en fitxers externs. Els principals vincles que l’element referencia solen ser fitxers d’estil CSS, però n’admet també d’altres formats. Finalment amb l’element script podrem incloure algoritmes imperatius que s’executaran durant la càrrega del document. Javascript és el llenguatge més estès i reconegut per a tots els navegadors. Els algoritmes es podran incloure directament dins l’etiqueta o bé es podran referenciar com un fitxer extern que caldrà llegir i executar en el moment de la càrrega de l’HTML.
Algunes de les etiquetes que podem trobar el contenidor body s’anomenen de bloc en contraposició a les etiquetes lineals. Les primeres són contenidors que tendeixen a ocupar tota la pantalla en funció del seu contingut i entre elles acostuma a haver-hi una separació clara. Les lineals, en canvi, són contenidors pensats per disposar-se en una mateixa línia de text per mantenir alguna característica comú d’un conjunt de paraules o lletres que pertanyin a un mateix element de bloc. Per exemple l’element p (paràgraf), form (formulari) o div (divisió) pertanyen als elements de bloc, en canvi em (èmfasi), code (codi) o span (extensió) són elements lineals.
Alguns elements, amb independència de si són de bloc o lineals, tenen funcions molt precises com ara article que vol representar la part central del document, el contingut en el qual es troba l’article, la informació central; com ara abbr que permet identificar una abreviació o table, tr, td … adequades per descriure informació tabular. Altres elements, per contra, són molt genèrics i permeten fer-se servir per a una gran quantitat de casos ben diferents. L’exemple més extrem són divo span. De fet són una abstracció que permet marca qualsevol cosa. La versió de bloc és div i la versió lineal és span. Entre les més específiques i les més genèriques trobarem un gran ventall d’elements.
El llenguatge HTML destina també un gran esforç a descriure aspectes gràfics de la interfície de l’usuari i a poder interactuar amb ells. Són components funcionals com ara botons, camps de text, selectors de fitxers o ràdios usant l’etiqueta input o button, llistes de selecció amb l’etiqueta select, imatges gràfiques amb l’element canvas o un editor de text multilínia amb textarea.
No disposem de suficient espai per podem estudiar cada un dels elements HTML en detall. Tot i així, malgrat que no és imprescindible, és convenient que estigueu familiaritzats amb el llenguatge. A la xarxa disposeu de molts manuals i exemples que us poden ajudar amb aquesta familiarització.
Qualsevol comportament per defecte de les etiquetes HTML pot ser manipulat i canviat fent servir estils. CSS permet descriure estils parcials que es van complementant entre ells. La forma més bàsica és la que associa un conjunt d’estils a una etiqueta. Això farà que totes les etiquetes d’un document HTML que responguin a la mateixa denominació es presentin de la mateixa manera. Sabent que h1 és l’element que conté el títol principal, que h2 conté els apartats i h3 els subtítols dins de cada apartat, podem definir un estil per cada un d’ells de manera que tot el document guardi un grau de coherència estilística que ajudi a identificar el que s’estigui llegint.
Per facilitar la descripció d’estils i mantenir la coherència esmentada, CSS propicia la definició mínima d’estils. És a dir, només caldrà definir un estil quan sigui estrictament necessari. Per això CSS desplega sempre l’estil en cascada cap a tots els components d’un element. Amb això volem dir que si un element es definís amb una mida de font petita, tots els elements continguts en el primer requeriran també una mida de font petita sempre que l’estil de la seva etiqueta no indiqui una mida de font diferent.
A la pràctica, la majoria de documents necessiten moltes excepcions a l’hora de definir els estils de les seves etiquetes, per això és comú poder matisar la selecció d’un estil a una etiqueta o conjunt especific (per exemple d’una zona). Aconseguirem identificar conjunts particulars d’etiquetes marcant-les amb un nom a l’atribut class. els noms identificadors dels atributs class, a la definició CSS s’identifiquen perquè porten un punt com a prefix i s’anomenen selectors de classe. De forma semblant, podem identificar elements concrets usant el seu atribut identificador (id). En aquest cas, els selectors d’identificadors es reconeixen a la definició CSS amb el prefix #.
Alguns elements HTML mantenen diversos estats durant la visualització. Per exemple l’etiqueta indicada reconeix quan un hipervincle ha estat ja visitat, quan el ratolí es troba sobre d’ell o quan es realitza el clic. Els diferents estats pels quals una etiqueta pot arribar a passar s’identifiquen usant un nom amb el prefix : i a CSS s’anomenen selectors de pseudoclasse.
Quan les definicions d’estil són complexes, sovint trobarem etiquetes sobredefinides per diversos estils CSS. En aquest cas prevaldrà sempre la definició que faci coincidir més noms d’elements contenidors, classes i identificadors si fos el cas. En cas d’empat, prevaldrà l’etiqueta definida en darrera instància.
Exemple de definició d'estils CSS
En aquest exemple podeu veure estils definits amb una única etiqueta i tots els seus components en els quals l’estil específic no es trobi sobreescrit, estils amb selectors de pseudoclasses (a link, per exemple), amb selectors de classes (vegeu h2.ex1) o d’identificadors (#tagid1 n’és un exemple). Aquells estils marcats amb múltiples selectors (div.class10 ul li) s’aplicaran a les etiquetes contingudes en els elements indicats seguint una estructura jeràrquica. Per exemple, el selector div.class10 ul li s’aplicarà a les etiquetes li contingudes en etiquetes ul i en etiquetes div marcades per la classe class10. A la resta d’etiquetes li no se’ls aplicarà l’estil.
Implementació de clients web
Parlarem de clients de serveis web per referir-nos a aplicacions capaces de generar peticions HTTP, recollir la resposta que arribi del servidor, identificar l’estatus de la resposta i en cas d’èxit fer una tractament amb el contingut HTML o bé en cas d’error, fer una nova petició o presentar el problema a l’usuari. En general, doncs, la implementació dels clients requerirà dos processos força independents: l’encarregat de gestionar la connexió HTTP i l’encarregat de gestionar la informació HTML de la resposta.
Els navegadors són aplicacions clients que realitzen aquestes tasques per aconseguir mostrar una representació gràfica de la informació arribada des del servidor. El llenguatge HTML és tan versàtil que sovint els navegadors seran les úniques aplicacions necessàries a la banda client. La gran qualitat dels navegadors actuals fa difícil pensar en implementar noves alternatives. Tot i així, cal preveure la necessitat de crear aplicacions complementàries que permetin oferir respostes alternatives ja sigui en forma d’aplicació independent o integrades en un navegador concret.
Podem desenvolupar un gestor HTTP fent servir sòcols, però Java disposa d’una classe ja implementada que fa aquesta funció. Ens referim a URLConnection. Es tracta d’una classe abstracta que permet representar una connexió a un servei indeterminat com ara FTP o HTTP. La implementació del protocol HTTP es concreta amb la classe HttpURLConnection que serà la classe amb la qual realment treballarem sempre que demanem de fer connexions a servidors web. Vegeu l’esquema de la figura.

De forma genèrica la classe URLConnection disposa del mètode getHeaderField per consultar qualsevol camp de la capçalera HTTP i setRequestProperty per assignar-hi valors. El primer rep com a paràmetre el nom del camp. El segon, a més del nom del camp, se li passa un segon paràmetre amb el valor que es desitja assignar. El valor retornat per getHeaderField, així com el paràmetre que assignarà el valor a setRequestProperty són de tipus string.
Exemple d'ús dels mètodes getHeaderField i serRequestProperty
Suposarem que con és una variable de tipus URLConnection i charset una variable de text que conté un joc de caracters vàlid, per exemple UTF-8.
El mètode de lectura getHeaderField accepta també com a paràmetre un número indicant la posició ocupada a la capçalera. D’aquesta manera és possible recórrer tots els camps sense necessitat de saber-ne el nom. En aquest cas el mètode getHeaderFieldKey ens retornarà el nom del camp.
La classe URLConnection disposa també de mètodes específics de consulta de camps de capçalera habituals que permeten treballar amb tipus de dades més adients. Podeu veure una relació d’aquest a la taula taula.
| Mètode per obtenir el valor | Camp HTTP | Tipus de dada usada | Comentaris |
|---|---|---|---|
getContentEncoding() | Content-Encoding | String | |
getContentLength() | Content-Length | int | getContentLenth() retornarà -1 si la capçalera no conté aquest camp |
getContentType() | Content-Type | String |
|
getDate() | Date | long | Retorna el número de mil·lisegons transcorreguts des de l’1 de gener de 1970 o 0 si no hi ha data establerta a la capçalera. Es pot usar per construir un objecte Date o Calendar |
getExpiration() | Expires | long | El format és el mateix que getDate() |
getLastModified() | Last-Modified | long | El format és el mateix que getDate() |
Si necessitem informació específica del protocol haurem de treballar amb la classe HttpURLConnection, però si la connexió l’hem obtinguda a través d’una instància d’URL, caldrà fer una conversió explícita.
La classe HttpURLConnection disposa, per exemple, de mètodes com ara getResponseCode() per aconseguir el valor de l’estatus d’una resposta o el seu missatge amb getResponseMessage(). La classe permet també obtenir o assignar el mètode HTTP de la petició (GET, POST, PUT, DELETE…) així com altres funcionalitats específiques del protocol HTTP.
El funcionament d’aquesta classe és força senzill. Abans d’enviar la petició podrem manipular-la fent servir els mètodes d’assignació com ara setRequestMethod(nomDelMetodePeticioHttp) o setRequestProperty(nomCampPeticio, valorCampPeticio). Un cop enviada la petició no serà possible assignar-hi dades a la capçalera i si ho intentem ens respondrà amb una excepció. Usant aquesta classe, no és necessari fer un enviament explícit de la petició HTTP, perquè aquest es realitza de forma automatitzada en realitzar qualsevol consulta referida a la resposta, com per exemple getResponseCodeo getHeaderField.
Quan el mètode utilitzat per realitzar la consulta sigui POST, podrem escriure el cos del missatge fent servir el mètode getOutputStream que ens retornarà el flux de sortida en el qual podrem anar escrivint tot el que sigui necessari de fer arribar en el cos. En aquest cas tampoc serà possible escriure dades un cop la petició hagi estat enviada.
Podem forçar l’enviament de la petició de forma explicita usant els mètodes del flux de sortida que forcin l’enviament com ara flush o close. Un cop enviada la petició és important fer el tancament del flux per alliberar els recursos de la xarxa. A continuació se us mostra un codi que escriu el contingut d’un fitxer al cos del missatge usant el tipus multipart de MIME.
Un cop completades totes les parts, podrem forçar l’enviament de la petició fent:
Recordeu que la consulta de qualsevol element de la resposta, tant les dades de la capçalera com el valor de l’estatus, comporta l’enviament immediat de la petició. Per tant cal anar en compte de realitzar les consultes sempre en l’ordre adequat.
La classe HttpURLConnection, disposa també de l’opció de demanar que es realitzi una nova petició quan el codi de l’estatus sigui de la forma 3XX, que indica sempre un valor de redireccionament causat per un trasllat (temporal o definitiu) del recurs demanat. El mètode que permet realitzar aquesta configuració és setInstanceFollowRedirects(certOFals). El mètode rebrà un valor lògic cert si es desitja fer efectius els redireccionaments o fals en cas contrari.
Per recollir el valor de cos de la resposta, usarem el mètode getInputStream que retornarà el flux d’entrada de dades provinents del servidor. L’obtenció de les dades seguirà la dinàmica habitual dels fluxos de dades. D’entrada el flux recollit és de tipus byte, però si sabem que el contingut és de tipus text, podem convertir-lo a un flux de caràcters per facilitar-ne el tractament.
Generalment el client rebrà un document HTML que haurà d’interpretar, ja sigui per mostrar a l’usuari o per realitzar qualsevol altra tasca. El tractament dels documents HTML solen fer-se utilitzant un tipus d’aplicacions anomenades analitzadors sintàctics. Els analitzadors sintàctics serveixen per aconseguir interpretar qualsevol producció que segueixi la sintaxi d’un llenguatge formal. Els llenguatges de programació com Java són llenguatges formals i el seu analitzador sintàctic és el compilador o l’intèrpret segons treballin de forma interpretada o compilada. Els llenguatges de marques derivats d’SGML o XML són també llenguatges formals i poden analitzar-se de forma semblant. La majoria de llenguatges de programació disposen de biblioteques amb analitzadors genèrics per facilitar el tractament dels documents que segueixin les especificacions d’aquests llenguatges.
Distingim dos tipus d’analitzadors. Aquells que llegeixen seqüencialment el document i gestionen el tractament que s’ha de realitzar fent invocacions específiques, a mode d’esdeveniments, cada cop que detectin el començament o final d’una etiqueta, o un cop llegit el contingut textual d’un element. Les dades llegides durant la seqüenciació s’aniran passant per paràmetres als mètodes invocats durant l’anàlisi. Així, per exemple, el mètode invocat en detectar l’obertura d’una etiqueta rebrà probablement el nom de l’etiqueta, la col·lecció d’atributs associats amb els seus valors i d’altra informació complementària. Sabent la informació traspassada podrem codificar les accions a realitzar amb aquestes dades.
Exemple de tractament d'un esdeveniment d'un analitzador sintàctic de marques
Suposem que el mètode invocat sigui startTag i que per paràmetre rebi una cadena amb el nom i un HashMap amb els atributs i valors. Un possible esquema seria:
D’aquesta manera podem crear un codi ben diferenciat i fàcil de mantenir per a cada etiqueta. Imaginem que volem construir un navegador per visualitzar documents HTML. Davant l’esdeveniment de l’inici d’una etiqueta de tipus link s’ha de detectar si es tracta d’un full d’estils, recuperar les dades del fitxer vinculat i carregar-les en memòria per tal que es puguin recuperar quan sigui necessari aplicar-les usant la informació relativa a cada etiqueta. Si en canvi l’etiqueta fos de tipus img el que cal fer és recuperar els bytes corresponents a la imatge, crear un instància de la classe Image amb les dades obtingudes, adaptar-la a la mida que ens indiquin els atributs, obtenir la posició del bloc veí per calcular la posició en la qual situarem la imatge i finalment plasmar mostrar la imatge per la pantalla. Cada element necessitarà un tractament específic. Caldrà també mantenir les dades comuns en memòria per tal de poder realitzar adequadament els càlculs sobre posicions, mides i estils a aplicar.
Exemple de processament d'una etiqueta link
En aquest exemple suposem que disposem d’un analitzador del format CSS, que anomenem cssParser. Quelcom semblant a l’analitzador que intentem construir però adaptat al format CSS i que en lloc de detectar etiquetes, detecta selectors i extreu el conjunt d’estils associats. Imaginem que disposem també d’una classe que emmagatzema els estils i permet ser interrogada a partir del nom, atributs i jerarquia a la qual pertanyi una etiqueta sobre la qual calcular l’estil a aplicar. Suposem que disposa d’un mètode anomenat add per afegir el conjunt d’estils analitzats per l’objecte cssParser.
Noteu la complexitat que implica la implementació de tot un navegador.
Java disposa de la biblioteca SAX per realitzar l’anàlisi de documents XML. El principal problema d’aquesta biblioteca són les restriccions pròpies de l’XML. Els documents mal formats provoquen errors durant l’anàlisi que acaben avortant el procés. De fet usant SAX només tindríem garantia d’èxit llegint documents XHTML perquè segueixen la sintaxi HTML respectant totes les restriccions dels XML. Malauradament a la xarxa hi ha una gran quantitat de documents HTML mal formats i per tant SAX no és el millor candidat.
La biblioteca swing del JDK, en canvi, disposa d’un conjunt de classes menys restrictives capaces també de fer una anàlisi sintàctic amb el corresponent llançament d’esdeveniments. La classe ParserDelegator s’encarrega de llegir el document i detectar el moment en què caldrà fer el llançament d’esdeveniments que concretament es limiten a 7 casos:
- Quan es troba un comentari,
- Quan es troba una etiqueta sense contingut
- Quan es troba l’inici d’una etiqueta
- Quan es troba el final
- Quan es troba contingut textual
- Quan es troba un salt de final de línia
- Quan es detecta un error.
Per cada un d’aquests esdeveniments ParserDelegator invocarà un dels mètodes de la classe ParserCallback o alguna classe derivada. De fet, el normal és que s’utilitzin classes derivades per poder personalitzar el tractament a donar per cada esdeveniment. A la figura se simbolitza això amb la classe MyHandler que representa la classe que personalitza el tractament. De fet, ParserCallback és una classe interna d’ HTMLEditorKit i només existeix per poder ser invocada durant l’anàlisi, ja que tots els seus mètodes estan buits, no realitzen cap tasca. La idea de separar l’analitzador (ParserDelegator) del tractament (MyHandler) és molt potent perquè en essència dos analitzadors que haguessin de fer coses diferents realitzarien sempre la lectura i la detecció d’etiquetes de la mateixa manera i l’únic que variaria seria el tractament. Per realitzar una còpia en el disc dur del codi HTML i de tota la resta de fitxers vinculats com ara imatges, fitxers script, fulls d’estil, etc. caldrà crear només un classe derivada de ParseCallback. Per contra si decidim implementar un navegador que visualitzi el document. Podem aprofitar tot el codi realitat a excepció de la classe derivada de ParserCallback que haurà de fer un tractament diferent (vegeu la figura).

El mètode handleStartTag(Tag t, MutableAttributeSet a, int pos) rep per paràmetre l’etiqueta en forma de classe Tag. La classe Tag és un classe que guarda el nom de l’etiqueta, però que a més manté informació addicional sobre si l’etiqueta és de tipus bloc o lineal, o sobre si el seu contingut és de tipus preformatat o bé cal aplicar-li les regles d’estil corresponents. Generalment, només usarem aquest paràmetre per identificar el nom de l’etiqueta. La classe Tag conté també la majoria d’etiquetes HTML ja instanciades en forma de constant. El segon paràmetre rebut és una instància de MutableAttributeSet. Aquesta classe representa el conjunt d’atributs i disposa de mètodes per recórrer tots els seus elements i obtenir-ne la informació detallada (nom i valor). Finalment el tercer paràmetre informa de la darrera posició llegida just abans de fer la crida de l’esdeveniment.
El mètode handleSimpleTag(Tag t, MutableAttributeSet a, int pos) és molt similar a handleStartTag. Rep els mateixos paràmetres, però aquesta crida només es produeix quan es detecta un etiqueta simple, de les que es tanquen en la mateixa marca d’obertura, com per exemple <br/>.
El mètode handleEndTag(tag : HTML.Tag, pos : int), s’invoca en detectar una marca de tancament i rep per paràmetre l’etiqueta que s’està tancant i la darrera posició llegida.
El mètode handleText(data : char[], pos : int) permet obtenir el contingut textual contingut a la darrera etiqueta oberta i encara no tancada. El contingut arriba en forma d’array de caràcters. El segon paràmetre fa referència també a la darrera posició llegida.
Semblant a l’anterior handleComment(data : char[], pos : int) rebrà les dades contingudes dins d’un comentari situat en qualsevol posició dins l’HTML. Normalment els comentaris s’insereixen entre el contingut textual. Per això la invocació d’aquest esdeveniment acostumarà a donar-se entre dues crides a handleText.
Finalment handleError(errorMsg : String, pos : int) s’invoca en detectar algun tipus d’errada, ja sigui sintàctica o d’altre tipus i s’utilitza per poder obtenir informació del tipus d’errada i poder avisar l’usuari.
Un exemple simple que mostra per pantalla les URL de les etiquetes link, script o img en ajudarà a veure com funciona. La classe HtmlEditorKitParser ens permet configurar un objecte PerserDelegator amb una instància derivada de ParserCallback que passarem per paràmetre del mètode init. El mètode parse fa la crida pertinent per iniciar l’anàlisi usant la classe ParserCallback disponible. La classe HtmlPrintExternalPathsHandler és l’encarregada de detectar si l’etiqueta és del tipus que esperem, recollir l’URL i mostrar-la per pantalla. Com que són etiquetes que poden contenir text, però que també poden agafar la forma simple, recollirem ambdós esdeveniments en el procés anomenat processTag.
Abans de començar a parlar de la implementació de la part del servidor, cal tenir en compte que el W3C ha creat una jerarquia d’interfícies per poder emmagetzemar una estructura XML/HTML qualsevol i facilitar la cerca i l’accés a qualsevol dels seus elements. Es coneix amb el nom de DOM (Document Object Model) i pot arribar a ser molt útil en aplicacions que hagin d’accedir contínuament als seus elements (vageu la figura). El tractament d’esdeveniments com el que acabem de veure només resulta pràctic quan s’han de realitzar un sol cop, però els navegadors actuals fan una tractament dinàmic de la informació i han de recuperar o modificar dades parcials de qualsevol part del document. En aquest cas es fa imprescindible usar DOM.

Java disposa de la classe DocumentBuilder per generar, a partir d’un InputStream que contingui un document XML, un objecte Document que representi l’estructura interna de l’XML llegit. Malauradament presenta la mateixa problemàtica que SAX. Com a alternativa podem construir un objecte DOM fent servir una classe ParserCallback ja que no resulta massa difícil d’implementar.
Implementació servidors web
Malgrat que la funció original dels servidors web era la de rebre peticions, cercar el document demanat entre els seus fitxers i enviar la resposta juntament amb el document si es trobava, actualment la majoria de llocs web generen les pàgines demanades dinàmicament. És a dir, els servidors han passat de ser un repositori de documents HTML a convertir-se en complexes aplicacions que fusionen fragments d’HTML amb dades provinents d’altres fonts com ara SGBD o fins i tot d’altres serveis externs.
El principal repte que se’ns planteja a l’hora de fer una implementació dels servidors web com a repositoris de documents té a veure amb la rapidesa a l’hora de servir les pàgines HTML i el suport de gran quantitat de peticions concurrents, que bàsicament se soluciona incrementant la potència del maquinari i afinant tant com sigui possible l’ús de la memòria i la gestió dels fils per a possibilitar la concurrència. Avui dia existeix una gran quantitat d’aplicacions molt eficients i seria absurd plantejar-nos implementacions alternatives.
En canvi, la generació dinàmica de les pàgines web implica una major complexitat i la intervenció necessària dels programadors en qualsevol projecte nou. Actualment existeix una gran quantitat d’aplicacions capaces de gestionar les peticions HTTP i generar un conjunt d’utilitat que permetin als programadors agilitzar la creació de les seves aplicacions. De forma genèrica s’anomenen servidors d’aplicacions web perquè és possible desenvolupar-hi aplicacions complexes basades en HTTP i HTML. Són aplicacions molt dependents del llenguatge de programació utilitzat ja que necessiten integrar el que els programadors desenvolupin amb les biblioteques internes que disposin, per això cada servidor d’aplicacions web sol servir només per un únic llenguatge de programació.
Mireu l’annex anomenat Configurar NetBeans per treballar amb un servidor d’aplicacions web (contenidor EE) integrat a l’IDE per saber com treballar amb un servidor d’aplicacions web des del NetBeans.
Java disposa d’una gran varietat de servidors d’aplicacions, malgrat que els més coneguts són Tomcat i Glassfish. El primer és un projecte d’Apache i el segon del propi Oracle. El desenvolupament original es remunta a Sun Microsystems, que Oracle va comprar juntament amb el desenvolupament de Java.
Tots els servidors destinats al llenguatge Java hauran de seguir l’estàndard especificat a la plataforma JEE (Java Enterprise Edition). JEE és un extensió del JDK que inclou l’especificació per crear aplicacions remotes. L’especificació JEE és realment molt extensa i s’escapa totalment dels objectius d’aquest mòdul. Tot i així caldrà donar una ullada a les biblioteques bàsiques que suporten l’extensió. Precisament aquestes enllacen directament amb el protocol HTTP, el que comunament es coneix amb el nom genèric de servlets.
Anomenem genèricament servlets a la jerarquia de classes Java que modelitza el protocol HTTP de la part del servidor. Malgrat que hi ha moltes més classes, a la figura trobareu les classes bàsiques que us permetran realitzar qualsevol aplicació web.

La classe principal del model és HttpServlet. No és una classe funcional perquè tots els seu mètodes es troben buits. De fet, bàsicament serveix per poder crear classes derivades que seran les que realment implementaran la funcionalitat als seus mètodes i que en l’argot Java es coneixen habitualment com a servlets.
HttpServlet i les seves derivades disposen de mètodes que seran cridats cada cop que el servidor d’aplicacions rebi una petició HTTP d’algun client. Els mètodes s’anomenen doGet, doHead, doPost, duPut, doDelete, doTrace i doOptions i es troben totalment relacionats amb el mètode HTTP especificat a la capçalera de la petició, de manera que la invocació es realitzarà en funció del mètode HTTP. Així un petició HTTP amb el mètode GET provocarà una execució del mètode goGet de la instància d’ HttpServlet especificada a la URL de la petició. El mètode doPost s’executarà quan a la petició hi figuri el mètode POST i així successivament.
Habitualment els servidors d’aplicacions que treballen amb Java s’anomenen també contenidors de servlets o simplement contenidors.
Un servidor d’aplicacions pot contenir molts servlets, d’aquí que habitualment se’l coneix com a contenidor. Quan arribi una petició d’un client, el contenidor la llegirà i guardarà les seves dades en un objecte de tipus HttpServletRequest. També crearà una objecte de tipus HttServletResponse preparat per gestionar l’enviament de la resposta al client. Finalment analitzarà la URL per reconèixer el nom del servlet al qual caldrà invocar (vegeu la figura). Si ja existeix en memòria, una instància del servlet demanat (degut a peticions anteriors) executarà el mètode adequat d’aquesta instància. Si a la memòria no hi hagués encara cap instància del servlet, el servidor d’aplicacions en crearà una i seguidament executarà el mètode. Per agilitzar el procés de crida, els servlets invocats solen deixar-se en memòria mentre hi hagi prou espai i el rendiment sigui òptim. En situacions crítiques, el servidor d’aplicacions pot decidir eliminar les instàncies d’aquells servlets menys populars o dels que faci més temps que no es rebi una petició.
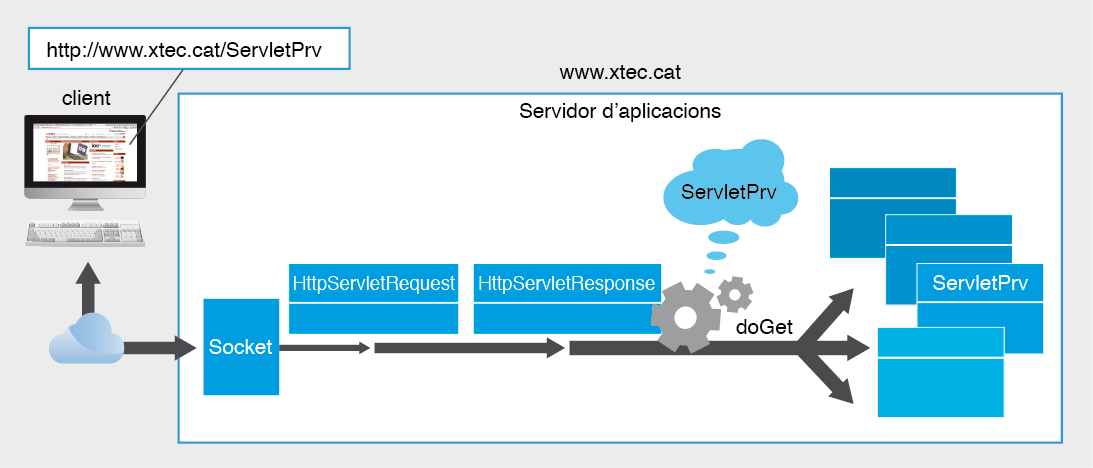
En carregar una instància d’un servlet a la memòria, es pot incialitzar amb un objecte ServletConfig que contindrà els paràmetres inicials per aconseguir que el servlet funcioni. Per exemple podríem carregar les dades de connexió a un SGBD si el servlet necessités treballar amb les dades d’una base de dades.
Els mètodes dels servlets candidats a ser executats en una petició (doGet, doPost, etc.) rebran sempre dos paràmetres, un amb la instància HttpServletRequest i l’altre amb la instància HttServletResponse. La instància HttpServletRequest contindrà totes les dades rebudes a la petició, com ara els paràmetres arribats en el cos o a través de l’URL, els camps de capçalera de la petició, les galetes (cookies) del client, les dades de connexió (adreça IP, port, etc.) o la URL utilitzada per aquesta petició. A més, el paràmetre HttpServletRequest inclou molta informació provinent del contenidor com ara si l’usuari està o no autenticat, la sessió que el contenidor manté oberta per aquesta connexió i permet, si cal, iniciar un procés d’autenticació. El següent exemple ens mostra l’ús d’aquests mètodes.
Ús dels mètodes del paràmetre HttpServletRequest per obtenir la informació que conté
Suposarem que la URL demanada era /NomServlet?joc=parxis&categoria=principiant.
El paràmetre de tipus HttpServletResponse, permetrà gestionar la resposta que cal donar a l’usuari. És a dir permetrà assignar l’estatus, afegir camps de capçalera, assignar el valor de les galetes i escriure el contingut a retornar que habitualment estarà formatat en HTML en un flux de tipus writer que la instància posarà a la nostra disposició. De nou un exemple ens ajudarà a entendre-ho.
Ús dels mètodes del paràmetre HttpServletResponse per enviar informació al client
A l’exemple, l’HTML generat s’escriu en el propi servlet. Això passa molt poques vegades. Només en els casos que la resposta a generar sigui molt simple. Normalment es treballa amb altres tecnologies més avançades com ara Java Server Page per facilitar la creació de respostes complexes, però la seva explicació cau fora de l’objectiu d’aquest mòdul.
Altres serveis
A Internet podem trobar molts més serveis funcionant. Alguns, com els serveis DNS, es van originar conjuntament amb els primers serveis i han anat mantenint-se perquè encara donen un servei útil i en alguns casos com el citat, imprescindible. També hi ha hagut serveis que han anat sucumbint pel camí o es troben en fase d’extinció perquè d’altres serveis s’han imposat per eficiència o simplement per popularitat.
L’aparició de nous serveis és un fet força habitual. Alguns poden aparèixer com a resposta a noves necessitats que l’ús de la xarxa genera. Per exemple davant de la impossibilitat d’aconseguir adreces IP fixes, apareix la iniciativa DynDNS amb un èxit més que notable. Aquest servei permet associar un nom de domini a adreces IP dinàmiques. D’altres sorgeixen totalment vinculats a l’aparició de noves tecnologies com per exemple la quantitat creixent de serveis per a mòbils.
Actualment ens trobem en un moment de gestació de la futura web 3.0 en el qual els serveis tindran una paper fonamental. La qualitat aconseguida en el camp de la cerca constitueix l’embrió d’una gran quantitat d’idees en les quals la gestió del coneixement, la cerca semàntica, les relacions socials, l’oci o els serveis d’alertes personals i geolocalitzats es troben al centre de les investigacions en combinació amb l’aparició de nous i sofisticats dispositius. El desenvolupament de serveis tot just acaba de començar.
Escalabilitat dels serveis
El ritme de creixement de la xarxa ens obliga a posar sobre la taula de qualsevol desenvolupament el concepte d’escalabilitat. Entenem per escalabilitat la capacitat de fer créixer una aplicació o servei a mesura que sigui necessari sense perdre eficiència en el temps de resposta.
Els principals factors de creixement que poden fer minvar l’eficiència d’un servei són: l’increment del nombre de processos, l’increment de dades a processar i l’increment del nombre d’usuaris que en facin ús. Els dos primers els agruparem sota el nom d’increment de contingut. El darrer s’acostuma a conèixer com a increment de la concurrència, ja que la pèrdua d’eficiència es deu a la coincidència de peticions simultànies.
La capacitat del maquinari esdevé sempre decisiva en aquests casos, però de res servirà si menystenim aspectes del desenvolupament de programari. Un bon disseny, l’ús d’emmagatzematge temporal o una implementació acurada que controli la despesa de recursos i maximitzi el temps del processador permetran aconseguir sens dubte optimitzacions significatives.
Les tècniques de programació multifil ens poden ajudar a incrementar la capacitat de processament i també ens poden permetre donar servei a diversos usuaris a la vegada. Caldrà anar alerta, però, amb el nombre de fils a crear perquè cada fil gasta recursos de memòria i de processador i el sistema operatiu, a més de gestionar l’execució de l’aplicació, haurà de gestionar també la de cada fil, cosa que pot portar al col·lapse del sistema quan els recursos disponibles vagin acabant-se. Limitar el nombre màxim de fils pot resultar una solució acceptable, però si el nombre de clients simultanis supera massa el nombre de fils, deixarem clients sense atendre que rebran errors de timeout o de servei no disponible.
La distribució de la nostra aplicació pot també ser una solució quan cal mantenir un ús alt dels recursos i el nombre d’usuaris creix fins a desbordar la capacitat del servidor. Tot i així el seu desenvolupament incrementarà la complexitat i com a conseqüència el cost, tant de desenvolupament inicial com de manteniment posterior.
És important crear les aplicacions de la mida real que es necessitin, però dissenyar-les de tal manera que resulti possible escalar-les. Per aconseguir aquest objectiu serà necessari dividir l’aplicació en components independents susceptibles de ser modificats per incloure parcialment alguna de les millores esmentades i poder així fer créixer l’aplicació sense haver de canviar-ho tot.
Verificació del servei i monitorització dels components
Com podem detectar, però, la disponibilitat dels nostres serveis? Com podem saber quin component caldrà millorar? Aquesta no és una tasca fàcil perquè en una aplicació hi pot haver una gran quantitat de components i perquè la disponibilitat podria fallar només sota determinades circumstàncies de volum de treball o de nombre de connexions concurrents o d’altres qüestions similars que podrien enganyar-nos si al fer les proves de verificació del codi no es complissin les mateixes condicions.
Cal tenir en compte que a vegades pot donar-se el cas que un servei no es trobi disponible però no hagi caigut, sinó que aparentment tot es trobi en ordre. Necessitaríem una eina que ens pogués observar l’estat intern de la nostra aplicació; una utilitat que controli les errades que es puguin produir, que monitoritzi les condicions d’execució i que ens detecti possibles caigudes i pèrdues de servei.
Existeixen eines externes que poden informar-nos de l’estat de la màquina, ús de la memòria i del processador, nombre de fils concurrents, nombre de ports atesos, etc. Aquestes eines, a més, disposen de capacitat de fer saltar alarmes, activar processos o enviar correus d’avís, quan un servei deixa de funcionar o quan el sistema pren unes determinades condicions. Són eines força útils perquè fins i tot algunes d’elles, com per exemple Nagios o AppaDynamics, disposen de la capacitat de monitoritzar directament la màquina virtual de Java, usant la biblioteca JMX de monitorització del JDK. Això permet detallar molt la monitorització perquè podem decidir què s’ha d’observar exactament.
L’obtenció específica d’informació de la nostra aplicació caldrà programar-la i, per tant, preveure-ho durant el desenvolupament. Caldrà incloure sistemes de monitoratge i recollida de la informació allà on es consideri necessari. Citarem dos sistemes que ens poden resultar molt útils. El primer d’ells, els registres, que habitualment es coneixen com a logs i el segon, l’ús de classes de la bibliotex JMX que Java disposa per monitorar objectes concrets i obtenir en temps d’execució, les condicions en les quals són invocats.
Podeu trobar informació sobre el sistema Logger a http://docs.oracle.com/javase/7/docs/api/java/util/logging/Logger.html
El sistema de logs permet intercalar entre el codi instruccions que enviaran informació en un o més sistemes de sortida (habitualment solen ser fitxers i la pantalla) en funció d’un valor numèric que anomenem nivell. Java defineix al menys 7 rangs que tipifica com a FINEST, FINER, FINE, CONFIG, INFO, WARNING i SEVER. En executar una aplicació és possible assignar un valor inicial al nivell de manera que s’executin totes les instruccions log que tinguin associat un nivell igual o major. Malgrat que no s’acostuma a fer, es pot modificar el nivell inicial dinàmicament en temps d’execució de manera que en el nostre codi podem situar instruccions condicionals que alterin el comportament habitual dels registres. Per defecte el valor inicial de qualsevol execució és SEVER. Això permet fer servir el sistema com un registre d’errors, però tenim l’aplicació preparada per poder realitzar altres registres rebaixant el valor del nivell inicial.
Exemple que mostra una aplicació de monitoratge basada en logs
La biblioteca destinada al monitoratge de Java (JMX) contempla diverses utilitats. Podem, per exemple, recollir els valors de l’estat de la màquina virtual i conèixer la quantitat de memòria gastada per la nostra aplicació, el temps que fa que està en execució, quan ha passat per darrer cop el garbage collection, quants fils s’han iniciat, quants queden encara actius, quants es troben en estat zombi, etc. Podem usar aquestes dades en combinació amb el sistema de logs per enregistrar aquesta informació quan es produeixi una errada, per exemple.
Exemple que mostra com fer servir la informació del sistema usant JMX
Usant JMX també és possible monitoritzar un objecte específic per tal d’obtenir-ne les dades internes. Per fer-ho cal construir una classe de tipus MXBean o MBean en la qual codificarem el tractament que volem donar-li a la monitorització. L’avantatge que presenta aquesta darrera modalitat és que es poden connectar de forma remota una consola específica per monitorar a través de JMX, anomenada JConsole, en la qual podrem visualitzar les dades codificades. Per contra, direm que la codificació presenta certa complexitat amb la qual cal familiaritzar-se. Tot i així, és un sistema molt potent perquè permet la connexió d’eines externes com ara Nagios o AppaDynamics de forma que puguin actuar com a consola avançada amb totes les utilitats que aquestes eines posen a la nostra disposició.
Disseny basat en components
Del disseny de components només donarem una visió molt general per fer-vos conscients de la importància que això suposa. Donarem també alguns consells que us ajudin en el moment de realitzar la planificació i el disseny. En el disseny de components, l’abstracció és fonamental. Trobem tres aspectes clau quan parlem de components: es tracta d’una unitat i per tant cal que presenti certa independència respecte els altres components; ha de ser reutilitzable en la mesura que sigui possible; i finalment hi ha components que formaran part d’altres components més grans.
Si analitzem en la seva globalitat la funcionalitat d’un servei distribuït, ens adonarem que a banda de les tasques específiques pròpies del problema que resol, el que habitualment es coneix com a lògica de negoci, trobarem moltes altres tasques comunes que es repeteixen sovint en gairebé tots els serveis. No sempre seran tasques implementades de forma idèntica, però sí que presentaran trets comuns.
Una mica de disseny descendent ens ajudarà a descobrir els components i la seva funcionalitat. Partim dels components bàsics. Considerarem que en general un servei ha de tenir dos components: el component més específic encarregat de la “lògica de negoci” i el component que trobarem a qualsevol servidor encarregat d’escoltar el port assignat, gestionar les peticions que li arribin i derivar-les al component específic per tal d’obtenir una resposta i enviar-la al client (figura).

Aviat podem veure que el component que hem anomenat Servidor podria dividir-se en dos. L’un contenint l’altre. El servidor genèric atén el port a l’espera de qualsevol petició i un cop li arriba una haurà de resoldre-la. Podem entendre la necessitat de diferenciar entre l’escolta genèrica i l’atenció d’una petició concreta. Distingirem, doncs, un component servidor que contindrà un component específic per atendre cada petició que els clients enviïn, transformant els inputs dels clients en els paràmetres d’un mètode del component Solver que caldrà invocar per generar la resposta (vegeu la figura).

Davant la perspectiva d’haver de treballar amb diversos serveis a la vegada, podem intuir la necessitat de disposar d’una gestor de serveis sense necessitat de decantar-nos per cap solució a priori. Reconeixem la necessitat d’un gestor que acabarem implementant de maneres diverses segons la quantitat de peticions concurrents que calgui gestionar (figura).

La complexitat de les peticions també ens pot suggerir que en ocasions haurem de definit un protocol i per tant poden suposar la necessitat de disposar d’un component que ens el gestioni (figura).

A més, la complexitat pot aconsellar d’afegir nous elements que ajudin a tractar de manera eficient la petició del client (component analitzador o RequestParsers) i la selecció del procés del Solver que caldrà invocar (component Dispatcher). Vegeu la figura.

Què fem, però, amb tants components a l’hora d’implementar el servei? Caldrà implementar cada component en una classe independent? Podeu intuir que la resposta dependrà d’una implementació a l’altra. Hi haurà serveis en els quals es prevegi un ús escàs i amb unes peticions molt simples, però d’altres marcats per una gran concurrència de peticions, un temps de resposta gran, un joc de peticions complex o tot a la vegada. Sigui com sigui, però, cal entendre que tots ells, tinguin la mida que tinguin, realitzaran des d’una perspectiva abstracta, les mateixes funcions; no tots de la mateixa manera, és clar, en alguns casos la funcionalitat assignada a un dels components es podrà resoldre amb un únic mètode, en altres casos caldrà implementar tota una classe i a vegades serà necessari fer servir més d’una classe. A vegades caldrà gestionar fils i a vegades distribuir els processos, però en tots els serveis trobarem uns trets comuns que usarem per encaminar un disseny escalable.
Les interfícies ens ajuden a aconseguir el grau d’abstracció que necessitem permetent implementar amb una mateixa interfície solucions diferents. Darrere una interfície podem trobar fragments d’una classe, una classe sencera o fins i tot una biblioteca de classes que acabaran oferint la funcionalitat requerida amb la concreció necessària. Part de l’èxit pot passar, doncs, per crear interfícies prou versàtils per suportar diversos graus d’escalabilitat.
L’exemple que desenvolupem aquí és una simplificació d’un cas real en pro de la comprensió dels elements a tenir en compte per obtenir un disseny escalable. Es proposa una interfície que doni accés a cada component a excepció del component Solver perquè no es poden conèixer a priori les seves necessitat ja que depèn de cada cas concret. Suposarem també que la comunicació està basada en caràcters.
Un tema també força important és el tractament de les excepcions. Seguint la màxima de no capturar cap excepció amb la qual no sapiguem què cal fer-hi, ens podem trobar quan fem abstraccions d’aquestes característiques, que cada implementació llanci excepcions diferents i que sovint calgui llançar excepcions de molt diverses jerarquies amb el consegüent increment de complexitat quan sigui necessari fer el tractament.
Una possible solució passa per crear un excepció o una jerarquia comuna per a totes les implementacions, que permeti incloure l’excepció real generada per l’error en el moment de fer la instanciació. Això implica capturar sempre totes les possibles excepcions que es puguin produir, fer-ne el tractament que calgui en cas que sigui necessari i/o encapsular-la en una excepció nova específica de la jerarquia creada que llençarem tot seguit.
Exemple de captura d'excepcions per encapsular-les dins una nova excepció
Imaginem que hem creat una excepció anomenada ServicesException i que tenim un mètode amb codi susceptible de llançar IOException. Una possible implementació pot ser:
Suport de la concurrència de clients
Una de les solucions per aconseguir que un servidor pugui atendre diversos clients a la vegada consisteix en realitzar l’execució de cada client en un fil a part (vegeu la figura).

Es tracta d’un solució força senzilla si seguim els patrons dissenyats a les figures de figura a figura. Prenent una implementació qualsevol d’un servidor TCP haurem d’afegir la funcionalitat específica del ServiceManager i també agrupar la corresponent al Service en una classe Runnable que es pugui executar en un fil apart.
La implementació de les interfícies no cal ubicar-la en classes independents. Cal valorar en cada cas l’esforç que representa cada alternativa i condicionar-hi la decisió. L’avantatge que representa l’implementació en classes diferents és que resultarà sempre molt mes fàcil fer-hi canvis. Tot i així, si prenem la precaució de seguir sempre les interfícies definides, fins i tot la divisió d’una classe en diverses pot resultat una tasca relativament senzilla i gens traumàtica.
La implementació del ServiceManager implica afegir una llista de serveis per poder gestionar-los quan calgui tancar-los com a atributs de la classe que implementi la interfície. També caldrà resoldre els mètodes addService, closeServices i updateServices:
Mantenint la funcionalitat del ServiceManager ben localitzada podem implementar noves solucions quan calgui. Per exemple si observem que el nombre de connexions concurrents augmenta fins a alentir el servidor, podem limitar el nombre de fils actius i emmagatzemar les peticions que desbordin la llista, en una cua de serveis pendents d’atendre. A mesura que vagin tancant els serveis es consultarà la cua i s’atendrà el primer servei que es trobi esperant. O potser si els temps d’espera fossin massa llargs caldria pensar en una sistema més distribuït en el qual l’atenció es pogués derivar a d’altres servidors especialitzats només en l’atenció dels serveis, etc.
El Service, si volem que suportar la concurrència, caldrà implementar-lo en una classe independent que implementi la interfície Runnable. Aquí suposarem que disposem d’una classe Protocol que gestionarà la comunicació client servidor.
La resta d’implementacions, el Protocol i el Solver dependran força del tipus de servei que estem implementant, però si seguim uns criteris semblants als aplicats aquí, ens resultarà relativament fàcil poder fer modificacions a mesura que sigui necessari.