


Programació de comunicacions en xarxa
Actualment és impossible concebre cap dispositiu de processament de la informació (sigui ordinador, mòbil, llibre electrònic…) sense capacitat per comunicar-se. La gran majoria d’aplicacions actuals necessiten una connexió per instal·lar-se o per actualitzar-se i una bona part d’elles la necessiten també per a poder-se executar amb normalitat.
Sovint les aplicacions treballen amb recursos al núvol o extreuen les dades d’un SGBD situat en un servidor remot. Gràcies a la connectivitat dels nostres dispositius podem veure pel·lícules sense haver d’emmagatzemar-les en un disc local, podem sincronitzar els rellotges amb l’hora oficial, comprar entrades per anar al teatre sense moure’ns de casa o fer una partida en línia del nostre videojoc preferit. Tota aquesta capacitat de comunicació només és possible gràcies a les xarxes.
L’objectiu principal de les xarxes és el d’interconnectar diversos dispositius per tal de compartir totalment o parcialment els seus recursos.
Què són els protocols
Els protocols són especificacions que defineixen quin ha de ser el comportament de les diferents parts d’un sistema. En concret, els protocols de comunicació a través de la xarxa descriuen el paper de tots els elements de la xarxa (siguin físics o lògics) implicats en la intercomunicació.
Per aconseguir la interconnectivitat dels dispositius, les xarxes han anat definint elements estàndards físics (encaminadors, commutadors, concentradors…) o lògics (protocols i biblioteques de comunicació) per tal que les aplicacions puguin accedir als recursos remots fàcilment, reduint tant com sigui possible la complexitat de la implementació. Això ha permès crear aplicacions distribuïdes cada cop més transparents a l’usuari.
Entenem per aplicació distribuïda aquella que s’executa en més d’un dispositiu. Entenem per aplicació distribuïda transparent aquella aplicació distribuïda que no necessita un tractament especial pel fet d’estar distribuïda o, si més no, el redueix considerablement.
Des del punt de vista del programador el concepte de transparència s’aplica en referència a la menor quantitat de codi que caldrà escriure fent servir eines i biblioteques que automatitzin els processos bàsics de comunicació dins la xarxa.
L’evolució d’Internet ha permès també, la creació d’una única xarxa de comunicació en la qual tots els dispositius o xarxes inicialment aïllades (locals) adquireixen la capacitat d’interactuar. S’encunya així el terme de xarxa global. L’èxit de la xarxa global fa aparèixer nous elements estàndards que avancen en la línia de la programació distribuïda transparent.
Aspectes teòrics de la comunicació
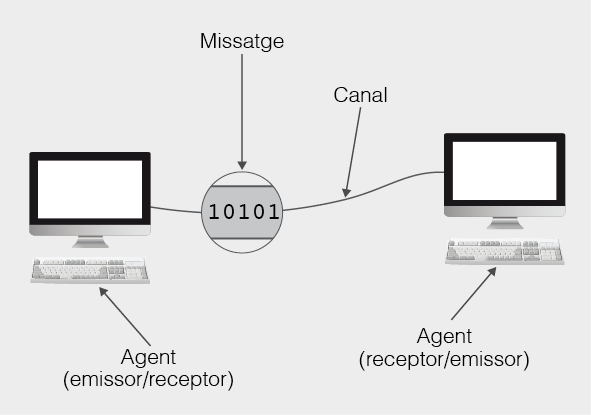
La comunicació és un procés complex en el qual es produeix una transferència d’informació entre agents independents. És important subratllar el terme independents perquè això implica que cada agent disposa del seu propi sistema d’informació que no comparteix de forma directa ni simple amb cap altre agent.
Per tal que la comunicació sigui possible és necessari que els agents comparteixin una mateixa manera de representar la informació tot i que aquesta no té perquè coincidir amb la representació interna que cada agent manté. Cal també que els agents tinguin òrgans o dispositius funcionals propis que els permetin d’una banda generar representacions comunes d’una part de la informació que mantenen i de l’altra interioritzar les representacions elaborades per altres agents. La part d’informació que es transmet s’anomena missatge.
El missatge es representa per mitjà de codis i símbols. Per això anomenarem codificació al procés de representar la informació d’una manera concreta. El missatge, codificat d’alguna manera comuna, arriba als agents a través del medi pel qual es transmet. Parlem de medis per referir-nos als mitjans que suporten la transmissió de la informació. L’agent que genera una representació i la traspassa al medi s’anomena emissor. L’agent que rep la informació a través d’un medi s’anomena receptor. Quan la informació elaborada per un agent emissor arriba a un agent receptor a través d’algun medi direm que entre ells s’ha establert un canal de comunicació per abstraure i emfatitzar el procés de traspàs.
El procés d’elaboració i el d’interpretació de la informació que duen a terme els agents emissors i receptors respectivament no són processos passius, requereixen de l’atenció dels agents en ambdós casos. Malgrat que depèn de les situacions, els agents implicats en la comunicació poden alternar els seus papers d’emissors i receptors donant lloc a un diàleg (vegeu la figura).
Els agents digitals, com ara els ordinadors o d’altres dispositius, necessiten que se’ls especifiqui una instrucció per escoltar els missatges que arribin del medi.
Rols client i servidor
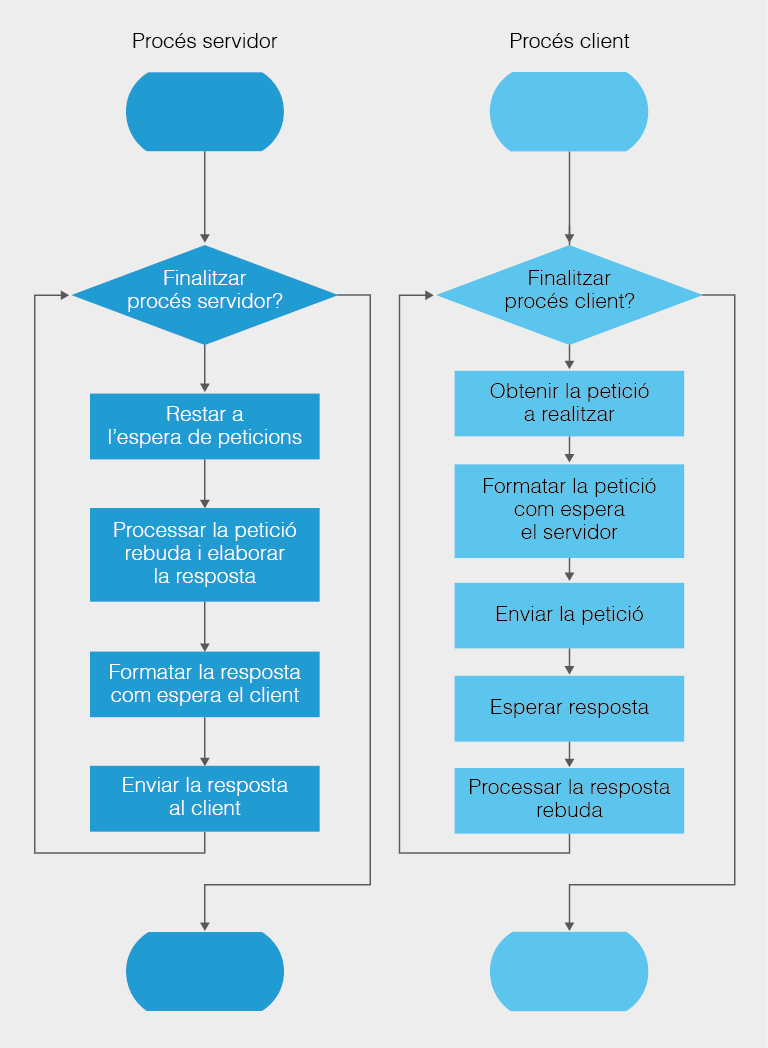
La forma més clàssica de comunicar dispositius digitals és aplicant el model de client-servidor. El servidor és un dispositiu que conté informació a compartir amb altres agents anomenats clients, però no sap quan els clients necessitaran la seva informació. Per això el servidor haurà d’estar escoltant a l’espera que algun client li faci una petició, demanant quina part de la informació necessita. La petició és emesa per un client i codificada de tal forma que el servidor la pugui interpretar. Quan el missatge arriba al servidor, aquest detecta que la petició és per ell, la interpreta, genera la resposta adient i l’envia al client peticionari. Un cop resolta la demanda, el servidor quedarà de nou a l’espera de noves peticions.
Actualment moltes aplicacions segueixen models mixtes en què els dispositius poden fer de clients i servidors a la vegada, així permeten una major distribució de les dades i dels processos i aconsegueixen un abaratiment del maquinari. Tot i això, els papers de servidor i client no s’han perdut sinó que conviuen en un mateix dispositiu, sovint com a processos independents executats a l’hora.
No s’ha de confondre tampoc el rol del servidor amb el del receptor, ja que el servidor a més de rebre les peticions dels clients les ha de processar, obtenir-ne una resposta i enviar-la de tornada al client (vegeu la figura). El client per la seva banda, com podeu observar a la part dreta de la mateixa figura, ha de detectar quina petició necessita realitzar, ha de fer l’enviament de la petició, quedar-se a l’espera de la resposta i, quan arribi, processar-la adequadament. Noteu que aquest procés s’ha tancat dins d’un bucle continu per denotar que el client podria estar fent peticions de forma cíclica, però no ha de ser sempre així. Podria donar-se el cas d’un procés client que s’executi una única vegada. Per això a l’esquema les fletxes del bucle i el símbol condicional s’han difuminat indicant la seva opcionalitat.
Bases de la comunicació entre aplicacions
Segurament, una de les claus que ha propiciat el creixement espectacular de l’ús de les xarxes durant el darrer quart del segle XX ha estat la senzillesa sobre la qual la commutació de paquets suporta la seva connectivitat. Aquesta tecnologia presenta certa analogia amb el sistema de lliurament de cartes postals. Les cartes s’envien dins de sobres que són els que duen la informació per fer-la arribar al seu destí.
-

- Font: Parée
A les xarxes informàtiques, la informació que cal transmetre s’embolcalla dins de “paquets virtuals” en els quals s’hi referencien totes les dades necessàries per tal que la informació arribi al seu destí sense perdre’s (dispositiu origen, dispositiu destí, aplicació a la qual va dirigida, servei demandat, etc.).
Per tal que la informació es pugui compartir a través d’una xarxa global cal que tots els dispositius i elements de la xarxa facin servir el mateix sistema d’empaquetatge. Internet fa servir un sistema molt senzill anomenat protocol IP. La gran senzillesa d’aquest sistema és el que ha permès la seva proliferació tan ràpida, ja que els costos d’implementació dels nodes intermedis de la xarxa són considerablement reduïts.
El protocol IP és tan simple que no contempla cap procés de control per verificar que la informació arriba realment al seu destí de forma complerta. És per això que la majoria de serveis i aplicacions d’Internet afegeixen un protocol extra de control anomenat TCP. Ambdós protocols es complementen tan bé que han passat a constituir el nucli central de la connectivitat d’Internet sota el nom de TCP/IP.
Arquitectura d'Internet: una estructura de capes
Els processos d’una comunicació són aquells que permeten als dispositius generar, transmetre i rebre un conjunt de senyals seqüenciats d’acord amb una convenció comuna de manera que el receptor sigui capaç d’interpretar allò que l’emissor vol comunicar.
Per a la generació, la transmissió i la recepció dels senyals es fan servir elements físics com ara les targes de xarxes o els cables. Aquests elements constitueixen la capa més baixa de la comunicació i solen anomenar-se capa física. El control dels elements físics recau sobre la capa immediatament superior, anomenada capa d’enllaç perquè també gestiona la transmissió d’informació entre dos nodes. La capa d’enllaç inclou elements lògics com ara els controladors de les targes de xarxa i també protocols d’accés, de transmissió i de recepció dels senyals. Ethernet/CSMA/CD és el protocol més estès, malgrat que podem trobar-ne d’altres.
Les dues capes esmentades, la física i la d’enllaç, aconsegueixen aglutinar bona part dels processos rutinaris de la comunicació i eliminar tota la complexitat atribuïble a la generació, recepció i transmissió dels senyals. Això allibera a les capes superiors d’una tasca de certa complexitat i permet així, simplificar la seva implementació.
Per sobre de la capa d’enllaç trobem la capa que gestiona l’adreçament entre nodes distants. Aquesta capa s’anomena també capa de xarxa i el protocol usat a Internet per gestionar l’adreçament és el protocol IP (Internet Protocol). En aquest nivell els diferents nodes de la xarxa global són capaços de decidir per quin camí cal enviar els paquets rebuts per tal que arribin al seu destí. Aquestes tres capes (física, enllaç i xarxa) han d’estar disponibles en qualsevol dels nodes de la xarxa global per tal de gestionar la transmissió d’informació entre dispositius.
El protocol IP s’encarrega només de l’adreçament dels paquets transmesos, però no pas del control de la transmissió. En una xarxa global com ara Internet, amb milions de nodes interconnectats, les incidències durant les transmissions solen ser força habituals, ja sigui per interpretació errònia del senyal, per congestió, per caiguda o per manteniment d’algun node. Les incidències poden provocar l’arribada de dades errònies, retards o, fins i tot, la pèrdua d’alguns paquets; tot de conseqüències que poden acabar dificultant i, en darrer terme, impedint la comunicació real entre els dispositius. És per això que cal una capa més per controlar la qualitat de les transmissions. Aquesta capa s’anomena capa de transport.
La capa de transport s’implementa només sobre nodes terminals (dispositius origen i destí), mai sobre els nodes intermedis de la xarxa. Aquesta característica presenta certs avantatges i desavantatges. El principal avantatge és el fet d’abaratir els dispositius intermedis, ja que la implementació d’un protocol de control presenta un grau de dificultat realment molt més elevat que la simple implementació del protocol IP. També presenta l’avantatge de poder usar diversos protocols de control, ja que només hi estan implicats els nodes finals. És a dir, només cal posar d’acord dos nodes abans d’iniciar la transmissió. De fet, a Internet solen fer-se servir principalment dos protocols de control, el protocol UDP i el protocol TCP.
TCP és l’acrònim de Transmission Control Protocol i UDP d’User Datagram Protocol.
UDP és un protocol de control força senzill, només controla la integritat dels paquets enviats. Això vol dir que l’utilitzen aquelles aplicacions que no necessiten mantenir cap ordre en l’arribada de la informació i en la qual ni la pèrdua d’alguna dada impedeix el normal funcionament. El protocol TCP, per contra, és un protocol molt més sofisticat que gestiona el control de l’ordre i també la pèrdua de paquets a més de la integritat de la informació.
El principal desavantatge de relegar el control als nodes finals és que les errades no es detecten fins que la informació ha creuat tota la xarxa i ha arribat al node destí. Si es detecta alguna distorsió és necessari avisar a l’origen que torni a enviar de nou les dades. Com es pot imaginar, això acaba traduint-se en un augment de tràfic per la xarxa.
Malgrat que per sobre de la capa de transport poden anar-se sobreposant tantes capes com sigui necessari, aquestes depenen molt de l’aplicació executada. Podem trobar aplicacions que requereixin un canvi de format de les dades abans de ser enviades o en rebre-les o bé que necessitin afegir dades específiques pròpies del sistema o d’una configuració específica. No es pot, però, considerar un tractament universal. És per això que sol simplificar-se l’esquematització amb una única capa anomenada capa d’aplicació.
La capa d’aplicació conté la funcionalitat pròpia de l’aplicació específica que cal executar i és la capa en la qual comença i acaba tot el procés de comunicació. Quan des d’un dispositiu terminal, una aplicació necessita enviar informació a un altre dispositiu del qual suposarem que es coneix la seva adreça, la capa d’aplicació donarà el format adequat a les dades que s’han d’enviar i les passarà, juntament amb l’adreça en la qual cal fer l’enviament, a la capa de transport. Aquesta capa afegirà dades que facilitaran el control de la transmissió i deixaran les dades en mans de la capa de xarxa, en la qual s’hi escriuran les adreces d’origen i destí (la darrera, rebuda des de la capa d’aplicació a través de la capa de transport). La capa d’enllaç afegirà noves dades per aconseguir que tota aquesta informació arribi al node més proper situat en el camí que porta al dispositiu destí i activarà els elements físics per tal que generin el senyal corresponent a tota la informació que s’ha anat generant (vegeu figura).
Un cop el senyal es troba en el medi físic, el node intermedi al qual s’ha enviat el senyal escoltarà i interpretarà la informació des de la seva capa d’enllaç. La informació es traslladarà a la capa de xarxa per tal de decidir quin serà el següent node al qual cal fer l’enviament, per tal d’aconseguir arribar al dispositiu destí. Un cop decidit, es tornarà a la capa d’enllaç des de la qual es generarà de nou el senyal adreçat al següent node intermedi. Aquest procés es repetirà tantes vegades com sigui necessari fins arribar al dispositiu destí (vegeu figura).
Quan el senyal arriba al dispositiu destinatari, es detecta com a pròpia la informació llegida comprovant l’adreça IP del destí i, en comptes de fer un nou reenviament des de la capa de xarxa, es trasllada a la capa de transport. Aquesta capa verificarà que la informació ha arribat correctament i només en cas afirmatiu pujarà les dades rebudes a la capa d’aplicació que les interpretarà i actuarà en conseqüència (vegeu figura). Si la capa de transport detecta alguna errada o distorsió en les dades rebudes, caldrà demanar a l’origen que torni a enviar les dades.
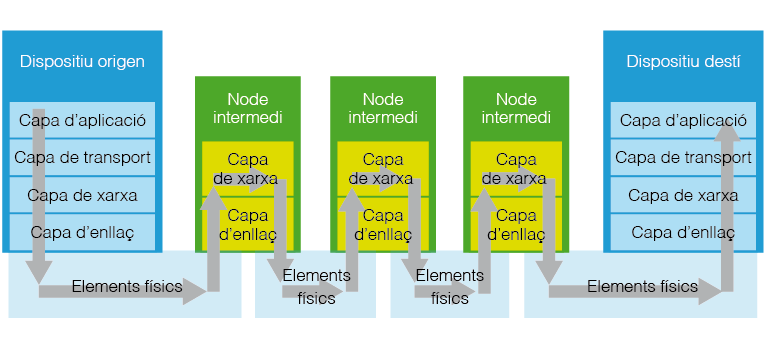
En l’esquema de la figura es poden observar les diferents capes en què s’estructura la comunicació en una xarxa global com Internet. També es pot apreciar el flux d’informació a través de les capes des del dispositiu origen fins arribar al destí, passant per diversos nodes intermedis. Observeu com els nodes intermedis no implementen les capes superiors a la de xarxa.
Capçaleres i dades
Es pot veure ràpidament que la quantitat d’informació enviada pot acabar superant àmpliament la quantitat de dades originals, ja que cada capa afegeix informació extra que serà útil per la gestió. El procés invers en el qual la informació rebuda ascendeix des de les capes baixes pateix una transformació similar però a l’inrevés. És a dir, a cada pas s’elimina la part d’informació específica del nivell en qüestió i només es passa a la capa superior la informació que li és pròpia. A la figura podeu veure el detall d’ambdós processos (d’enviament i recepció). Les dades extres es localitzen en una capçalera per tal que sigui fàcil d’afegir, d’eliminar i de llegir.
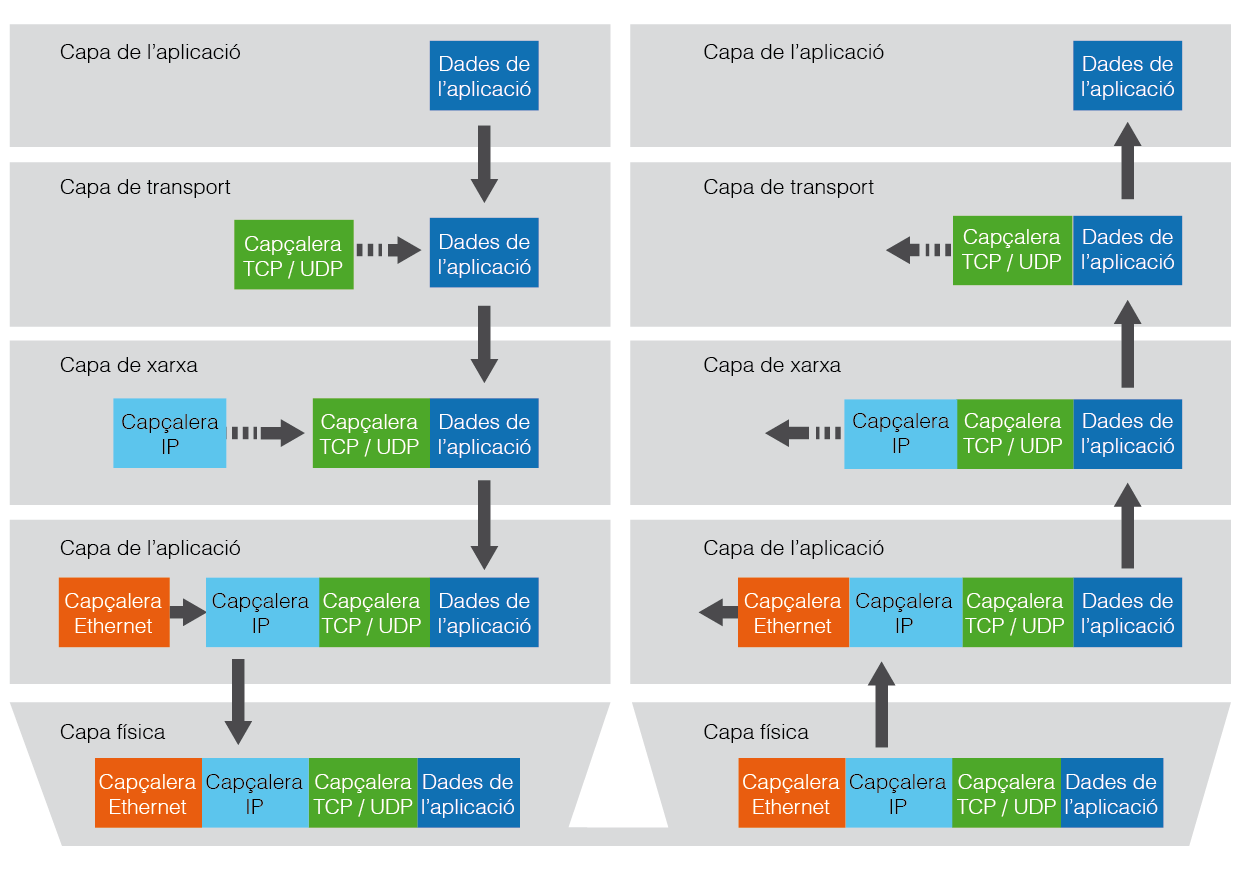
En l’esquema de la figura podeu observar com, per aconseguir enviar certa informació (les dades de l’aplicació), cada capa ha d’anar afegint les seves dades extres en una capçalera de mida fixa. També podeu observar el procés contrari. En rebre les dades, cada capa elimina la seva capçalera per tal de passar a la capa superior les dades corresponents netes.
Fixeu-vos que cada capa només tracta els bytes de la seva capçalera, situats sempre a l’origen de les dades. Coneixent la mida de la capçalera es pot aconseguir un tractament raonablement eficient. És important que el tractament no sigui excessivament costós, ja que, com es pot suposar, qualsevol enviament repetirà els processos de recepció/enviament a cada node pel qual passi. Sortosament, els nodes intermedis no sobrepassen mai la capa de xarxa, cosa que alleuja força el procés de transmissió. Recordeu que la capa de transport només es fa efectiva en els dispositius finals.
Contingut de la informació a cada capa
Sovint la capa d’aplicació formata d’una manera concreta les dades a enviar i segueix un protocol establert per tal de fer factible la comunicació entre els dispositius implicats. Es tracta que l’emissor posi en circulació la informació de tal manera que els receptors puguin interpretar les dades que els arriben. Malgrat que en aquest nivell existeixen una gran quantitat de protocols estàndard com ara HTTP, FTP, TELNET i molts d’altres, n’hi ha prou amb fer servir una convenció comuna entre dispositius finals. L’ús de protocols estàndards, però, pot arribar a facilitar molt la implementació de les aplicacions, ja que la majoria de llenguatges disposen de biblioteques i utilitats d’alt nivell específiques per aquests protocols.
Capa de transport
Els principals protocols usats en aquest nivell són UDP i TCP. Abans de poder veure els camps que composen les dades extres d’aquesta capa, cal analitzar quines són les seves funcions. Es tracta de la capa situada immediatament per sota de les aplicacions. Durant la recepció de les dades, necessitarà reconèixer quina és l’aplicació destinatària de la informació ja que, per descomptat, podria donar-se el cas de tenir diverses aplicacions independents esperant dades. Per convenció, la capa de transport farà servir un número per identificar les diverses aplicacions que es trobin escoltant. Habitualment es coneix aquest número identificatiu amb el nom de port. A cada enviament, caldrà incloure sempre el valor del port com a dada extra de la capa. Així el receptor podrà esbrinar quina és l’aplicació destinatària.
S’utilitzen 2 bytes per identificar el port. Això significa que hi ha 65.535 ports disponibles en cada dispositiu. Potencialment existeix, doncs, la possibilitat d’executar de forma concurrent la mateixa quantitat d’aplicacions en un únic dispositiu. A la pràctica el nombre de ports útils es redueix força, però continua sent més que suficient.
La reducció del nombre de ports és un conseqüència de la següent convenció:
- Els valors de ports que oscil·len entre 1 i 1.023 es reserven per aplicacions específiques i estàndards. El port que usen els servidors de pàgines web és un port 80, per exemple. De fet cada un dels serveis estàndards d’Internet (correu electrònic, FTP, DNS, etc.) tenen associats ports únics i diferents. Per això en una mateixa màquina podem instal·lar-hi tots els serveis disponibles i fer peticions des de qualsevol client sense necessitat que ens informin prèviament del port que estan escoltant.
- Els port que es troben entre el valor 1.024 i 49.151 cal destinar-los a serveis no estàndards. És a dir, a servidors que es trobin permanentment escoltant les peticions que els arribin. Per tal que el client pugui connectar-s’hi haurà de saber prèviament el número del port que el servei utilitza. Les aplicacions corporatives, com ara els sistemes gestors de bases de dades, són un clar exemple d’aquests serveis. A les empreses no els interessa fer públic el port d’accés a les dades. Només als clients de la corporació els cal saber el port al qual han d’adreçar les seves peticions.
- Finalment els ports que es troben entre els valors 49.152 i el 65.535 es destinen a comunicacions temporals dels clients i seran assignats directament per la capa de transport en el moment d’iniciar una comunicació.
Protocol UDP
Algoritmes de suma
Un algoritme de suma és aquell que obté un resultat operant sobre una conjunt de bytes, de manera que el valor obtingut no sobrepassa mai un valor màxim i que la probabilitat d’obtenir valors idèntics a partir de conjunts de bytes diferents és el més petita possible.
Trobareu informació sobre els algoritmes de suma a l’apartat “Tecnologies de seguretat i encriptació” de la unitat Seguretat i criptografia.
A més a més dels ports origen i destí, la resta de dades extres d’aquest nivell vindran determinades pel protocol utilitzat. UDP és més senzill que TCP perquè únicament comprova la coherència de les dades rebudes. UDP utilitza la longitud de les dades i un valor de comprovació anomenat checksum per a realitzar la verificació de la coherència. El valor checksum s’obté a través d’un algoritme de suma que porta el mateix nom.
L’algoritme checksum consisteix en sumar un conjunt de bytes agrupats en blocs de 16 bits (2 bytes). En tractar-se d’una suma, el resultat que obtindríem en qualsevol dels possibles casos podria representar-se sempre amb un màxim de 17 bits. En aquells casos que el resultat de la suma necessiti 17 bits, s’elimina el bit més significatiu (el de més a l’esquerra) per tal d’ajustar sempre la mida a 16 bits i s’incrementa el valor en una unitat.
Exemple de càlcul del valor checksum d'un conjunt de byte
Tenim el següent conjunt de 8 bytes: 138,40,37,218,117,162,42,21 Quan el traslladem a binari obtenim:
10001010 00101000 00100101 11011010 01110101 10100010 00101010 00010101
Agrupem el conjunt en blocs de 16 bits:
valor binari valor decimal
10001010 00101000 35368
+ 00100101 11011010 9690
+ 01110101 10100010 30114
+ 00101010 00010101 10773
------------------------------------
1 01001111 10111001 85945
Com que el resultat de la suma hauria d’ocupar 17 bits, mantindrem els 16 bits menys significatius i incrementarem el resultat una unitat:
valor binari valor decimal
0100111110111001 20409
+ 1 1
--------------------------------------------------
0100111110111010 20410
El resultat final després d’aplicar l’algoritme checksum són 2 bytes de valor:
01001111 10111010
Si usem una expressió decimal, aquest es correspondria amb: 79,186
Aquestes quatre dades que UDP afegirà, se seqüencien, tal com es mostra a la figura. Cada una d’elles ocupa 16 bits i se situen per davant de les dades a mode de capçalera.
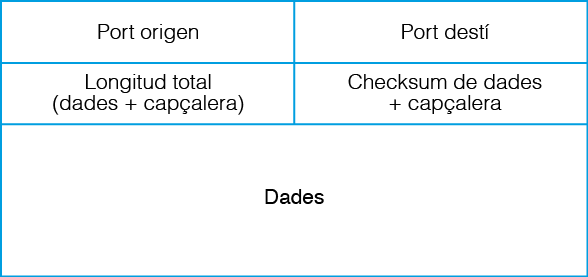
Durant la rebuda de la informació el protocol UDP extreu les dades de la capçalera i comprova si la longitud i el valor checksum coincideixen amb les dades rebudes. En cas afirmatiu, traspassa les dades a l’aplicació corresponent d’acord amb el port indicat com a destí. En cas que la longitud o el checksum siguin incoherents es descarten les dades com si mai haguessin arribat.
Tal com es pot deduir, UDP ofereix molt poques garanties de qualitat. Només garanteix que en cas de lliurar alguna dada, aquesta serà consistent. Tot i això, es tracta d’un protocol molt ràpid que necessita veritablement molt pocs recursos per mantenir una gran quantitat de comunicacions ràpides i amb múltiples clients. Per això es troba àmpliament implementat en aplicacions concorregudes que necessiten fer prevaler la velocitat per sobre de la qualitat, com ara els servidors DNS o els serveis de veu IP o l’streaming de vídeo.
Protocol TCP
Les aplicacions que necessitin fiabilitat en les transmissions hauran de fer servir el protocol TCP. Es tracta d’un protocol de gran complexitat amb el qual es garanteix que totes les dades enviades des de l’origen, arriben al destí íntegrament i en el mateix ordre en què han sortit de l’emissor.
Per tal d’assegurar la fiabilitat de la transmissió, el protocol TCP manté un diàleg permanent entre emissor i receptor, en el qual ambdós dispositius s’informen d’allò que van enviant i rebent. El diàleg s’inicia amb una petició de connexió i es manté obert (ambdós dispositius s’escolten mútuament) fins que un dels dos enviï un senyal per finalitzar la connexió.
Es diu que el protocol TCP està orientat a la connexió perquè manté un diàleg permanent entre l’emissor i el receptor. En canvi el protocol UDP no està orientat a la connexió perquè un cop enviades les dades l’emissor es desentén de la transmissió.
L’explicació en tot detall del protocol TCP sobrepassa l’objectiu d’aquest mòdul. Sovint disposarem de biblioteques ja implementades que ens permetran gaudir d’aquesta tecnologia sense necessitat d’haver-les d’implementar. Malgrat tot, és important conèixer quines són les seves principals característiques per entendre el comportament d’aquestes biblioteques i per decidir quin protocol serà l’adequat per les aplicacions que ens toqui desenvolupar.
Característiques de la comunicació entre dos dispositius usant el protocol TCP
TCP és un protocol pensat per comunicar només dos interlocutors. Les aplicacions que necessitin transmetre a múltiples dispositius hauran d’escollir entre aplicar el protocol UDP, amb el risc de pèrdua d’informació que això suposa, o bé implementar múltiples connexions dos a dos amb les quals poder controlar a través de TCP la transmissió.
Aplicant el protocol TCP, abans d’iniciar qualsevol transmissió de dades caldrà establir una connexió entre dues màquines. Per aconseguir la connexió caldrà establir un petit diàleg entre ambdós dispositius en el qual un d’ells enviarà un senyal específic anomenat petició. L’inici de la connexió implicarà la reserva d’un port en cada dispositiu destinat exclusivament al diàleg i a la transmissió de les dades entre els dos interlocutors implicats. És per això que el protocol exigeix que ambdós dispositius s’enviïn mútuament un senyal d’acceptació de la connexió indicant que el port està reservat i que la comunicació pot començar. El port es mantindrà reservat fins que un dels interlocutors decideixi abandonar la comunicació iniciant un diàleg per finalitzar la connexió.
Diem que TCP és un protocol full-duplex perquè estableix dos canals de comunicació en cada connexió, cada un en un sentit diferent. És a dir, es manté un canal de transmissió des del dispositiu A al dispositiu B independentment del canal de transmissió que vagi del dispositiu B al dispositiu A. A la pràctica això implica que cada dispositiu manté un registre del qual envia i rep de forma independent.
Diem també que els canals de la connexió estan orientats a fluxos (streaming-oriented). És a dir, el registre mantingut per cada dispositiu de les dades enviades i rebudes serveix, entre d’altres coses, per determinar l’ordre en què han sortit les dades i poder organitzar les dades rebudes en el mateix ordre abans de traspassar-les a la capa d’aplicació. Sovint les limitacions de la xarxa impedeixen enviar les dades en un únic bloc. En aquests casos el protocol TCP permet dividir els enviaments en segments més petits en els quals cada un d’ells contindrà parcialment les dades a enviar. Si els dispositius es troben a certa distància, cada segment podria agafar camins diferents i arribar a destí de forma desordenada. El protocol TCP envia, juntament amb les dades, un valor extra que permetrà ordenar les dades de cada segment.
El valor que permet l’ordenació és un comptador dels bytes enviats de manera que el receptor pugui reconstruir el flux de dades fàcilment malgrat l’ordre d’arribada dels segments. Això implica que el receptor no pot traspassar les dades dels segments a l’aplicació conforme vagin arribant, sinó que haurà de mantenir un buffer en el qual reconstruirà totes les dades abans de fer el traspàs a la capa superior.
Per tal d’assegurar la fiabilitat de les dades, el protocol estableix que per cada segment enviat des d’un o altre dispositiu, el receptor contestarà amb un senyal especial de reconeixement que indiqui a l’emissor que les dades del segment han arribat amb èxit. El senyal de reconeixement inclou un valor que identifica la porció de bytes rebuda en segments fent servir el valor del comptador de bytes.
D’aquesta manera emissor i receptor poden anar interpretant si la transmissió va tenint èxit, o si cal fer un nou reenviament d’algun segment, ja sigui perquè no s’ha rebut el seu senyal de reconeixement, cosa que faria suposar la pèrdua parcial d’alguns segments o com a conseqüència d’haver rebut un reconeixement amb un identificador repetit, cosa que suposaria l’arribada corrupte de dades.
En distàncies llargues, el temps comptabilitzat des del moment de l’enviament d’un segment fins a rebre el seu reconeixement, pot arribar a ser força elevat. Si l’emissor hagués d’esperar l’arribada dels reconeixements abans d’enviar un nou segment, la transmissió podria fer-se impracticable a causa de la lentitud. Per tal d’evitar-ho es permet fer enviaments de diversos segments sense haver rebut la corresponent confirmació.
Aquest biaix entre les dades enviades i les dades confirmades obliga a disposar d’algoritmes que dedueixin en cada moment l’estat de la transmissió i puguin actuar en conseqüència per tal de fer reenviaments quan calgui, demanar una nova sincronització de les dades a transmetre a partir d’un determinat segment o fins i tot canviar la freqüència d’enviament dels segments per tal que el nombre de segments sense confirmar no augmenti perillosament.
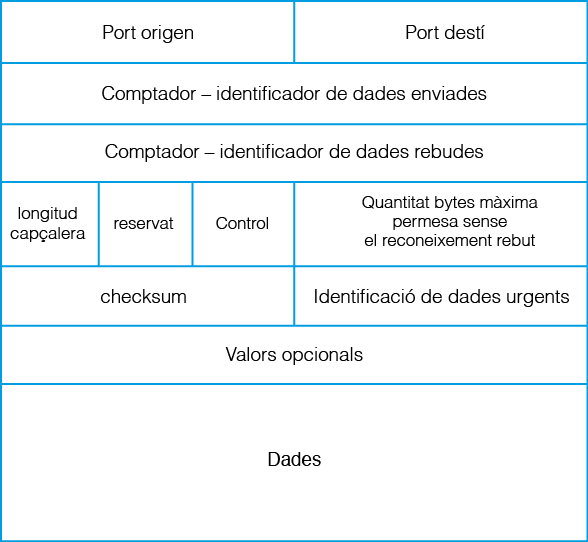
Les dades que el protocol TCP estableix per aconseguir les característiques descrites les podeu observar a la figura. Com podeu veure, la quantitat de dades necessàries aquí és força superior a les usades en el protocol UDP. A banda dels ports origen i destí o del checksum de verificació de la integritat del segment, la resta de dades són específiques de TCP. Destaquem els identificadors dels bytes enviats o rebuts que també actuen com a comptadors ja que es van incrementant en funció dels bytes enviats o rebuts correctament. Destaquem també que en aquest protocol només es transmet la longitud de la capçalera ja que la longitud de les dades es pot deduir usant l’identificador-comptador de les dades enviades.
El camp de control permet donar informació extra de les dades de la capçalera o de l’estat de la transmissió. Per exemple permet indicar que certes dades són importants i cal processar-les i enviar-les a l’aplicació abans que la resta o demanar un nova sincronització de les dades i forçar un enviament a l’aplicació de les dades arribades fins el moment, etc.
Capa de xarxa
IP és l’acrònim d’ Internet Protocol
Topologia de xarxa
La topologia d’una xarxa fa referència a la interconnexió directa que cada node té amb la resta. Diem que dos nodes es troben connectats directament quan poden enviar-se informació sense passar per cap altre node. La topologia influencia el trànsit que la xarxa és capaç de suportar.
La capa de xarxa fa servir el protocol IP per aconseguir connectar dos dispositius de la xarxa amb independència de la distància que hi hagi entre ells. Per aconseguir la connexió caldrà esbrinar quins nodes intermedis condueixen al dispositiu destí. En cas que hi hagi més d’un camí per arribar-hi, caldrà escollir-ne un. La decisió no és trivial ni absoluta perquè una xarxa de comunicacions no és quelcom immutable. La capacitat de connexió de la xarxes va variant a cada instant depenent d’aspectes tan volàtils com ara la quantitat de trànsit global que hi circuli o les decisions que altres nodes hagin pres amb anterioritat. Per descomptat depenen també d’aspectes estàtics com ara la topologia o l’eficiència dels recursos físics.
En una xarxa com Internet el camí no es planifica des de l’origen sinó que cada node pel qual passa el missatge a transmetre pren la seva decisió pròpia. La capa de xarxa dels nodes intermedis intenta esbrinar cap on encaminar el missatge de manera que arribi el més aviat possible al destí. En la presa de decisió caldrà tenir en compte aspectes com ara quin pot ser el camí més curt, quin camí es troba menys congestionat o quin retard porta acumulat el missatge.
Adreçament IP
Les adreces IP identifiquen les connexions directes d’un dispositiu de manera única. Un dispositiu pot disposar d’una o diverses connexions a través de les quals enviar i rebre els missatges. En tractar-se d’un valor únic a tota la xarxa s’utilitzen també per identificar els dispositius, malgrat que en realitat un dispositiu tindrà sempre tants identificadors com connexions tingui.
Generalment les connexions directes es coneixen com a interfícies de xarxa i s’identifiquen amb les targes de xarxa. Malgrat tot, a vegades s’opta per fer emulacions a través del programari. És el que es coneix com a interfícies de xarxa lògiques. Per exemple els sistemes operatius (SO) disposen de l’adreça 127.0.0.1 per identificar el dispositiu propi en el qual l’SO s’executi. Aquesta adreça IP s’anomena també adreça loopback perquè mai surt del dispositiu cap a la xarxa sinó que es retorna cap a la capa superior com si acabés d’arribar dirigida al propi dispositiu.
Col·laboració entre nodes
Els nodes col·laboren entre ells creant petits mapes a la xarxa per tal de poder decidir cap on adreçar els paquets que arriben des de diferents orígens a través de les seves interfícies de xarxa. A vegades els nodes demanen als seus veïns que s’identifiquin explicitant la seva adreça IP. Això els permet crear petites llistes associades a cada una de les interfícies. També és comú informar als veïns de les llistes d’adreces que un node és capaç de cobrir, indicant a més la llunyania a la qual es troben les diferents adreces IP de la llista. Per últim, el nodes disposen també de certes regles d’adreçament prefixades que ajuden a acabar de prendre les decisions d’adreçament dels paquets.
Una regla prefixada podria ser, per exemple, definir una interfície de xarxa per defecte, de manera que qualsevol adreçament que no figuri a cap llista es desviarà sempre per la mateixa sortida. Això té força sentit, ja que alguns nodes d’Internet són el que s’anomena súper-hubs, és a dir, nodes amb moltes connexions, de manera que la probabilitat que aconsegueixin resoldre l’adreçament és molt més gran que la majoria de les alternatives restants.
També és habitual definir regles que adrecin els paquets d’acord amb els bytes més significatius de les seves adreces. D’aquesta manera s’aconsegueix definir rangs d’adreces associats a una o altra interfície de xarxa. Efectivament, sovint les adreces IP que comencen per un valor es troben concentrades físicament en una regió propera o pengen d’un mateix node capaç d’adreçar-les. Les operacions necessàries per determinar si una adreça IP es troba o no dins d’una rang determinat són tan senzilles i ràpides que els dispositius són capaços d’avaluar un gran nombre de regles de forma molt eficient.
Totes aquestes accions descrites tenen com a objectiu segmentar la xarxa i crear mapes específics per a cada node per tal de poder establir un conjunt de regles senzilles que determinin quina interfície de sortida serà la millor opció per transmetre un paquet cap al seu destí.
Adreces i màscares
Les adreces IP són en el fons una seqüència de bits sobre la qual es poden fer operacions binàries. Aquesta és una característica molt útil perquè ens permet definir rangs d’adreces i determinar d’una forma molt ràpida si una adreça qualsevol es troba dins del rang. Per definir el rang utilitzarem una màscara i una adreça de xarxa base.
Una màscara és una seqüència de bits de la mateixa mida que una adreça IP, però organitzada de manera peculiar. Hi ha un nombre indeterminat de bits més significatius (els que es troben més a l’esquerra de la seqüència binària) que sempre prenen el valor 1, mentre que la resta de bits, els menys significatius (que localitzem a la dreta del conjunt d’uns) prenen sempre el valor 0.
Exemples de màscares
Podeu apreciar perfectament el conjunt d’uns que ocupen els bits més significatius i el conjunt de zeros que ocupen el bits menys significatius.
255.255.0.0la representació binària del qual és11111111 11111111 00000000 00000000255.255.192.0la representació binària del qual és11111111 11111111 11000000 00000000255.255.255.240la representació binària del qual és11111111 11111111 11111111 11110000
Una adreça IP base és aquella que, combinada amb una màscara, permet definir un rang d’adreces IP de forma jeràrquica. És a dir, el rang de totes les adreces que comencin pel valor de l’adreça base comparant el nombre de bits de valor 1 de la màscara.
Definició de rangs a partir d'una adreça IP i d'una màscara
- El rang definit per
128.154.X.Xes pot definir fent servir una adreça base com per exemple 128.154.0.0 i una màscara 255.255.0.0 - De forma semblant, el rang definit per
144.134.12.Xes pot definir fent servir una dreça base com per exemple 144.134.12.11 i una màscara 255.255.255.0
Fixeu-vos que per definir el valor de l’adreça base només cal tenir en compte els bits significatius de la màscara, la resta podrien prendre qualsevol valor.
Per detectar si una adreça pertany o no a un rang determinat per una adreça base i una màscara, només caldrà realitzar la operació binaria & i comparar el resultat. És a dir, direm que una adreça IP qualsevol (add1) pertany al rang definit per la màscara (masc) i l’adreça base (addb) si addb&masc=add1&masc.
Operació & per determinar si una adreça pertany al rang format per una adreça base i una màscara
Direm que l’adreça 10000000 11010010 10011001 10101001 (en decimal 128.210.153.169) pertany al rang d’adreces definit per l’adreça base 10000000 11010010 10011111 00000001 (en decimal 128.210.159.1) i la màscara 11111111 11111111 11111000 00000000 (en decimal 255.255.248.0) perquè el resultat d’operar la màscara amb ambdues adreces IP és idèntic:
10000000 11010010 10011111 10101001 10000000 11010010 10011001 10101001 &11111111 11111111 11111000 00000000 &11111111 11111111 11111000 00000000 ---------------------------------------- --------------------------------------- 10000000 11010010 10011000 00000000 10000000 11010010 10011000 00000000
L’ús de màscares és un recurs molt útil per jerarquitzar la xarxa, però sobretot per definir els filtres que permeten als nodes intermedis de la xarxa decidir cap on caldrà enviar els paquet en trànsit.
Adreces IP especials
Si bé és cert que les adreces IP tenen per objectiu identificar les interfícies de xarxa dels dispositius, hi ha certes adreces específiques que en comptes d’identificar centren la seva raó de ser en la funcionalitat que se’ls dóna. Ja sabeu que l’adreça 127.0.0.1 serveix per redirigir qualsevol petició de xarxa cap al propi dispositiu que fa la petició. De fet tot el rang d’adreces que comencen per 127 es reserva com a adreces de bucle o loopback, tal com se els coneix més popularment.
De forma semblant hi ha rangs d’adreces reservades a les xarxes locals. Això significa que no són adreces úniques sinó que es poden reutilitzar en cada xarxa local. És normal que les xarxes local petites tinguin adreces IP compreses entre els valor 192.168.0.0 i el valor 192.168.255.255, però també es reserven a l’ús privat el rang comprès entre 172.16.0.0 i 172.31.255.255 o el rang de totes les adreces que comencin pel valor 10, és a dir que tinguin la forma 10.x.x.x.
El valor 255 decimal equival al valor 11111111 binari. És a dir, tots els bits que composen el byte prenen el valor 1.
Dins del conjunt d’adreces especials també existeixen les adreces de difusió, conegudes popularment com a adreces broadcast. Es tracta d’adreces que permeten fer l’enviament d’un únic paquet, dirigit a tot el conjunt de dispositius que comparteixin un cert rang d’adreces. Les adreces broadcast s’identifiquen per disposar d’una o més posicions dels bytes menys significatius amb el valor 255.
Exemples d'adreces broadcast
L’adreça 248.147.118.255 serveix per adreçar-se a tots els dispositius que tinguin una adreça compresa entre 248.147.118.1 i 248.147.118.254. També l’adreça 154.3.255.255 aconseguirà arribar a aquells dispositius que tinguin una IP dins el rang 154.3.x.x.
Finalment farem una menció específica a les adreces anomenades de multidifusió o multicast. Es tracta d’adreces a les quals es poden fer subscripcions. Són adreces que no pertanyen a cap dispositiu concret, però que són controlades per certs dispositius intermedis que anomenem encaminadors o routers. Aquests dispositius poden rebre la petició de qualsevol dispositiu d’afegir la seva adreça IP a la multidifusió de qualsevol paquet dirigit a l’adreça multicast. És a dir, que el router, en detectar l’enviament d’informació dirigida a una adreça broadcast controlada per aquest dispositiu replicarà el paquets rebuts a totes les IP associades a l’adreça multicast.
L’objectiu d’aquest mecanisme és reduir el trànsit dins d’una xarxa. Hi ha serveis i aplicacions que necessiten enviar massivament una gran quantitat d’informació a molts dispositius a la vegada. Si s’utilitza un paquet diferent per a cada dispositiu es corre el risc d’inundar la xarxa amb paquets que contenen les mateixes dades i que només es diferencien per les adreces destí de la capçalera. El mecanisme multicast permet utilitzar un únic paquet durant un tram de la transmissió per fer arribar la mateixa informació als mateixos dispositius. És a dir, en el tram comprès entre el servidor i el dispositiu controlador de l’adreça multicast, només es farà servir un únic datagrama.
El multicast se sol reservar a empreses de comunicació que requereixin un enviament selectiu però continu de dades, com per exemple els mitjans de comunicació de pagament o fins i tot corporacions educatives que ofereixin streaming d’àudio o vídeo. També pot utilitzar-se en jocs MMO (sigles en anglès que signifiquen Massively Multilayer Online), malgrat que encara hi ha pocs servidors que facin servir aquesta tècnica. Les adreces multicast també solen usar-se per automatitzar processos de manteniment dins d’una xarxa com ara còpies massives de dades, clonacions o enviament d’ordres a múltiples dispositius .
Totes les adreces multicast comencen pel valor binari 1110. És a dir, configuren el rang que va des de 11100000 a 11101111, que corresponen als valor decimals compresos entre 224 i 239.
Les adreces IP reservades al multicasting són les que es troben compreses entre els valors 224.0.0.0 i 239.255.255.255. Les adreces del rang 224.0.0.x es troben reservades per a tasques de manteniment en àmbits de xarxes d’àrea local. Generalment tots els encaminadors interpretaran aquestes adreces com a multicast, acceptaran peticions de subscripció dels dispositius clients i faran el repartiment pertinent dels paquets que arribin a l’adreça multicast a tots el dispositiu subscrits. Així tots aquells encaminadors definits com a passarel·la o gateway d’un conjunt de dispositius seran els encarregats de fer la multidifusió del segment de xarxa que controlin.
Noms de domini
Ja veieu que les adreces IP no identifiquen realment un dispositiu sinó les seves interfícies de xarxa. De fet, no és necessari identificar els dispositius per fer una adreçament correcte. Ara bé, per a l’ús humà les adreces IP dificulten la localització de dispositius, ja que poden ser redundants, costen de memoritzar i en no tenir significat propicien els error involuntaris d’escriptura. Per tal d’apaivagar totes aquestes complicacions els dispositius solen batejar-se amb un nom alfanumèric.
Si l’àmbit del nom no supera les xarxes locals, no és gaire difícil controlar la seva unicitat dins el mateix àmbit ja que el nombre de noms necessaris sol ser relativament reduït i es pot coordinar des de la mateixa organització propietària de la xarxa. El problema esdevé, però, quan cal garantir la unicitat del nom en xarxes de gran abast. Per això existeixen organitzacions internacionals que atorguen noms específics que les organitzacions poden usar per generar els seus noms de dispositius amb garantia d’unicitat. Ens referim als noms de dominis.
Els noms de domini tenen la garantia que són únics en tot el món, per això els propietaris poden decidir d’usar-los directament com a nom d’un dispositiu o bé crear subdominis derivats per disposar de més noms. Els subdominis s’aconsegueixen afegint prefixos separats per un punt al nom de domini. Lògicament els prefixos seran també únics per a un domini específic de manera que la concatenació del prefix i el domini acabi donant sempre subdominis únics.
Exemples de subdominis
Un dels prefixos més usats com a nom de subdomini és www, però cal tenir en compte que pot servir qualsevol combinació, fins i tot diverses paraules separades per punts:
| subdomini | prefix | domini |
|---|---|---|
| www.google.com | www | google.com |
| ioc.xtec.cat | ioc | xtac.cat |
| es.answers.yahoo.com | es.answers | yahoo.com |
Servidors DNS
Malgrat tot, si en darrer terme l’adreçament en una xarxa cal fer-lo a través d’adreces IP, de què serveix poder identificar els dispositius mitjançant un nom de domini? Tard o d’hora caldrà identificar la IP del destí si cal enviar-hi dades.
Efectivament, però d’això se n’encarrega un servei d’Internet anomenat servidor de noms de domini, habitualment conegut com a DNS (Domain Name System). Els servidors DNS són serveis gratuïts d’Internet, que poden ser interrogats per un nom de domini o subdomini per tal d’aconseguir les adreces IP associades al nom. La xarxa de servidors DNS constitueix una immensa base de dades distribuïda de forma jeràrquica. La responsabilitat de mantenir les dades actualitzada correspon al propietari dels dominis de manera que el manteniment és mínim.
Les aplicacions que admetin noms de dispositius, hauran de consultar el servei DNS per trobar la IP a la qual hauran de direccionar la informació.
Capa d'enllaç i transmissió física del senyal
La capa d’enllaç és la més baixa de totes abans d’iniciar la transmissió física per mitjà de senyals electromagnètics. Des del punt de vista del programador d’aplicacions, és una capa tan allunyada i el seu funcionament queda tan amagat que no n’és necessari un coneixement gaire extensiu. A més, existeixen diversos protocols d’enllaç segons el tipus de xarxa en el qual ens cal transmetre.
Un exemple d’això el podem trobar en el fet que les enormes diferències existents entre el que serien xarxes locals i xarxes de gran abast obliga a disposar de protocols radicalment diferents. Però, a més, per tal de poder treure el millor rendiment a la xarxa, existeixen diversos protocols dins d’una mateixa categoria segons l’ús que se li doni, la quantitat de trànsit que hagi de suportar, la grandària dels paquets transmesos, o el sistema físic utilitzat
Les xarxes locals solen aglutinar una nombre reduït de dispositius i acostumen a connectar-se per mitjà de cables entrellaçats o sense fils a través d’emissors i receptors de baixa potència. El principal protocol utilitzat és Ethernet en les seves versions de cablejat (IEEE 802.3) o sense fils (IEEE 802.11). A grans trets, aquest protocol es basa en identificar els elements físics directament accessibles (targes de xarxa, punts d’accés sense fils, etc.) per mitjà d’una adreça única que els identifica anomenada MAC (Media Access Control). En una xarxa local la informació s’envia encapçalada per l’adreça MAC a tots els dispositius connectats. Els dispositius amb una adreça diferent descartaran la informació. En canvi el dispositiu destinatari la tractarà i la farà arribar a les capes superiors.
Les xarxes de gran abast són aquelles que aglutinen molts dispositius diferents. Per exemple les companyies de telecomunicacions disposen de xarxes de gran abast, però també els governs, les institucions i organitzacions internacionals disposen de grans xarxes interconnectades entre elles constituint el que coneixem com a Internet. Alguns dels protocols de xarxa usats aquí són PPP (Pear to Pear Protocol) que representen el punt d’accés a les xarxes de gran abast de dispositius particulars i xarxes d’àmbit local o ATM per aconseguir els enllaçaments intermedis.
Elements de programació d'aplicacions en xarxa
Els llenguatges d’alt nivell disposen de biblioteques especialitzades en el desenvolupament d’aplicacions distribuïdes. Malgrat que cada llenguatge contempla les seves particularitats, tots ells presenten força elements comuns que donen resposta als conceptes bàsics d’adreçament, enviament d’informació, connexió i canal de transmissió o tractament de recursos remots de la forma més transparent possible.
Implementació de capes inferiors
És important saber que Java només permet la implementació a la capa d’aplicació perquè aquesta característica descarta aquest llenguatge per implementar solucions alternatives de baix nivell. En general Java és un llenguatge destinat a implementar solucions d’alt nivell.
El llenguatge Java aprofita la riquesa que li dóna el paradigma orientat a objectes per definir una jerarquia de classes que embolcalla tota aquesta potencialitat a través de mètodes de molt alt nivell que faciliten el desenvolupament d’aplicacions distribuïdes robustes. De fet, l’API que contempla la biblioteca estàndard de Java només permet treballar a nivell de la capa d’aplicació usant la interfície d’accés exclusiu a la capa de transport. El JDK estàndard no contempla la possibilitat d’accedir a les capes de més baixes (xarxa o enllaç).
Es tracta d’una implementació realment eficient que dóna resposta a totes les necessitats originades des de la capa d’aplicació. Per tant no és necessari que ens plantegem si hem de fer servir altres alternatives, ni molt menys d’implementar-les nosaltres.
Adreçament
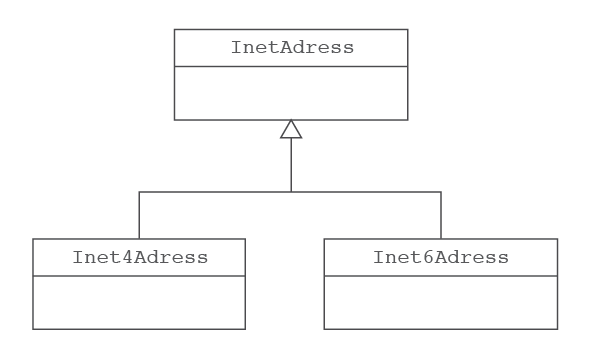
La classe InetAddress és una abstracció que ens permet gestionar de forma transparent adreces IP de qualsevol de les dues versions sense necessitat de tenir-ho en compte. Internament sempre es treballarà amb la classe corresponent a la versió adient (IPv4 o IPv6), que quedarà amagada al programador per la classe InetAddress. Això facilita molt la codificació ja que ens permet fer el mateix tractament amb independència de la versió IP usada.
Com a conseqüència d’aquesta abstracció, mai hauríem d’instanciar directament un objecte de la jerarquia invocant la sentència new, sinó que cal fer-ho a través d’un dels mètodes static que la classe InetAddress posa a la nostra disposició. Els més comuns són getByName, getAllByName getByAddress getLoopbackAddress i getLocalHost. Tots ells de cara al programador retornen una instància d’ InetAddress, però internament si la IP utilitzada és de tipus IPv4 la instància serà de la classe Inet4Address però si és de tipus IPv6 serà de la classe Inet6Address (vegeu jerarquia a la figura).
El mètode getByName necessita un paràmetre de tipus string. El paràmetre podrà tractar-se d’una URL, d’un nom de xarxa identificador d’un dispositiu o d’una adreça IP en qualsevol dels formats acceptats pel protocol IP. En cas de tractar-se d’una cadena URL, la classe InetAddress farà una petició al servidor DNS per defecte, per aconseguir resoldre el nom subministrat i obtenir una adreça IP equivalent. Si la cadena passada conté un nom de xarxa local, la classe InetAddress usarà els protocols estàndards que permetin resoldre el nom i obtenir l’adreça IP associada. Les adreces IP obtingudes es convertiran a un vector de bytes de la mida corresponent a la versió de l’adreça (4 o 16 bytes). També, en cas que el paràmetre passat contingui directament una adreça IP, es farà la conversió a vector de bytes. El vector de bytes servirà per instanciar un objecte de tipus Inet4Address o Inet6Address d’acord amb la mida del vector. La instància creada es retornarà tot seguit com a resultat del mètode. En cas que el sistema usat per resoldre la URL o el nom de xarxa obtingui més d’una IP es crearà la instància d’una d’elles.
El mètode getAllByName rep també un paràmetre contenint una cadena amb les mateixes opcions que el mètode getByName i es comportarà de forma similar a l’hora de resoldre el nom passat, però si la resolució conté diverses adreces IP crearà una instància diferent per a cada una d’elles, les agruparà en un vector d’objectes InetAddress i les retornarà.
El mètode getByAddress espera rebre per paràmetre un vector amb 4 o 16 bytes. En cas que la mida del vector sigui de 4 bytes instanciarà un objecte de la classe Inet4Address. Seria de la classe Inet6Address si la mida fos de 16 bytes.
El mètode getLoopbackAddress obté una instància d’ InetAddress fent servir l’adreça específica 127.0.0.1. De forma similar el mètode getLocalHost obté una instància de la connexió local principal de l’ordinador en el qual l’aplicació s’estigui executat.
En cas que el nom del paràmetre no es pugui resoldre o el format de l’adreça IP sigui incorrecta es llançarà una excepció del tipus UnknownHostException.
Les instàncies d’ InetAddress, siguin de tipus Inet4Address o Inet6Address permeten totes obtenir informació del host associat a la IP. Entre d’altres el mètode getAddress ens retornarà un vector de bytes amb el valor de la IP associada. De forma semblant getHostAddress retorna també la IP però en format textual i el mètode getHostName obté el nom del dispositiu associat. Si durant la consulta el dispositiu no indiqués el nom, el mètode retornaria l’adreça IP en forma d’string.
En el següent exemple posem en pràctica l’ús d’alguns mètodes:
També cal destacar els mètodes que ens informen sobre quin tipus d’adreça IP conté l’objecte InetAddress. A l’exemple podeu veure l’ús del mètode isLoopbackAddress que ens informa si la IP és del tipus 127.0.0.x. De forma semblant isSiteLocalAddress ens indica si es tracta d’una adreça de xarxa privada com per exemple ho pot ser 192.168.4.18. El mètode isMulticastAddress ens indica també si la IP l’objecte és de tipus multicast.
-

- Tim Berners-Lee. Font: Knight Foundation
Referències remotes i obtenció de recursos
Moltes vegades les aplicacions necessiten aconseguir recursos emmagatzemats en algun dispositiu de la xarxa. Sovint els recursos es troben emmagatzemats en forma de fitxer, però podrien també trobar-se emmagatzemats en una base de dades o obtenir-se com a resultat d’un procés.
El projecte WWW
Tim Berners-Lee és l’inventor del projecte Word Wide Web, més conegut per WWW o simplement web. Originàriament el projecte va néixer amb la intenció de permetre compartir documents i informació entre investigadors. La idea del WEB gira entorn al concepte d’hipertex, un enllaç capaç d’identificar a un recurs específic en un entorn web. Actualment Berners-Lee és professor del MIT i director del World Wide Web Consortium (W3C).
Berners-Lee defineix un recurs com «allò que té un identificador». Ens diu que malgrat que alguns recursos són virtuals i es troben a la xarxa, cal també considerar recursos les persones, les organitzacions, o d’altres entitats del món real. També aclareix que el concepte recurs no és pas sinònim d’entitat sinó més aviat una representació puntual d’una entitat o amb els seves paraules, «un mapa conceptual d’una entitat en un instant de temps». De fet els recursos poden romandre constants, les entitats no.
Per identificar un recurs del web, podem fer servir una URL (Uniform Resource Locator). Una URL és una cadena de caràcters única per a cada recurs diferent, que segueix unes determinades regles sintàctiques i conté informació d’on es troba el recurs, de com es pot localitzar. En tractar-se d’una cadena única per a cada recurs, diem que a més de localitzar el recurs també l’identifica. Per això les URL es consideren també identificadors de recursos.
En general la sintaxi d’una URL segueix el format següent:
esquema://acces/nom_especific
En el qual esquema és una paraula composta exclusivament de lletres corresponents a l’alfabet anglosaxó. També admet els caràcters :, ., - i +. Representa el nom del protocol d’accés o del context en el qual es troba el recurs: HTTP, FTP, TELNET, FILE, JDBC… en són exemples.
acces respon a algun dels següent formats:
- dispositiu
- dispositiu:port
- nom_usuari:contrasenya@dispositiu
- nom_usuari:contrasenya@dispositiu:port
L'acces indica en quin dispositiu es troba el recurs i com hi podem accedir. També se’l coneix com a autoritat (en anglès Authority) perquè representa l’autoritat que té drets sobre el recurs. A la posició dispositiu podem escriure una adreça IP o el nom del domini, i subdomini si fos necessari, que identifica el dispositiu. La identificació del dispositiu és obligatòria, però tota la resta és opcional. En cas de no especificar el port pel qual accedir, per defecte es considerarà el port reservat per defecte al protocol que fem servir. Si l’accés és lliure no caldrà especificar ni el nom d’usuari ni la contrasenya. Però si cal autorització es pot afegir, tal com mostra el format.
El nom_específic és una cadena que identifica el recurs dins del dispositiu. Pot estar compost de dues parts separades per un caràcter ?. La primera és obligatòria. En cas que la segona part fos opcional s’ometrà el caràcter ?. És a dir que seguira algun d’aquest formats:
camicami?altres_indicacions_de_cerca
El cami estarà format per dígits i cadenes de caràcters de l’alfabet anglosaxó separades pel caràcter /. Representen una ubicació jeràrquica semblant als arbres de directoris dels sistemes de fitxers, perquè originàriament, el cami de la URL coincidia amb el cami del sistema de fitxers del servidor on es trobava emmagatzemat el recurs. Actualment, malgrat que pot coincidir, no sempre és així. De fet, pot només tractar-se d’una identificació lògica sense correspondència amb cap ruta real ni tan sols amb cap fitxer (les dades podrien estar emmagatzemades en una base de dades, però identificades per mitjà d’un cami lògic. Per indicar el camí, s’accepten també caràcters especials com ., - o _ a més dels dígits i l’alfabet anglosaxó. Tot i així, la necessitat d’internacionalitzar el sistema ha obligat a cercar una forma d’incorporar més caràcters. En cas que sigui necessari afegir caràcters no contemplats, podrà indicar-se el seu codi hexadecimal precedit d’un símbol %.
La part anomenada altres_indicacions_de_cerca (i que en anglès es coneix com a query) es troba constituïda per un nombre variable de parelles d’atribut-valor. Cada parella es trobarà separada de la següent per un símbol &. L’atribut apareixerà sempre en primer lloc (més a l’esquerra) i el valor en segon lloc immediatament després del símbol = que farà de separador. Veiem algun exemple:
Exemples de URLs
http://www.xtec.cat/documents/fp/dam/curriculum.html.
Es tracta d’una referència al recurs ubicat al camí documents/fp/dam/curriculum.html al qual podem accedir en el domini www.xtec.cat i usant el protocol HTTP. La referència usarà el port per defecte, és dir el port 80 que és el port per defecte del protocol HTTP.
ftp://admin:secret@ftp.debian.com/readme.txt.
Aquí es veu un URL que referencia el recurs readme.txt, usant el protocol FTP. El recurs es troba ubicat en el dispositiu que respon al domini ftp.debian.com. Per aconseguir el recurs cal enviar també el login i contrasenya que a l’exemple responen als valors admin i secret respectivament.
file:///home/user/recordatori.pdf
Aquí el recurs es troba en un disc local des del qual es fa la consulta seguint el camí home/user/recordatori.pdf.
http://www.servidor.com/cercar?tipus=compres&inici=2010-03-01&final=2010-03-31
Cas que cerca i obté a un recurs que representen les compres realitzades durant el mes de març registrades al servidor del domini www.servidor.com. El protocol d’accés és HTTP.
Classes per treballar amb referències a recursos
El Java Development Kit (JDK) de Java disposa de dues classes per poder treballar fàcilment amb recursos remots identificats amb una URL. Ens referim a els classes URL i URLConnection. Es tracta de classes de molt alt nivell que hauríem de situar dins la capa d’aplicació. Això permet al programador oblidar-se dels protocols més baixos i centrar la seva atenció en els protocols propis de l’aplicació.
La classe URL contempla dues atribucions. D’una banda representa la cadena que identifica el recurs i disposa de mètodes per tractar-la i extreure’n informació i de l’altre un punter al contingut del recurs.
Els principals mètodes que faciliten el tractament de la cadena localitzadora destriant la seva composició són:
String getProtocol(): retorna una cadena amb el nom del protocol que la URL indica.String getAuthority(): obté l’autoritat extreta de la cadena URL.String getPath(): és la part que hem anomenatcamia la representació esquemàtica de la sintaxi de la URL.String getQuery(): invocant aquest mètode obtindrem la part anomenadaaltres_indicacions_de_cerca. En aquesta cadena s’exclou l’interrogant que la separa decami.String getFile(): retorna la concatenació entre getPath() i getQuery(), mantenint entre ambdues parts el caràcter separador (un interrogant).String getPort(): en executar-lo retornarà el port especificat a la URL. Si no s’especifica port, retornarà -1.String toString(): obté tota la cadena de la URL. Aquest mètode és útil perquè la classe disposa de diversos constructors als quals se’ls pot passar la cadena sencera o per parts. Si fos així el constructor concatenarà les diverses parts passades per paràmetre i les formatarà adequadament amb els símbols adequats que les han de separar.
Els principals constructors són:
URL(String protocol, String acces, int port, String nomEspecificDelRecurs): constructor d’URL que crearà la cadena localitzadora, concatenant el protocol, l’accés, el port i el nom específic de recurs.URL(String protocol, String acces, String nomEspecificDelRecurs): constructor d’URL que crearà la cadena de localització, concatenant el protocol, l’accés i el nom específic de recurs.URL(URL context, String nomRelatiuDelRecurs): aquest constructor instancia la URL amb dos paràmetres i permet expressar un adreçament relatiu. Així la cadena del segon paràmetre actuarà com un localitzador relatiu al context passat en el primer paràmetre.URL(String cadenaUrl): instanciarà un objecte URL a partir de la seva cadena passada per paràmetre.
En referència a l’obtenció del contingut del recurs, podem invocar el mètode openStream() per aconseguir un flux d’entrada apuntant al contingut remot. És possible també obtenir directament una instància de URLConnection per disposar de més control sobre la connexió invocant el mètode openConnection(). La classe URL fa servir una instància com aquesta durant la invocació d’ openStream per tal de poder retornar el flux de dades.
La classe URLConnection usarà el protocol TCP per fer la petició del recurs. Aquí el flux de dades cal obtenir-lo cridant getInputStream(). Amb aquesta classe tindrem a la nostra disposició alguns mètodes útils per obtenir informació del contingut. Cal però clarificar que es tracta d’informació extra (en forma de capçalera) aportada pel servidor al qual se li ha fet la petició del recurs. Podem trobar-nos, doncs, que alguna vegada la informació no està del tot completa o fins i tot podria arribar a ser errònia. Entre d’altres, podem demanar la longitud del contingut (fent servir el mètode getContentLength), la codificació usada per emmagatzemar els caràcters o bé el tipus de dades que el recurs conté (imatge, text, XML, PDF, etc). La invocació necessària per obtenir el tipus de recurs és getContentType i per conèixer la codificació dels caràcters és getContentEncoding.
Tot i que la classe URLConnection pot suportar URLs de diversos protocols, el seu disseny està especialment pensat per donar suportar al protocol HTTP. És a dir, els seus mètodes suporten la funcionalitat descrita en el protocol HTTP, tot i que és capaç de treballar amb recursos remots apuntats per URLs que facin servir altres protocols. En realitat, URLConnection és una classe abstracta que delega la seva funcionalitat en les classes que l’estenen. Cada classe hereva d’ URLConnection controlarà un protocol diferent (vegeu la figura). D’aquesta manera resulta força senzill afegir nous protocols o modificar els existents sense repercutir en la resta de classes.
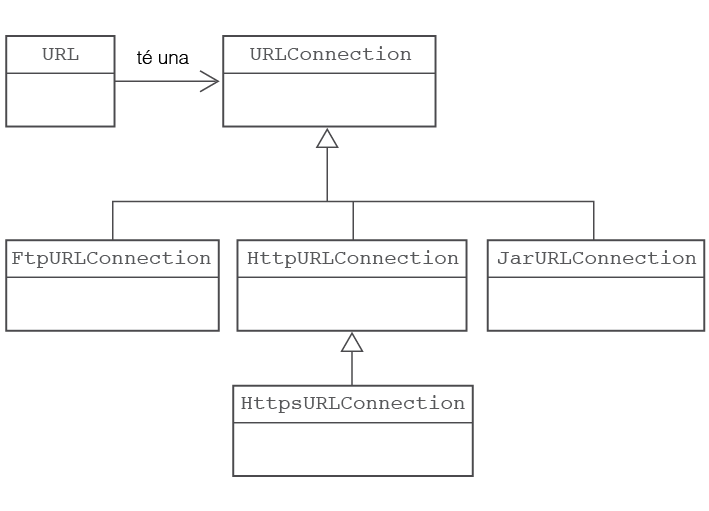
A nivell d’aplicació normalment treballarem sempre amb la classe URLConnection i no amb les seves derivades perquè així podem despreocupar-nos del protocol utilitzat i donar un tractament estàndard a totes les connexions. Quelcom semblant passa amb els objecte de tipus flux que seran retornats per aconseguir el contingut remot. La classe usada dependrà del tipus de contingut segons sigui imatge, PDF, text pla, o un document HTML, però pel programador totes elles caldrà tractar-les com una instància de la classe InputStream. Es tracta d’uniformitzar el tractament de tot el contingut tant com sigui possible.
Atenent que la classe URLConnection està orientada específicament al protocol HTTP, disposa d’un conjunt de mètodes que a més de recuperar el contingut, permeten obtenir informació extra definida en aquest protocol o bé enviar informació específica seguint les especificacions del protocol. Cal veure que es tracta de processos força genèrics comuns a diferents protocols i per tant és possible reutilitzar la mateixa funcionalitat malgrat que estiguem fent servir altres protocols.
Recordeu que existeix una gran diversitat de formes de codificar els caràcters (ISO-8859-1, WINDOWS-1252, UTF-8…). Això és així perquè no existeix un únic model per representar qualsevol tipus de caràcter sinó que cada codificació és capaç de representar només un subconjunt més o menys ampli de caràcters. Actualment el sistema més universal és UTF.
D’acord amb l’especificació HTTP les dades viatgen embolcallades en una capçalera que conté metainformació del contingut. Generalment aquesta informació l’omple el servidor en el qual es troba ubicat el recurs. Es tracta d’informació opcional i per tant podem usar-la però cal tenir en compte que alguns recursos arribaran sense ella. Alguns d’aquests mètodes són:
Recordeu que la forma de representar una data és a partir d’un valor numèric que indica el nombre de mil·lisegons transcorreguts des del l’1 de gener de 1970.
String getContentEncoding(). Obté la codificació de caràcters que el contingut del recurs fa servir.int getContentLength(). Aconsegueix la longitud del contingut que indica la capçalera.String getContentType(). Retorna el tipus de contingut d’acord amb l’estàndard HTTP. Aquesta especificació per exemple tipifica un document de text com atext/plain, un document HTML com atext/html, una imatge JPG com aimage/jpg, etc.long getDate(). Ofereix la data de creació/modificació del recurs con un valor numèric de tipuslong
En cas que el tipus de contingut no es trobi informat a la capçalera podem fer servir el guessContentTypeFromName que intenta esbrinar el tipus a partir del nom del fitxer contingut a la URL. Aquest mètode pot servir per verificar o complementar la informació referent al tipus de dades del recurs.
Codi per comprovar si un recurs és una imatge de format GIF
Veieu a continuació un exemple que determina si un recurs en una imatge en format GIF comparant el valor retornat per els mètodes getContentType i guessContentTypeFromName. Fixeu-vos bé com se li passa el nom del fitxer fent servir el mètode de la classe URL pertinent.
URLConnection ens oferirà un flux de de dades per obtenir del contingut del recurs invocant el mètode getInputStream(). Es tracta del mateix flux de dades que obtindríem fent servir directament el mètode openInputStream de la classe URL perquè internament aquesta fa servir una instància d’ URLConnection per accedir al contingut del seu recurs. És a dir, per aconseguir una instància d’un flux d’entrada podeu fer servir indiferentment qualsevol de les dues formes:
o bé,
Vegeu l’annex “Manipulació dels fluxos” en la secció Annexos.
Cal tenir en compte a l’hora de treballar amb fluxos que només admeten de ser recorreguts en una única direcció i un cop han estat recorreguts no es poden tornar a recórrer. Normalment farem servir un array de caràcters o bé bytes per anar extraient de cop gran quantitat del contingut del flux fins extreure’l tot. Escollirem el tipus de dada de l’array segons el que contingui el recurs. Si es tracta d’un recurs de text podem convertir la instància d’ InputStream en un objecte de tipus InputStreamReader per tal de disposar de mètodes més adients per tractar caràcters.
Obtenció de dades a través d'un flux de dades
Exemple de codi per extreure la informació arribada a través d’un flux de dades (InputStream).
La classe URLConnection disposa també d’una connexió per enviar informació cap al recurs. De fet, HTTP especifica mecanismes per enviar dades des del client al servidor, per exemple extraient-les d’un formulari, o enviant un fitxer. Sovint les dades a enviar al servidor es concatenen juntament amb la mateixa cadena URL, constituint la part que hem anomenat altres_indicacions_de_cerca i que en anglès es coneix com a query. Malgrat tot HTTP també és capaç d’acceptar dades posteriors a la connexió a través d’una cadena URL. És el que es coneix com a mètode POST perquè primer s’estableix la connexió i immediatament després es comencen a enviar dades. El protocol HTTP estableix la seqüència fixa de passes que cal seguir per fer l’enviament amb èxit.
Imaginem que disposem d’una URL vàlida anomenada url. En primer lloc, caldrà obtenir la connexió fent,
Després, cal indicar a la connexió que tenim intenció d’enviar dades invocant el mètode setDoOutput
i començar el procés d’enviament,
En acabar cal tancar el flux de sortida per assegurar que s’envien totes les dades i s’alliberen els recursos,
Com és natural, aquest sistema por fer-se servir també quan treballem amb altres protocols, perquè el diàleg específic propi del protocol es realitzarà internament dins de la classe específica (HttpURLConnection, HttpsURLConnection, FtpUrlConnection…) en el moment de fer la connexió i l’enviament de les dades.
Sòcols
API és l’acrònim d’Application Programming Interface.
Els sòcols, en anglès sockets, són una Interfície de Programació d’Aplicacions (API) que permet a dues aplicacions intercanviar informació malgrat que s’executin en dispositius diferents. Representen la porta d’entrada i sortida a la xarxa i constitueixen la base de qualsevol aplicació distribuïda.
La documentació oficial de Java defineix els sòcols com el punt final de la comunicació bidireccional entre dos programes que s’executen a la xarxa.
Recordeu que l’arquitectura de les xarxes defineixen una pila de capes des de l’aplicació al medi físic per tal de fer factible la transmissió de dades entre programes. Els sòcols estarien situats a la capa de transmissió i representarien el punt d’accés de les aplicacions a les capes inferiors del sistema.
Per motius de seguretat i robustesa, Java no disposa de cap més utilitat que permeti treballar directament a les capes inferiors, per tant els sòcols es converteixen en la utilitat de programació de més baix nivell del llenguatge Java. Això significa que no és possible fer implementacions de protocols que es trobin per sota de la capa de transmissió.
Els sòcols es troben associats a una IP i a un port de forma que sigui possible adreçar-hi informació a través de la xarxa fent servir algun dels protocols sobre IP disponibles (TCP o UDP).
Segons el protocol utilitzat parlarem de sòcols no orientats a connexió quan utilitzin el protocol UDP i de sòcols orientats a connexió quan utilitzin el protocol TCP.
Implementació de sòcols no orientats a connexió
El llenguatge Java contempla 3 classes a l’hora de fer implementacions de comunicació no orientada a connexió. DatagramSocket i DatagramPacket constitueixen les classes bàsiques de la comunicació a través d’UDP. La tercera, deriva de DatagramSocket i dóna suport específicament a les comunicacions de tipus multicast (vegeu la figura).
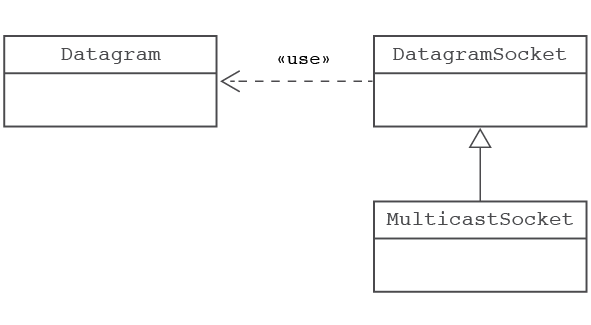
DatagramSocket
Els sòcols creats usant DatagramSocket són capaços d’enviar i rebre els paquets especificats pel protocol UDP. En crear una instància podem especificar un port concret que el sòcol escoltarà quan sigui necessari atendre algun servei (estàndard o no) associat al port. Pels sòcols temporals, en canvi, no caldrà establir el valor del port. Durant la creació de la instància la classe cercarà el primer port lliure dins el rang disponible per atendre comunicacions temporals.
DatagramSocket(). Genera una instància deDatagramSocketassociada a un port temporal.DatagramSocket(int port). Genera una instància deDatagramSocketassociada al port que s’indica en el paràmetre.DatagramSocket(int port, InetAddress). En dispositius que tinguin més d’una IP es podrà especificar a través del segon paràmetre la IP que es vincularà la instància generada.
No cal especificar sempre la IP en dispositius amb diverses adreces, la classe en seleccionarà una per defecte durant la creació de la instància.
Els objectes de la classe DatagramPacket representen paquets de dades d’acord a l’especificació definida pel protocol UDP. La classe és capaç d’afegir per defecte gran part dels camps obligatoris del paquet. Tot i així cal indicar els bytes de dades a enviar, la longitud d’aquestes i també l’adreça i el port destí.
DatagramPacket(byte[] bufferDeDades, int longitudDades, InetAddress adreca, int port). Genera una instància deDatagramPacketque tindrà com a dades els bytes continguts al vector del primer paràmetre en la quantitat que indiqui el segon. Òbviament la longitud especificada no podrà superar mai la quantitat de bytes continguts al vector. El segon i tercer paràmetres permetran definir el destí de les dades.
Els objectes DatagramSocket disposen del mètode send per enviar un objecte DatagramPacket a l’adreça establerta en el propi paquet. A continuació veiem un exemple complet de creació d’instàncies i enviament d’un missatge de caràcters.
El procés de recepció de dades és molt similar, tot i que a l’hora de generar el paquet UDP cal crear-lo buit, però amb suficient capacitat per poder-hi copiar les dades rebudes.
Heu de tenir en compte, però, que rarament caldrà implementar un dispositiu que només hagi de fer enviaments o recepcions. Normalment caldrà definir petits diàlegs en els quals els dispositius hagin de rebre i enviar missatges successives vegades fins a completar l’objectiu de la comunicació. Els DatagramSockets, però, no són full-duplex, és a dir no poden processar al mateix temps un enviament i una recepció, sinó que ho han de realitzar de forma seqüenciada, primer un procés i després l’altre.
Normalment un dels dispositius restarà escoltant a l’espera que d’altres iniciïn el diàleg. En general el dispositiu que escolta de manera indefinida fa el paper de servidor i els altres dispositius de client. Generalment una classe que implementi un servidor haurà de tenir algun mètode de configuració que permeti assignar el port que haurà d’atendre. També haurà de tenir un mètode que iniciï l’escolta del port, esperi la recepció de dades, les interpreti, n’obtingui la resposta, l’enviï al client que hagi fet la demanda i torni de nou a esperar una nova petició.
La implementació en Java del que acabem de descriure seria:
Fixeu-vos que es tracta d’una classe prou genèrica per adaptar-se a la majoria d’aplicacions, tan sols caldria adaptar el mètode processData als requeriments específics de cada implementació.
Fixeu-vos també, que la classe DatagramPacket disposa de mètodes per obtenir la informació continguda en el paquet. Això, a banda d’aconseguir les dades rebudes, permet també saber a quina adreça i port caldrà enviar la resposta generada.
De forma semblant al servidor, es pot definir un client de manera genèrica tenint en compte que és el client el que iniciarà la comunicació i per tant cal un procés específic que aquí anomenarem getFirstRequest per tal d’aconseguir les dades inicials que caldrà enviar al servidor. A més, cada cop que el servidor ens enviï la resposta al nostre requeriment, caldrà fer-la arribar als interessats a través del mètode getDataToRequest que rebrà o bé un nou requeriment pel servidor o bé el senyal per finalitzar la connexió i abandonar l’execució de l’aplicació client.
Podeu imaginar que segons de quina aplicació client, getDataToRequest haurà de fer diferents coses amb les dades rebudes i obtenir de diferent manera les noves dades a enviar. Per exemple algunes aplicacions requeriran només mostrar les dades per pantalla i esperar la resposta de l’usuari, però d’altres potser requeriran també emmagatzemar les respostes en una fitxer o base de dades, obtenir la resposta mitjançant un procés automatitzat, etc. Sigui com sigui, el procés caldrà realitzar-lo sempre a través del mètode getDataToRequest per tal d’aconseguir un client prou adaptable.
El client també ha de ser capaç de reconèixer el senyal de finalització indicat per l’usuari, per exemple, en una de les seves respostes o com a resultat d’un procés que avalua que ja no cal continuar més la comunicació amb el servidor. En el nostre exemple aconseguim un procés neutre incloent el mètode mustContinue al qual se li passarà les dades retornades per getDataToRequest i ens retornarà si cal o no continuar la comunicació. Usarem aquest valor booleà per mantenir-nos dins del bucle o bé per abandonar-lo.
Abans d’iniciar la comunicació caldrà haver configurat el client indicant el nom del servidor i el port on es trobarà escoltant. Per això usarem el mètode init, malgrat que també es podria implementar en el propi constructor.
En aquesta implementació s’ha optat per rellançar tots els llançaments d’excepcions per tal de deixar el tractament d’errors pel darrer nivell d’implementació quan es pugui decidir què s’ha de fer amb el errors. Tot i així, hi ha una excepció que caldria controlar aquí. En cas que el servidor tingui problemes i no sigui capaç de contestar el requeriment d’un client, aquest podria romandre esperant la resposta indefinidament. És possible evitar aquesta situació fent servir el mètode setSoTimeout que limitarà el temps d’escolta només a la quantitat de mil·lisegons que se li passi com a paràmetre. Si el DatagramSocket sobrepassa el temps d’espera es llançarà una excepció de tipus SocketTimeoutException. Ara bé, no ens interessa que el llançament provoqui abandonar el bucle i per tant la finalització de l’execució, sinó que és preferible fer una notificació sense sortir del bucle while. El codi de l’interior del bucle podria quedar com segueix:
Per últim ambdues classes haurien de tenir també un mètode que permeti fer el tancament de l’objecte DatagramSocket abans d’acabar amb l’execució del servidor o del client. Per exemple:
MulticastSocket
La jerarquia de sòcols UDP de Java contempla també la classe MulticastSocket. Amb aquesta classe és possible crear aplicacions que usin adreces multicast. Recordeu que les adreces multicast permeten als dispositius subscriure’s a la difusió de tot el que arribi per l’adreça a la qual s’ha subscrit. Qualsevol objecte MulticastSocket podrà fer enviaments a tots els dispositius subscrits i rebre tot allò que vagi dirigit a l’adreça associada. Malgrat tot, generalment les aplicacions multicast fan els enviaments des d’un servidor i els clients subscrits es limiten a escoltar i processar les dades, de forma semblant al que es veu a la figura.
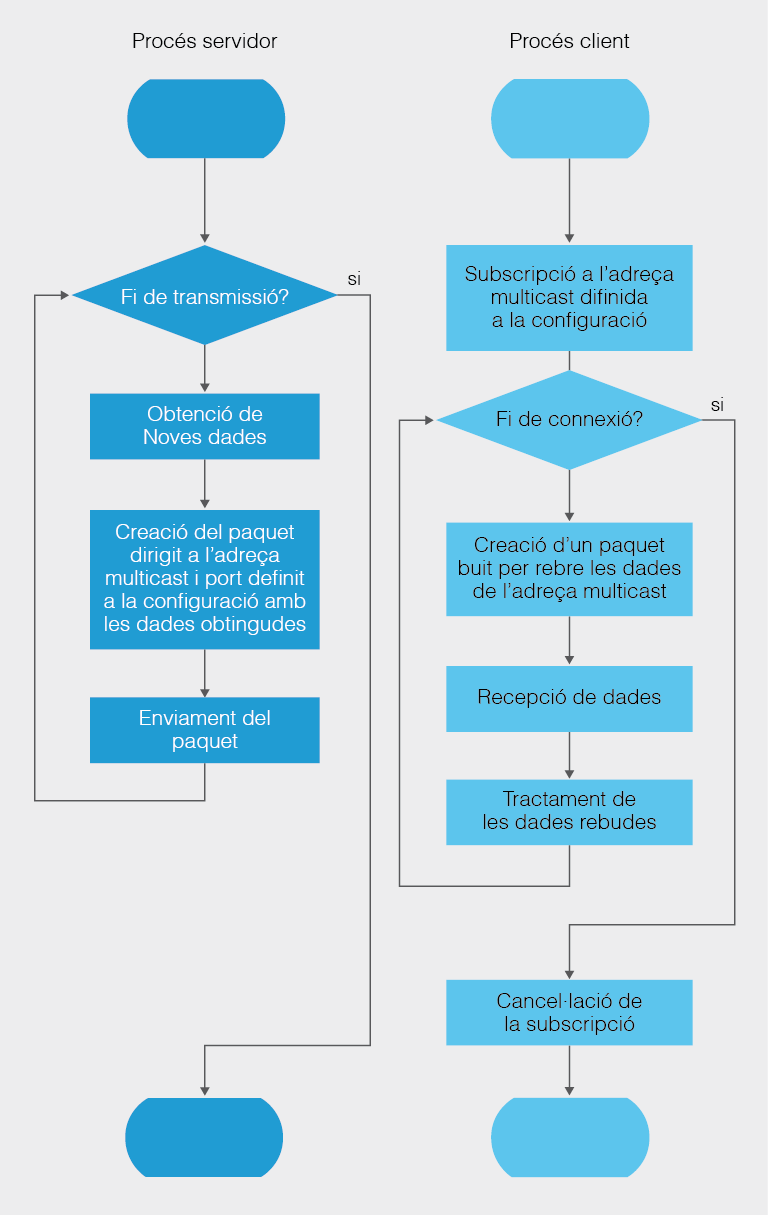
L’ús de la classe MulticastSocket és molt semblant a la classe DatagramSocket, pel que fa a la recepció i l’enviament de dades perquè ambdues instancien els paquets com a objectes DatagramPaquet i fan servir el protocol UDP per a la transmissió. Tot i així, cal assenyalar que la classe MulticastSocket disposa d’un mètode per realitzar la subscripció (joinGroup) i un altre per cancel·lar-la (leaveGroup). A més destacarem que els sòcols Multicast han de treballar tots en el mateix port, ja siguin clients o servidors.
Anem a veure com podem plasmar l’esquema anterior amb Java. Començarem codificant un servidor genèric. El mètode init permetrà configurar les instàncies per mitjà dels paràmetres, l’adreça multicast representada com un string i el port comú en el qual enviar totes les dades.
Destacarem que la funcionalitat del mètode getData dependrà de cada aplicació. També veiem que es contempla el mètode close per a preveure el tancament del sòcol abans de finalitzar l’execució del servidor.
El client, abans d’iniciar el bucle per rebre totes les dades, haurà de subscriure’s a l’adreça multicast i en finalitzar el bucle caldrà cancel·lar la subscripció per reduir despeses inútils de recursos i tràfic a la xarxa innecessari.
Implementació de sòcols orientats a connexió
Els sòcols orientats a connexió fan servir el protocol TCP. Recordeu que en aquest cas les dades es passen a l’aplicació en el mateix ordre en què han sortit i s’assegura que no es perd informació durant la transmissió. El protocol TCP defineix que abans de començar la transmissió de dades cal fer una petició de connexió que l’altre part haurà d’acceptar. Un cop acceptada la connexió, en ambdós costats es reservarà un port de xarxa exclusivament per a la transmissió de dades en qualsevol dels dos sentits. Recordeu que TCP és un protocol que defineix una comunicació full-duplex exclusiva entre dos dispositius.
Java té una manera pròpia d’implementar aquestes característiques. Dels dos dispositius a posar en contacte, un d’ells farà el paper de servidor esperant la demanda d’algun dispositiu, que jugarà el paper de client. El procés del servidor usarà una instància de la classe ServerSocket per restar escoltant fins que un client faci una petició, moment en què acceptarà la connexió i generarà una instància de tipus sòcol per mantenir la comunicació full-duplex, des d’un port temporal, durant la transmissió. El procés dels clients en canvi, usarà directament un objecte de la classe sòcol per fer la petició i també per mantenir la connexió i la transmissió de dades.
Per a la transmissió de dades es fa servir el concepte de flux de dades. Es considera que les dades flueixen de forma contínua i seqüencial des de l’origen fins al destí. La característica de seqüencial és essencial aquí, ja que garanteix que l’ordre d’arribada a la destinació és el mateix que l’ordre de sortida des de l’origen.
El concepte de flux (stream en anglès) és una abstracció relacionada amb qualsevol procés de transmissió d’informació entre un origen i un destí.
El flux de dades segueix un únic sentit (de l’origen al destí), per tant les aplicacions que necessitin transmetre i rebre hauran de fer servir dos fluxos, un en cada sentit.
El flux que rep dades des d’un origen extern s’anomena flux d’entrada (input stream en anglès) i el que envia informació a un destí exterior s’anomena flux de sortida (output stream en anglès).
Els objectes de tipus sòcol contenen dos fluxos de dades a través d’un d’ells es rebran les dades (flux d’entrada) i a través de l’altre s’enviaran (flux de sortida). En aplicacions client servidor, el flux de sortida del servidor equival al flux d’entrada del client i el flux d’entrada del servidor coincidirà amb el de sortida del client.
A la figura podeu veure el diagrama de les classes que entren en joc en una transmissió TCP de Java. Les classe SSLServerSocket i SSLSocket ofereixen la mateixa funcionalitat que ServerSocket i Socket respectivament però estan especialitzades en transmetre de forma segura usant un protocol de seguretat anomenat SSL.
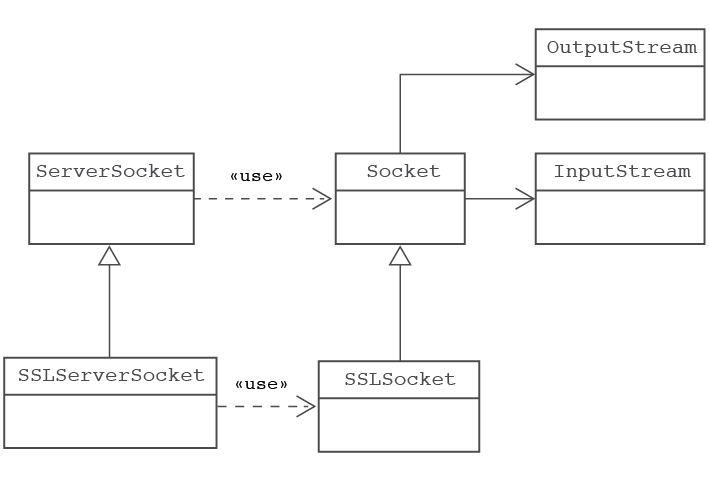
La implementació que el llenguatge Java fa del protocol TCP passa per disposar en un dels dispositius a comunicar, el que faci el paper de servidor, d’una instància de ServerSocket que tindrà per objectiu únicament esperar que algun client decideixi fer una petició de comunicació, utilitzant els mínims recursos possibles mentre duri l’espera. El port a atendre, s’indicarà en el moment de creació de la instància de ServerSocket com a paràmetre del constructor.
Creació d'un ServerSocket que atendrà el port 7777 a l'espera de clients que demanin de comunicar-se
El client necessitarà una instància de Socket, la qual disposarà des del primer moment dels recursos propis del protocol TCP, ja que les instàncies de Socket solen crear-se indicant l’adreça i el port amb el que caldrà comunicar-se i des de la creació que es realitza la petició inicial per poder generar els recursos pertinents com els fluxos de dades que simularan els dos canals de comunicació que el protocol TCP demana.
Creació d'un sòcol en un client que vulgui comunicar-se amb un servidor que es trobi atenent el port 7777 a l'adreça 192.168.4.1
Durant la creació del sòcol del client s’enviarà al servidor la petició, el qual en rebre-la l’acceptarà creant un sòcol específic per comunicar-se amb el client acceptat a la banda del servidor. Recordeu que la comunicació TCP és exclusiva per dos dispositius, per això el servidor ha d’anar creant un sòcol específic per cada client que faci la petició.
La creació del sòcol a la banda del servidor es troba automatitzat i s’obté com a retorn del mètode de ServerSocket que inicia l’escolta del port fins l’arribada de la petició. Ens referim al mètode accept.
Mètode accept
El mètode accept resta a l’espera d’una petició i en el moment de produir-se crea una instància específica de sòcol per suportar la comunicació amb el client acceptat.
A partir d’aquí ambdós sòcols, el de la part client i el de la part servidor, disposaran d’un canal d’entrada i un de sortida adequadament connectats. La implementació dels canals es realitzarà a través d’instàncies internes de fluxos d’entrada i sortida. Per obtenir els fluxos d’un sòcol caldrà invocar els mètodes getInputStream i getOutputStream per obtenir respectivament els fluxos d’entrada i sortida.
Usarem els mètodes propis del fluxos per enviar o rebre dades a través d’ells. L’enviament a través del flux de sortida d’un dels sòcols implicarà la recepció de les mateixes dades enviades a través del flux d’entrada de l’altre sòcol. Podeu veure l’esquema del procés descrit a la figura on:
- 1: El sòcol de la part client demana connectar-se a l’adreça en la qual es trobi el servidor i al port que escolti una instància de
ServerSocketdel servidor. - 2: El
ServerSocketaccepta la connexió i crea un sòcol a la part del servidor amb dos canals, un d’entrada i un de sortida. - 3: l’
InputStream(flux d’entrada) del sòcol de la part client es troba connectat a l’OutputStream(flux de sortida) del sòcol de la part servidor i el seu flux d’entrada connecta amb el flux de sortida del sòcol del client. D’aquesta manera és possible la comunicació en ambdues direccions amb la qualitat exigida pel protocol TCP.
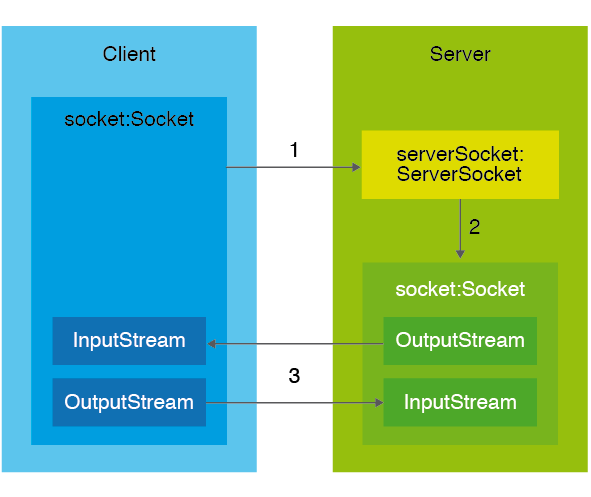
A continuació veurem un exemple senzill de la implementació d’un diàleg entre un servidor i un client en el qual alternen consecutivament petició i resposta. Hem pres la consideració que tant les peticions com les respostes s’inclouen en una única línia de caràcters. D’aquesta manera cada part pot saber quan acaba l’enviament remot per tal de processar les dades i generar una resposta o una nova petició.
A la classe TcpSocketServer que representarà una aplicació de tipus servidor destacarem el mètode listen en el qual implementarem un bucle continuu en el qual una instància de ServerSocket anirà escoltant a cada iteració el port a atendre esperant clients que es connectin i acceptant les seves peticions a instanciar un sòcol. La comunicació entre ambdós objectes de tipus sòcol (el del client i l’acabat de generar) la implementarem en un mètode a part que anomenarem proccesClientRequest.
El mètode per gestionar les peticions del client (proccesClientRequest) constarà d’un bucle continu que iterarem fins que el client ens indiqui que no té més peticions a realitzar. Per facilitar la dinàmica de pregunta resposta, convindrem que tant la petició com la resposta s’inclouran en un sola línia de caràcters. D’aquesta manera és fàcil detectar el final del missatge en qualsevol dels dos costats.
Per més detalls, vegeu l’annex “Manipulació de fluxos” de l’apartat Annexos.
En tractar-se d’un diàleg basat en cadenes de caràcters delimitades per un final de línia, podem fer servir els fluxos específics orientats a caràcters que disposa el llenguatge. Recordeu que Java permet convertir qualsevol flux en un flux específic orientat a caràcters durant el procés de construcció.
El mètode isFarewellMessage indicarà si el missatge del client es correspon amb una petició de finalització de la comunicació. Si no s’hi correspon, caldrà processar la petició i obtenir la resposta mitjançant el mètode processData. La resposta obtinguda s’enviarà al client a través d’un stream de tipus PrintStream que afegirà al final de l’enviament un símbol de final de línia.
Forçarem l’enviament de les dades invocant el mètode flush i seguidament esperarem un nova petició del client, començant de nou l’anàlisi i si cal processant una nova iteració del bucle.
Per tal de gestionar de forma eficient els recursos del servidor, és important tancar les instàncies de sòcol dels clients que hagin demanat la finalització de la comunicació. Implementarem el tancament en un mètode específic anomenat closeClient que invocarem des del mètode listen tot just en acabar de retornar de la invocació del mètode processClientRequest.
És important seguir la seqüència d’instruccions del mètode closeClient si volem assegurar una tancament correcte. Els mètodes shutDownInput i ShutDownOutput engeguen ambdues peticions de tancament necessàries en el protocol TCP. La invocació del mètode shutDownInput enviarà la petició de tancament al sòcol remot i esperarà la confirmació de la mateixa. El sòcol remot en rebre una demanda de tancament del seu canal de sortida forçarà un darrer enviament de les dades contingudes al buffer abans d’enviar la confirmació. Quan el servidor local rebi la confirmació alliberarà el bloqueig de lectura del seu InputStream. De forma semblant, la invocació de ShutDownOutput, provocarà el forçament de l’enviament de les darreres dades contingudes al buffer de sortida local i enviarà la petició de tancament del canal d’entrada del sòcol remot. El sòcol remot abans de confirmar el tancament alliberarà el bloqueig de lectura dels seu InputStream.
Un cop fetes les peticions de tancament i rebudes les confirmacions podrà processar-se el tancament local dels fluxos i seguidament el tancament del sòcol. Cal tenir en compte que els tancament dels objectes sòcol no impliquen el tancament del servidor, sinó que aquest restarà disponible per acceptar noves peticions ja que el ''serverSocket'' restarà obert en el bucle inicial del mètode ''listen''. Quan decidim fer el tancament de tot el servidor caldrà tancar també la instància del ''serverSocket''.
A la part client, a la classe TcpSocketClient implementarem la connexió en el mètode connect. Aquí iniciarem un sòcol per tal que demani una petició de connexió TCP a l’adreça i port passada per paràmetre i iniciarem un bucle continu que permeti anar fent peticions i rebent les respostes aplicant la mateixa consideració que ambdues aniran delimitades per un final de línia.
Per tal que funcioni correctament aquest algoritme serà necessari disposar d’un mètode especific anomenat getRequest que processi la resposta rebuda i aconsegueixi una nova petició que acabarà enviant-se al servidor. L’algoritme fa servir també el mètode mustFinish per detectar si la petició enviada implica una finalització de la connexió per tal de forçar la sortida del bucle.
Fora del bucle caldrà fer el tancament del sòcol de forma semblant de com s’ha realitzat en el servidor, assegurant l’ordre adequat de les peticions. És important comprovar si ja s’ha realitzat la petició del tancament de la connexió TCP usant els mètodes isShutDownInput o isShutDownOutput perquè no sabem quina de les parts (el servidor o el client) farà primer la petició.