

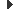
Tallafocs
Hi ha molts mecanismes per gestionar la seguretat en les xarxes. Un d’aquests mecanismes consisteix a utilitzar els tallafocs, que permeten definir visibilitats entre els equips que componen la xarxa. D’altra banda, mitjançant programari específic es pot conèixer l’estat de la xarxa i els intents d’intrusió que s’hi poden produir. En cas que finalment s’arribi a produir la intrusió, caldrà tenir a punt un procediment d’acció per evitar mals majors com la destrucció de pistes o que es torni a produir el problema.
Utilització d'eines de control del monitoratge en xarxes
Per a un monitoratge i un control complets de la xarxa i els sistemes que integra, cal fer servir un conjunt d’eines diferents que permeti tenir-ne una visió segons les necessitats de cada moment: no és el mateix intentar veure el patró que ha seguit un atacant per intentar descobrir els serveis de xarxa que trobar un atac de denegació de servei en la xarxa.
Alertes del funcionament de la xarxa i els sistemes que integra
Una primera eina imprescindible per controlar les xarxes és un sistema que avisa quan hi ha algun problema, sia per un mal funcionament del sistema o per un atac extern. Per tal que resulti una eina eficaç, cal configurar-la amb cura. D’aquesta manera, s’evitaran les notificacions errònies (falsos positius), la falta de notificació (falsos negatius) i les notificacions massives (la fallada d’un sistema fa saltar les notificacions de tota la resta). En general, aquest sistema d’avisos hauria de permetre, almenys, els tres nivells següents:
- Correcte: el sistema opera dins els paràmetres normals.
- Avís: el sistema s’ha desviat dels paràmetres normals i això pot comportar un problema en el servei.
- Alerta: el sistema es troba degradat o inoperatiu.
Per evitar les notificacions massives hi ha dos escenaris possibles:
- Si un element que deixa passar les comprovacions o les realitza per si mateix deixés de respondre, s’enviarien les notificacions no només de l’element que ha deixat de funcionar, sinó de tots els elements de què el servidor de monitoratge perd la visibilitat. Per evitar aquest cas, s’implementen dependències entres les comprovacions, de manera que abans d’enviar una notificació, cal verificar que l’element de què depèn funciona adequadament. Per tant, si falla un element determinat, només envia la notificació d’aquest element i no pas de tots els altres elements que en depenen.
- Si un equip s’atura, tots els serveis que estiguin en aquest equip deixen de respondre. Per poder enviar una modificació que indiqui que el servidor està apagat i que no tots els serveis han deixat de respondre, normalment es defineix una comprovació que, si falla, notifica que tot l’equip està apagat i no envia les notificacions de tots els serveis que conté.

El Nagios és una eina de codi lliure que permet monitorar serveis.
Gràfics de l'estat de la xarxa i els sistemes al llarg del temps
Un atac acostuma a generar un trànsit inusual en la xarxa. Per tant, és important mantenir un registre per tal de comparar l’estat actual amb l’anterior. No té gaire sentit elaborar gràfics amb les dades binàries (estat correcte / estat alerta). Tanmateix, pot ser molt útil elaborar-ne un que mostri dades com el trànsit, les sessions concurrents o la càrrega del sistema.
Una eina de codi lliure molt utilitzada per fer gràfics, tant de trànsit com d’altres tipus de dades, és el Cacti.
Detall de l'estat de la xarxa a l'instant
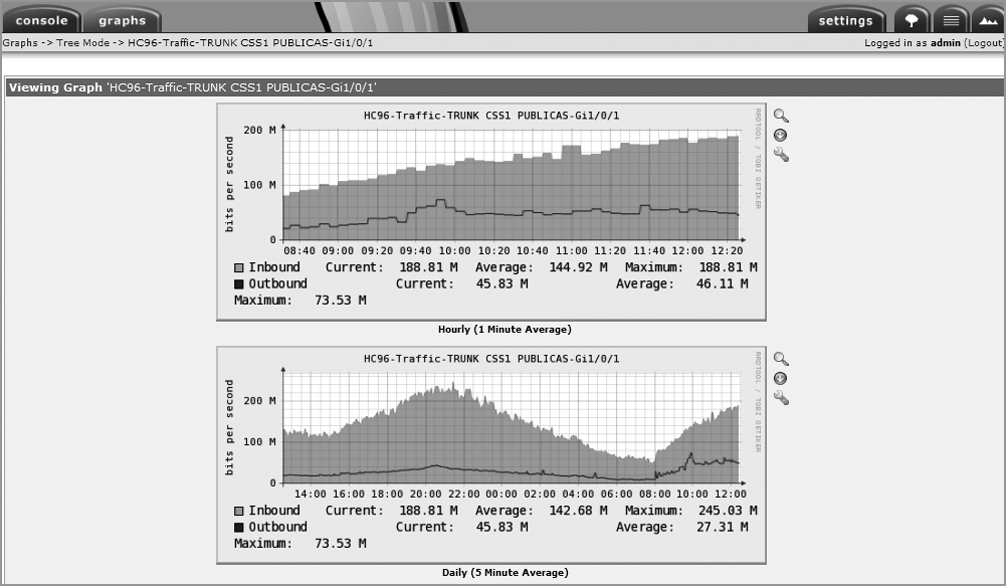
En cas que hi hagi algun problema en la xarxa, pot resultar molt útil disposar d’una eina que permeti veure què hi passa en un moment determinat. És important disposar d’una eina que agrupi les dades i les mostri de manera que amb una ullada puguem veure com funciona la xarxa, quin tipus de dades hi ha, quin n’és l’origen i quina n’és la destinació.
Si les dades estan agrupades, és fàcil deduir si hi ha cap problema i, en cas que n’hi hagi algun, identificar-lo per mitigar-lo.
Ntop és una eina de codi lliure que fa aquesta anàlisi instantània de l’estat de la xarxa.
Gestió i anàlisi de registres
Els registres (logs) que deixen les aplicacions són la millor font d’informació a l’hora de detectar un atac i prendre mesures per evitar-lo. Per detectar la manipulació dels registres, es pot fer servir un sistema que s’encarregui de recollir totes les dades. A aquest sistema es pot afegir la data de recepció per poder correlacionar les dades, emmagatzemar-les i signar-les electrònicament per tal de detectar si s’alteren.
Hi ha moltes maneres de centralitzar els registres de les aplicacions, però en sistemes UNIX se sol utilitzar el dimoni Syslog.
Els passos que se segueixen per configurar un sistema d’emmagatzematge de registres amb Syslog són els següents:
- Es configura un dimoni de Syslog a escala local perquè rebi els registres de les aplicacions i en conservi una còpia local durant un període de temps determinat. D’aquesta manera, es poden consultar directament des del sistema mateix.
- Es configura un dimoni de Syslog en un sistema remot que accepti dades i les emmagatzemi ordenades per data.
- El dimoni de Syslog del sistema en què hi ha l’aplicació va enviant una còpia dels registres al dimoni de Syslog remot.
- Quan els registres es troben en el sistema remot, es fa una signatura electrònica per poder detectar si s’alteren.
Anàlisi de registres
Quan les dades ja estan emmagatzemades, s’hi poden aplicar eines que permetin agregar-les a un informe sobre l’estat del programari o el sistema. Per exemple, mitjançant l’aplicació LogWatch, les dades d’un sistema Linux es poden agrupar. D’aquesta manera, es pot enviar un informe sobre l’activitat a l’administrador de sistemes.
També hi ha programari de caràcter més específic, com l’AWStats, que permet analitzar els registres de servidors web. Amb aquest programa es poden extreure dades molt importants si l’atacant no ha pogut alterar el sistema d’emmagatzematge de registres.
L’AWStats és un programari d’anàlisi de registres d’activitat de servidors web, correu i FTP.

Activitat a investigar
En general, el que cal buscar en els registres són les anomalies, ja que és molt complicat fer encaixar l’activitat que es genera en fer un atac amb el funcionament normal del sistema. Quan busquem anomalies, també es detecten falsos positius, activitat legítima que sembla il·lícita. Així doncs, convé actuar amb cautela per no treure conclusions precipitades.
Per exemple, en el cas d’analitzar els registres d’un servidor web, es podria començar a analitzar l’activitat buscant els punts següents:
- Els fitxers més consultats: entre els fitxers més populars és possible trobar contingut il·lícit si el servidor web s’està fent servir per distribuir-lo.
- Evolució del trànsit: en cas que hi hagi un increment sobtat del trànsit de dades, seria factible que es tractés d’un intent de denegació de servei o bé que s’hi hagués introduït algun contingut fraudulent. Així doncs, per poder valorar què passa en el servidor web, caldria estimar l’evolució de bytes enviats, les consultes per unitat de temps i els totals de consultes per IP.
- Consultes a fitxers que no existeixen (404): és possible que, per tal de comprometre un servidor web, s’hagi d’intentar diverses vegades. Algun d’aquests intents pot generar l’error 404 (not found), que queda registrat en els registres del servidor web. Si els errors 404 es comproven periòdicament, és possible tenir una idea del tipus d’atacs que pateix el servidor web en qüestió per prendre mesures.
IDS/IPS
La sigla IDS correspon a intrusion detection-system. Es tracta d’un sistema que detecta intrusions o intents d’intrusió i en notifica, però no els evita. D’altra banda, la sigla IPS correspon a intrusion prevention-system. El sistema, quan detecta un intent d’intrusió, es pot configurar per bloquejar-lo o bé pot afegir el sistema originant a una llista negra per evitar l’atac que ha detectat i intents futurs.
Hi ha diversos tipus d’IDS/IPS de caràcter general:
- IDS/IPS de xarxa: basa la detecció d’intrusions en l’anàlisi dels paquets que circulen per la xarxa. Un exemple de codi obert (open source) seria l’Snort.
- IDS/IPS de sistema: basa la detecció d’intrusions en l’anàlisi del conjunt del sistema. Un exemple de codi obert podria ser el Tripwire.
Els principals fabricants de sistemes IDS/IPS són els següents: TippingPoint, Radware, IntruShield, CISCO, Fortinet i Juniper.
També es poden implementar sistemes IDS/IPS més especialitzats que, com a contrapartida, consumeixen més recursos:
- IDS/IPS basat en el protocol: el sistema entén el protocol pensat per detectar i evitar que se’n faci un mal ús. Força que es compleixi adequadament.
- IDS/IPS basat en la lògica de l’aplicació: entén el protocol de comunicació i va més enllà. El sistema ha d’entendre la lògica de l’aplicació per fer que es compleixi. És el sistema més específic i, per tant, cal que s’adapti amb molta cura a l’entorn en què es desplega.
Configuració d'un IDS/IPS
Un sistema IDS/IPS es pot desplegar en maneres de funcionament diferents:
- Encaminament (routing): s’afegeix com un punt més de salt entre l’origen i la destinació del paquet. Com que per encaminar els paquets el sistema ha de tenir una IP, el fa més vulnerable als atacs.
- Passarel·la (bridge): el sistema IDS/IPS es configura per analitzar els paquets, però de manera que no esdevingui un salt més en la transmissió. D’aquesta manera, l’IDS/IPS és més complicat de detectar i no és possible accedir-hi directament, ja que no té una IP en el segment de xarxa pel qual passen els paquets.
- Port de còpia (network tap o port mirroring/spanning): l’IDS veu tot el que circula per un port determinat des d’un port diferent. Això fa que, malgrat que pot informar sobre tot el que veu, no hi pugui intervenir, ja que no es tracta de trànsit real, sinó d’una còpia. Pot ser molt útil per provar l’IDS/IPS abans de passar-lo a producció o bé per deixar-lo només en mode avís (IDS).
Instal·lació d'un IDS de xarxa
L’Snort és un dels sistemes de detecció d’intrusions de codi lliure més populars. A continuació, es veurà com instal·lar-lo i configurar-lo mitjançant el conjunt de regles lliures anomenades Emerging Threads.
Un port de còpia conté el mateix trànsit que passa pel port d’origen.
En aquest apartat es detallen els passos generals per fer una instal·lació del sistema IDS Snort en qualsevol sistema Linux. El mètode d’instal·lació pot tenir petites variacions al llarg del temps, de manera que sempre convé comprovar la documentació del sistema abans de començar.
A continuació, caldrà crear una base de dades MySQL per emmagatzemar les alertes.
Seguidament, s’haurà d’emplenar la base de dades amb la definició de les taules que hi ha en el directori schemas del codi font de l’Snort.
Tot seguit, caldrà configurar l’Snort adequadament. Per ser pràctics, es pot fer servir la plantilla que proporciona la distribució de l’Snort, però primer caldrà eliminar-ne unes quantes parts amb l’expressió regular següent:
Per adequar la configuració de l’Snort, cal editar el fitxer snort.conf amb algun editor de text i configurar-hi els paràmetres següents:
- HOME_NET: indica a l’Snort les xarxes que s’intenten protegir. Les xarxes hi apareixen separades per comes.
- EXTERNAL_NET: indica a quines xarxes externes estem connectats. Normalment es fa servir la inversa de la variable HOME_NET.
- output: indica on s’emmagatzemen els registres i els paràmetres per fer-ho. En cas de fer servir una base de dades MySQL, cal especificar-hi el nom d’usuari, la contrasenya, el servidor de bases de dades i el nom de la base de dades.
- include: permet indicar un fitxer auxiliar de configuració. Per exemple, pot servir per incloure còmodament totes les regles de la distribució Emerging Threads.
Emerging Threads es distribueix sota llicència BSD.
BASE (basic analysis and security engine)
BASE és una interfície web que permet agrupar les dades de les alertes i generar-ne informes fàcilment. A continuació, es veurà com instal·lar-la.
Amb el codi font de BASE descomprimit caldrà configurar un virtual host en un servidor web que disposi de PHP. En el cas de l’Apache, per exemple, la configuració seria la següent:
Un cop el servidor web ha llegit la configuració nova, cal accedir amb el navegador a l’adreça en què es troba la BASE per continuar la instal·lació. Les dades que demana són les següents:
- Seleccionar l’idioma i indicar la posició en el sistema de fitxer de l’ADODB. A l’exemple s’ha instal·lat a /var/www/admin/adodb.
- Introduir les dades de connexió al MySQL que s’han definit en els passos anteriors.
- Opcionalment, permet definir una contrasenya d’accés a la BASE.
Per generar gràfics amb la BASE, s’ha de disposar d’un conjunt de mòduls PEAR. Per instal·lar-los, farem servir les ordres següents:
Finalment, caldrà aixecar el dimoni Snort per començar a recollir informació. Per fer-ho, utilitzarem l’ordre següent:
/usr/local/bin/snort -c /usr/local/etc/snort/snort.conf -D
Atacs comuns
Amb el conjunt d’eines IDS/IPS és possible detectar els diferents atacs que pot patir una xarxa. Els més comuns són els que es detallen a continuació:
Malware és el conjunt de programari maliciós. S’hi inclouen els virus, els cucs, els cavalls de Troia, les eines d’intrusió (rootkits) i el programari de publicitat (adware), entre altres.
- Correu brossa. Actualment els virus, els cavalls de Troia i altres programes maliciosos (malware), un cop tenen el sistema infectat acostumen a enviar correu brossa. Per detectar aquest problema de seguretat, caldrà buscar sistemes que estiguin generant trànsit amb destinació al port 25 d’altres sistemes d’Internet.
- Denegacions de servei (DoS). Es tracta d’un problema de seguretat que busca deshabilitar un servei determinat. Hi ha moltes maneres de causar una denegació de servei. La més coneguda, perquè és la més complicada d’aturar, és llançar una gran quantitat de connexions simultànies. Això fa que els recursos del servidor s’esgotin o bé que, simplement, el trànsit legítim es redueixi com a conseqüència del trànsit de l’atac. Tot i això, aquesta no és l’única manera de provocar una denegació de servei. Per exemple, un paquet manipulat de manera especial pot fer que un dimoni produeixi un error intern i, consegüentment, el servei s’apagui. Si el dimoni en qüestió no disposa d’un sistema d’arrencada automàtic, es produeix una denegació de servei fins que un operador del sistema hi intervé.
- P2P/Programari piratejat. Actualment, en cas d’intrusió en un servidor, el més comú és que s’hi instal·li programari per enviar correu brossa. Anteriorment, els sistemes infectats se solien fer servir per distribuir programari piratejat (warez). En aquests casos, el trànsit d’FTP o de protocols P2P sol incrementar. Així doncs, per detectar aquest tipus d’incident, cal revisar l’increment d’aquests protocols mitjançant un IDS/IPS o bé un sistema d’anàlisi del trànsit.
- Pesca. Un altre efecte dels virus és la instal·lació de programari per robar informació. Un cop instal·lat, aquest atac pot ser complicat de detectar: cal analitzar els canvis en el sistema de fitxers, analitzar els fitxers de registre de tots els dimonis o bé fer captures del trànsit de la xarxa. En cas que la pesca faci servir un nom de domini diferent del nom propi del sistema, es podria analitzar el trànsit HTTP buscant la capçalera Host per detectar-lo. Si utilitzem tcpdump en Linux, ho podríem fer mitjançant les ordres següents:
El warez és un programari amb drets d’autor que es distribueix il·lícitament.
Si tinguéssim una mostra prou gran del trànsit, les peticions web es podrien analitzar mitjançant l’ordre següent:
L’ordre strings extreu les cadenes de text d’un fitxer binari.
Distribució de virus
Per poder fer els atacs que s’han descrit més amunt, és imprescindible propagar, mínimament, el programa maliciós. D’aquesta manera, en general, un equip infectat, independentment de la resta d’accions que se li poden fer emprendre, es converteix en un altre punt de propagació d’aquest programa. És imprescindible, doncs, analitzar periòdicament els equips per buscar-hi virus i altres tipus de programes maliciosos.
En el cas de Linux, es pot fer servir l’antivirus de codi lliure ClamAV per analitzar els sistemes.
Tallafocs en equips i servidors: instal·lació, configuració i utilització
Un tallafoc (firewall) és un sistema dissenyat per controlar l’accés a les xarxes i els sistemes. Aquest dispositiu pot funcionar com a element de xarxa i gestionar els permisos d’accés entre xarxes diferents i els nivells de confiança o bé com a aplicació en els amfitrions (hosts) per protegir tant les connexions entrants com sortints del sistema, concretament de la resta de la xarxa.
Àmbit de la protecció del tallafoc
Es pot fer una primera classificació dels tallafocs segons el que han de protegir:
- Tallafocs de xarxa: es tracta d’un element en la xarxa que regula les connexions entre els diferents segments de la xarxa. A part de les possibles connexions cap al tallafoc mateix, la funció principal que té és filtrar el trànsit que hi passa.
Els fabricants principals de tallafocs són Juniper, CISCO, CheckPoint, Fortinet i Stonesoft.
- Tallafocs personals (o de sistema): s’instal·la com una altra aplicació del sistema i la funció que té és filtrar el trànsit que s’hi dirigeix, tant connexions entrants (connexions que provenen d’altres sistemes) com connexions sortints (connexions que s’originen en el mateix sistema), que poden ser causades per altres aplicacions.
Preferentment, s’hauria d’aplicar un tallafoc de xarxa en lloc d’instal·lar un tallafoc de sistema a cada màquina. Els motius, que són diversos, són els següents:
- Es permet centralitzar la política de seguretat: un canvi d’adreçament global o d’un amfitrió implicaria accedir a tots els sistemes per reconfigurar els tallafocs.
- Si es desactiva el tallafoc d’un sistema, s’evita que tingui accés a la informació que circula per la xarxa.
Base del filtratge
També podem diferenciar els tallafocs en funció de les dades que fan servir per decidir si permeten o deneguen un determinat paquet:
- Tallafocs de filtratge de paquets sense estat (stateless): les dades que fan servir són, estrictament, les que conté el paquet. Normalment, les dades que s’utilitzen són l’origen, la destinació, el protocol i, si el protocol de transport ho suporta, el port d’origen i el de destinació.
- Tallafocs de filtratge de paquets amb estat (stateful): no només es basa en les dades que proporciona el paquet, sinó que també manté una taula interna d’estat. D’aquesta manera, permet identificar si un determinat paquet inicia una connexió nova, si és d’una connexió existent o si és un paquet invàlid. Això permet evitar atacs que injecten paquets amb un origen invàlid (passarien per un tallafoc sense estat) i provoquen denegacions de servei, però sense que estiguin relacionats amb cap connexió.
- Tallafocs a escala d’aplicació (proxy): aquesta classe de tallafocs no es limita a inspeccionar els paquets que passen per la xarxa, sinó que entén el protocol d’aplicació. Això permet que aquests tallafocs detectin si s’intenta fer servir el protocol d’alguna manera que pugui provocar algun tipus de comportament no desitjat o, fins i tot, filtrar segons el contingut. Evidentment, inspeccionar amb més profunditat el trànsit que circula implica un cost més gran.
Política per defecte de restriccions
És possible configurar tots els tallafocs per tal que tinguin dues intencions, denegar només un part del trànsit o bé permetre’n només una part:
- Política restrictiva: denega tot el trànsit, tret del que se li indica (equival a una llista blanca).
- Política permissiva: permet tot el trànsit, tret del que se li indica (equival a una llista negra).
Aparentment, el matís és molt subtil, però implica una gran diferència. Si s’implementa una política restrictiva, el que es necessita saber és què circula lícitament per la xarxa per permetre aquest trànsit. En canvi, si s’implementa una política permissiva, el que es necessita saber és quin trànsit no volem que circuli per la xarxa. Segons l’entorn, pot interessar més una política per defecte o l’altra. Preferentment, però, s’hauria de fer servir la política restrictiva, perquè com que només deixa circular el trànsit permès, s’evita la possibilitat d’haver oblidat algun trànsit potencialment perillós pel sistema.
A continuació, es mostren uns quants exemples d’aplicació d’aquestes polítiques. Són els següents:
- Si disposem d’un tallafoc i de dos servidors que només tenen un servidor SMTP, el més adequat seria aplicar-hi una política restrictiva i permetre, només, el trànsit amb destinació al port 25.
- La política permissiva podria ser adequada en cas de tenir un entorn de confiança en què, considerant la quantitat de tràfic que s’hi genera, no es vol penalitzar l’intercanvi de paquets, però sí restringir alguns ports administratius a un segment determinat de la xarxa.
Diferència entre filtratge per rang o per adreça
El filtratge dels paquets es pot fer tant per rang (segment de xarxa) com per IP (sistema). En general, els sistemes s’haurien de separar en diferents segments segons la funció que fan. Preferentment, també caldria especificar la visibilitat per a cada segment en el tallafoc. Si, per algun motiu, es vol introduir una regla per a un sistema específic, cal valorar, abans de fer-ho, si aquest sistema és prou diferent per tenir un segment independent.
Tipus de bloqueig
Els tallafocs també es poden classificar segons la política que segueixen en bloquejar una transmissió. La divisió és la següent:
- Descarta (DROP): descarta el paquet completament sense notificar-ho a qui l’ha enviat.
- Rebutja (REJECT): descarta el paquet i ho notifica a qui l’ha enviat.
És més recomanable fer servir una política per defecte de descartar, ja que s’evita que un possible atacant esbrini si el tallafoc ha passat el paquet o l’ha filtrat. Tot i així, per facilitar l’administració de xarxes, és interessant fer servir la política de rebutjar en les xarxes internes, ja que ajuda a diagnosticar problemes de connectivitat.
Comparació entre descartar i rebutjar
Un atacant podria intentar esbrinar si un dimoni escolta o no un port UDP. El protocol de transport UDP no estableix cap connexió. Per tant, a l’hora de fer un escaneig de ports UDP, s’espera rebre un paquet ICMP de tipus 3 (unreachable). Si no es rep, se suposa que el port és obert. Podem comprovar-ho mitjançant l’eina nc i tcpdump.
Primer de tot, des d’una consola Linux, cal executar el tcpdump i limitar-ne la sortida al port UDP/53 o missatges ICMP:
A continuació, en una altra consola amb l’nc (netcat), es pot fer la prova en qualsevol servidor d’Internet. Podrem comprovar que, en cas que tinguin una política de rebutjar o bé no tinguin cap tallafoc, no ens sortirà cap missatge.
Tanmateix, en la consola del tpcdump veurem una sortida similar a la següent:
En cas que el servidor sí que tingui habilitat el DNS o bé tingui la política de descartar el paquet en el tallafoc, l’nc mostrarà el missatge següent:
En la terminal del tcpdump es veuran diversos enviaments sense cap resposta:
10:09:22.117146 IP 10.10.1.59.48166 > 84.88.0.3.53: [|domain] 10:09:22.117577 IP 10.10.1.59.48166 > 84.88.0.3.53: [|domain] 10:09:23.117871 IP 10.10.1.59.48166 > 84.88.0.3.53: [|domain] 10:09:24.118217 IP 10.10.1.59.48166 > 84.88.0.3.53: [|domain] 10:09:25.118552 IP 10.10.1.59.48166 > 84.88.0.3.53: [|domain]
En resum, es pot veure que si s’envia un paquet UDP a un sistema, poden passar dues coses:
- Si retorna un paquet ICMP: el port UDP està filtrat amb una política de rebutjar o bé no hi ha cap dimoni que escolti en el port.
- Si no retorna res: el port UDP està filtrat amb una política de descartar o bé hi ha un dimoni que escolta en aquest port.
Per diferenciar si és un filtratge o si, realment, s’arriba en un port en què hi ha un procés que escolta, el comportament del sistema es pot verificar amb la resta de ports UDP.
Configuració del tallafoc
Com en el cas de l’IDS/IPS, hi ha dues maneres diferents de configurar un tallafoc.
- Passarel·la (bridge): com en el cas d’un IDS/IPS, el tallafoc és transparent a la xarxa. No disposa d’una adreça i, per tant, no s’hi pot accedir directament per mitjà de les xarxes que protegeix. La instal·lació del tallafoc consisteix a recollir els paquets d’una interfície i, sense modificar-los, injectar-los en una altra interfície de xarxa segons les regles de filtratge.
- Encaminament (routing): es tracta del mètode més comú. Es configura el tallafoc de manera que actuï com a porta d’enllaç (gateway) de les xarxes que protegeix. Així, totes les connexions que s’estableixen entre xarxes diferents hi han de passar.
Si es tracta d’un IDS, configurar-lo en un port de còpia té sentit. Tanmateix, en un tallafoc només tindria sentit en cas de voler fer una prova per verificar-ne la configuració abans d’aplicar-la al tallafoc real.
Altres característiques dels tallafocs
Hi ha altres característiques que, tot i no ser pròpies dels tallafocs, es troben en la majoria.
- NAT/PAT. El NAT (traductor d’adreces de xarxa, network address translator) és un sistema de traducció de l’adreçament. Quan el paquet arriba al tallafoc, l’adreçament es tradueix a un altre adreçament diferent. Normalment es fa servir per comunicar un conjunt de sistemes (normalment amb adreçament privat amb la resta d’Internet fent servir una sola IP pública). Així doncs, tota una xarxa queda amagada rere una IP. Segons l’adreça que es modifica, es parla d’SNAT (modificar l’adreça origen) o bé de DNAT (modificar l’adreça destinació).
El terme PAT (port address translation) implica no només una redefinició de l’adreçament, sinó també del port.
L’adreçament privat es defineix en l’RFC-1918 i són les xarxes 10.0.0.0/8, 172.16.0.0/12 i 192.168.0.0/16.
- VPN. El VPN (xarxa privada virtual, virtual private network) és una xarxa implementada sobre una capa de programari (que normalment xifra el trànsit). A la vegada, la capa de programari està implementada sobre una altra capa ja existent de xarxa. Això permet crear xarxes sobre xarxes que ja existeixen. Normalment es fa servir per connectar a la xarxa interna des d’un punt remot per mitjà de la xarxa pública d’Internet.
Hi ha targetes amb unitats de procés especialitzades a fer el xifratge. Per tant, en general, no ho fa la unitat de procés del tallafoc, sinó una targeta amb una unitat de procés especialitzada a fer aquesta operació. - IDS/IPS. Tot i que no és la funció que fa, un tallafoc també pot actuar com a IDS/IPS. Normalment, per afegir-hi aquesta càrrega extra, s’afegeix una altra targeta al sistema. D’aquesta manera, s’aconsegueix que reparteixi la càrrega de la feina extra que ha de fer en inspeccionar els paquets per cercar-hi signatures.
Limitacions dels tallafocs
Els tallafocs són una eina imprescindible per garantir la seguretat en les xarxes. De totes maneres, no són infranquejables i tenen limitacions com les següents:
- No protegeixen d’errors de seguretat dels serveis a què permet el trànsit. Per exemple, si a causa de l’entrada d’una cadena manipulada de manera especial a un formulari web, s’accedeix a dades confidencials, el tallafoc no serà capaç de detectar-ho.
- No protegeix d’atacs entre equips connectats en el mateix segment perquè el trànsit no passa pel tallafoc.
- És possible encapsular trànsit dins altres protocols (ICMP, DNS, etc.), cosa que permet crear túnels que comuniquen dos extrems per mitjà d’un tallafoc.
- Si s’obre un port en el tallafoc, no és possible assegurar que el protocol que a priori hauria de circular per aquest port sigui, forçosament, el protocol que hi passa en realitat. Per detectar aquesta situació, seria necessari inspeccionar els paquets.
Sistema tallafoc de Linux
Les iptables són una eina que permet configurar les regles de filtratge del tallafoc que implementa el Kernel Linux. L’entorn que implementa efectivament les regles de filtratge s’anomena netfilter. Per fer-ho, utilitza lligams (hooks) en el sistema de procés d’un paquet. Com que tots dos estan tan relacionats, sovint, per fer referència a aquest conjunt, s’utilitza simplement el terme iptables.
Per poder fer operacions amb les iptables és necessari tenir privilegis d’administració del sistema, o fent servir l’usuari primari (root user) o fent servir permisos donats per l’administrador de l’equip mitjançant sudo.
Taules
El mode de funcionament de les iptables agrupa les regles de filtratge de paquets en taules segons la funció i el punt de processament:
- filter (taula per defecte): defineix la política que defineix com un paquet, generat per un procés local del sistema, entra en un procés (entrada, INPUT), passa pel sistema (avançament, FORWARD) o en surt (sortida, OUTPUT). En els lligams que té en comú amb la resta de les taules, aquesta és la taula menys prioritària.
- nat: defineix com es modifiquen i es redirigeixen els paquets quan es crea una nova connexió, segons si surten del sistema des d’un procés local (OUTPUT), entren per la interfície de xarxa (PREROUTING) o estan a punt de sortir per la interfície de xarxa (POSTROUTING).
- mangle: defineix com es modifica un paquet que entra per la interfície de xarxa (PREROUTING), travessa el sistema (FORWARD) i està a punt de sortir per la targeta de xarxa (POSTROUTING) o bé entra (INPUT) o surt (OUTPUT) d’un procés local del sistema. En els lligams que té en comú amb la taula nat, aquesta taula té més prioritat.
- raw: aquesta taula té més prioritat que la resta. Defineix dos lligams amb més prioritat que la resta de taules. I això abans que s’apliqui el mòdul conntrack. Es fa servir, doncs, per afegir regles sense estat. Els paquets que entren per una interfície de xarxa (PREROUTING) o que surten (OUTPUT) d’un procés local, es poden filtrar amb aquesta taula.
Cadenes (chains)
Hi ha dos tipus de cadenes o chains: les que estan predefinides i les que crea l’usuari. Pel que fa a les predefinides, n’hi ha una per cada lligam i taula. Per exemple, en la taula filter hi ha tres cadenes predefinides: INPUT, OUTPUT i FORWARD.
Per evitar repetir regles en cada cadena predefinida, l’usuari en pot crear de pròpies i les pot agrupar com convingui. Mitjançant l’opció -N es pot crear una regla nova:
A continuació, aquesta cadena es pot afegir a la resta de cadenes per tal que quan un paquet passi per algun dels lligams, també passi per aquesta cadena nova:
Ordre de processament d'un paquet
Tal com es pot veure en la taula, l’ordre que seguiria un paquet per aquestes taules i lligams depèn de l’origen i la destinació que tingui.
| Origen i destinació | Ordre |
|---|---|
| D’una interfície de xarxa a un procés local | 1. mangle (PREROUTING) 2. nat (PREROUTING) 3. mangle (INPUT) 4. filter (INPUT) |
| D’un procés local a una interfície de xarxa | 1. mangle (OUTPUT) 2. nat (OUTPUT) 3. filter (OUTPUT) 4. mangle (POSTROUTING) 5. nat (POSTROUTING) |
| D’un procés local a un altre procés local | 1. mangle (OUTPUT) 2. nat (OUTPUT) 3. filter (OUTPUT) |
| El paquet no va dirigit al sistema, sinó que el travessa | 1. mangle (PREROUTING) 2. nat (PREROUTING) 3. mangle (FORWARD) 4. filter (FORWARD) 5. mangle (POSTROUTING) 6. nat (POSTROUTING) |
Un paquet parteix d’un lligam i va travessant seqüencialment les regles de cada cadena fins que passa el següent:
- Una regla concorda i fa una crida a alguna acció (target).
- Es crida a l’acció RETURN explícitament mitjançant -j RETURN o bé implícitament en no haver-hi més regles en la cadena.
Accions (targets)
Les accions per defecte són les següents:
- ACCEPT: permet el pas del paquet.
- DROP: descarta el paquet.
- QUEUE: passa el paquet a l’espai d’usuari perquè una aplicació el processi. Si no hi ha cap aplicació, es descarta.
- RETURN: acaba el processament de la cadena i torna a la cadena anterior. És útil per deixar de processar una cadena si ja sabem que no coincidirà amb les regles següents. Per exemple, si veiem que és un paquet UDP i les regles de la cadena són totes per a TCP.
A més a més, una acció molt utilitzada, tot i que és un mòdul independent, és REJECT, que en lloc de descartar el paquet, el rebutja i envia un paquet ICMP com a resposta.
Opcions generals per aplicar un filtre
Per filtrar el paquet hi ha moltes opcions disponibles, tant opcions que estan incloses per defecte en les iptables com altres que estan desenvolupades com a mòduls. A continuació, s’exposen les més comunes:
- -s (IP origen) / -d (IP destinació): permet especificar tant la IP d’origen coma la IP de destinació. Si una opció no s’especifica, se suposa que s’indica una IP qualsevol.
- -i (interfície d’entrada) / -o (interfície de sortida): pot set tant una interfície física com un túnel o una passarel·la. A més, permet especificar expressions regulars per indicar totes les interfícies d’un tipus concret.
- -p (protocol): permet separar entre trànsit TCP, UDP i ICMP o tots els trànsits (mitjançant all).
- -sport / -dport: permet especificar tant el port d’origen (sport) com el port de destinació (dport) si el protocol de transport deixa utilitzar ports. Passa el mateix que amb les IP d’origen i de destinació: si no s’especifica, se suposa que pot ser qualsevol.
- –state: en totes les taules, excepte la RAW, es pot fer servir l’estat de la connexió. Els estats possibles són els següents:
- INVALID: el paquet no s’ha pogut identificar amb cap connexió ja existent. Independentment de possibles atacs, és possible que es produeixi aquest estat si hi ha poca memòria per mantenir la taula d’estats de les connexions.
- NEW: el paquet ha establert una connexió nova.
- ESTABLISHED: el paquet pertany a una connexió ja establerta.
- RELATED: el paquet és una connexió nova, però està relacionada amb una connexió que ja està establerta. Un exemple podria ser la connexió de dades d’FTP o bé un paquet ICMP.
Política per defecte de la cadena
Amb el paràmetre -P es pot definir la política per defecte d’una cadena. Per exemple, per definir com a política per defecte que la cadena INPUT sigui descartar, la de FORWARD rebutjar i la d’OUT acceptar s’haurien d’executar les ordres següents:
Exemples de regles
En una política de filtratge restrictiva. Per permetre tots els paquets UDP des d’una xarxa (10.0.0.0/8) cap a un equip que els escolti en el port 138, caldria aplicar la regla següent:
D’altra banda, en una política permissiva, per rebutjar un determinat paquet per port destinació, independentment del protocol, caldria aplicar la regla següent:
En una porta d’enllaç, per fer nat sortint per una interfície de xarxa amb IP estàtica, es pot fer mitjançant l’acció SNAT:
iptables -t nat -A POSTROUTING -o eth1 -j SNAT
En cas de disposar d’una IP dinàmica, cal afegir la lògica encarregada del cas què la IP canvia (el temps durant el qual la interfície no està disponible i el mateix canvi d’IP). L’acció MASQUERADE s’encarrega de gestionar-ho a un cost de procés per petició més gran.
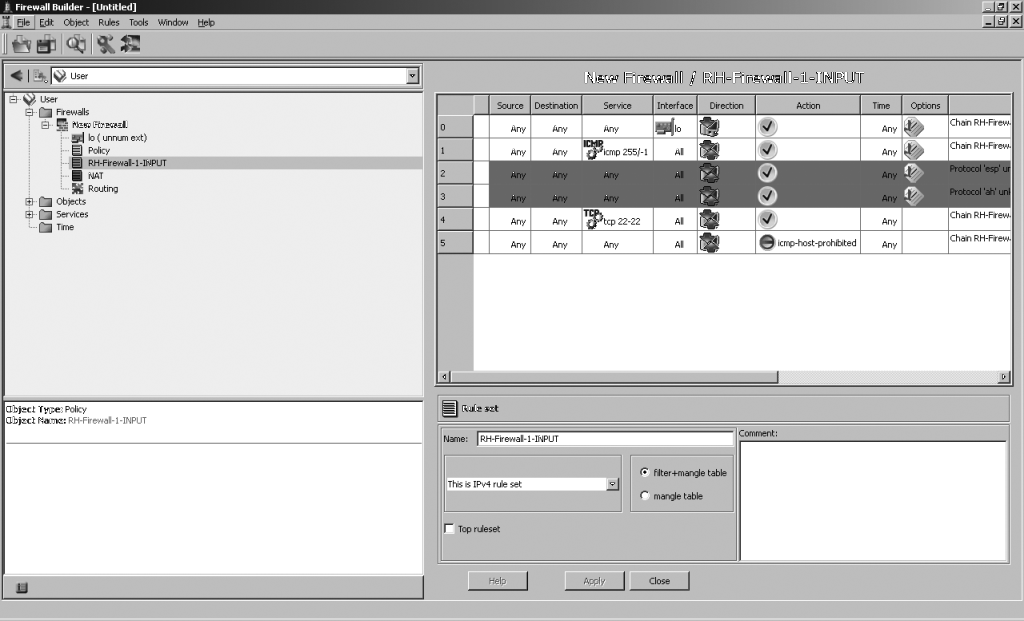
Interfícies gràfiques per a tallafocs
Hi ha una gran quantitat d’interfícies gràfiques que permeten gestionar tant iptables com altres sistemes tallafoc.
Generalment, cada distribució inclou la seva pròpia interfície gràfica per al tallafoc. Generalment, aquesta interfície està pensada per habilitar i desactivar conjunts de regles predefinides. Per fer configuracions més complexes, cal fer servir la línia d’ordres o programari específic, que és molt més complex.
Un exemple d’interfícies gràfiques per a configuracions complexes és l’Fwbuilder, que, a més de permetre configurar iptables, permet configurar encaminadors CISCO, Firewalls CISCO PIX i diferents tallafocs de sistemes BSD: ipfilter, pf i ipfw.
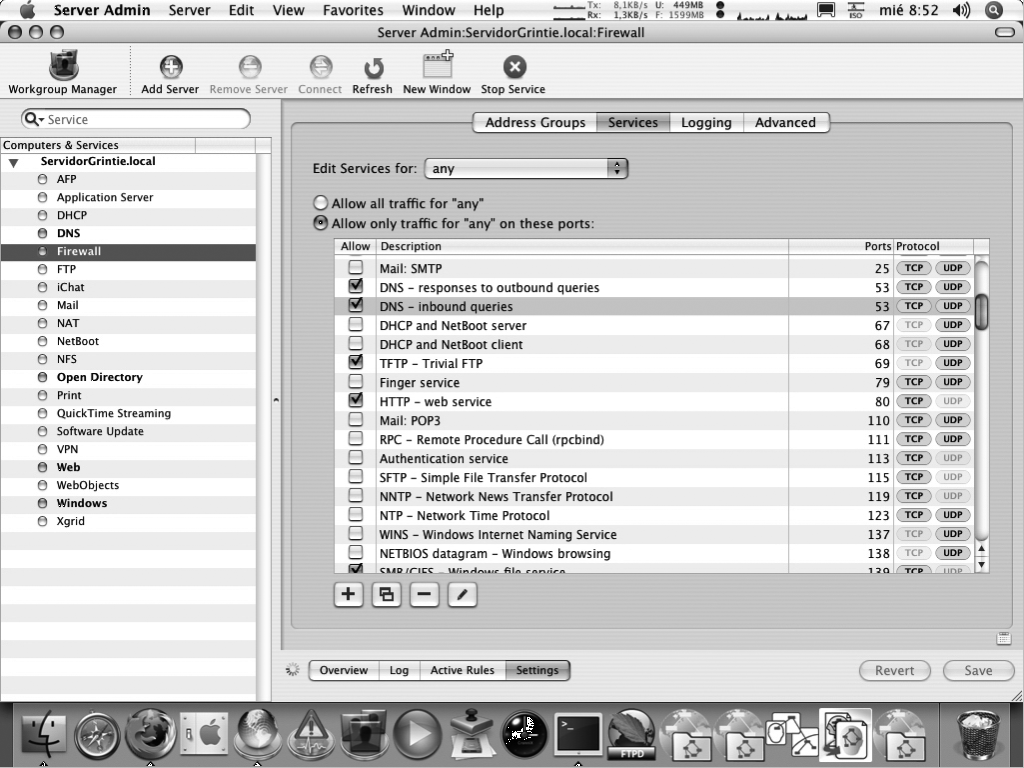
Interpretació i utilització com a ajuda de documentació tècnica
Per considerar un sistema en producció primer caldria que el sistema passi pels entorns de proves, preproducció i producció. A més, cal generar documentació per poder fer el procés repetible, els procediments associats al servei segons sigui necessari i un sistema de monitoratge perquè les fallades del servei siguin detectades.
Instal·lació i posada en marxa d'un sistema
Des del punt de vista de la seguretat, un sistema hauria de passar per tres fases abans de posar-se en funcionament. Aquestes fases han de correspondre a l’estat de la instal·lació del sistema per evitar que una mala configuració d’un sistema de proves pugui ser la porta d’entrada d’un intrús.
- Entorn de proves. Primer de tot, caldria que es posés en un entorn adequat per poder fer les primeres proves de funcionament del sistema. Convé que aquest entorn estigui al més aïllat possible, ja que, en una fase inicial de proves, no es pot esperar que els serveis estiguin configurats correctament ni que els usuaris no hagin de fer servir contrasenyes fortes.
Cal evitar que un entorn de proves estigui exposat a atacs externs per mitjà de la publicació de serveis. - Entorn de preproducció. En una segona fase, el sistema ja està configurat com si estigués a punt de posar-se en producció. En aquesta fase, és possible que personal extern de l’organització hagi de poder accedir al sistema per fer-hi unes primeres proves abans de validar-lo i passar-lo a producció. Així doncs, caldria poder tenir el sistema amb els serveis definitius, ja configurats correctament, publicats, però amb l’accés limitat.
Un cop el sistema està validat com a correcte, la documentació del sistema, els procediments per operar-hi i les degudes mesures de seguretat aplicades, es pot passar a l’entorn de producció. - Entorn de producció. Un cop superades les fases anteriors, el sistema està llest per posar-se en funcionament. Això el farà més sensible a atacs, ja que tindrà menys restriccions d’accés. En aquest punt, s’hi ha de limitar l’accés i els registres s’han de controlar de manera periòdica per verificar-ne el funcionament sense incidències.
Un entorn de producció ha d’estar documentat i monitorat correctament. Igualment, ha de tenir les polítiques de seguretat adequades.
Documentació del sistema
Per tal d’instal·lar el sistema correctament, cal consultar la documentació del producte mateix. Sol estar en anglès.
És molt normal fer cerques amb cercadors per trobar configuracions predefinides. D’aquesta manera, no s’ha de començar de zero. Tot i que la informació que es pot trobar a Internet pot ser molt útil, sempre cal comprovar-la i contrastar-la. És possible que les dades que es trobin continguin problemes de seguretat accidentals o intencionats. Si són intencionats, l’atacant espera que algú faci servir les dades i, després, aprofita la mala configuració per accedir al sistema.
L’anglès s’ha convertit en la llengua més utilitzada per a la documentació tècnica.
Durant el procés, cal documentar-ho tot, però especialment les fonts que utilitzem. Si emmagatzemem les dades en un sistema de gestió del coneixement, evitarem haver de repetir tot l’esforç que hem fet per posar el sistema en funcionament. D’aquesta manera, podrem repetir el procés seguint la documentació que hem generat prèviament.
MediaWiki és un programari de codi lliure que pot funcionar com a sistema gestor del coneixement.
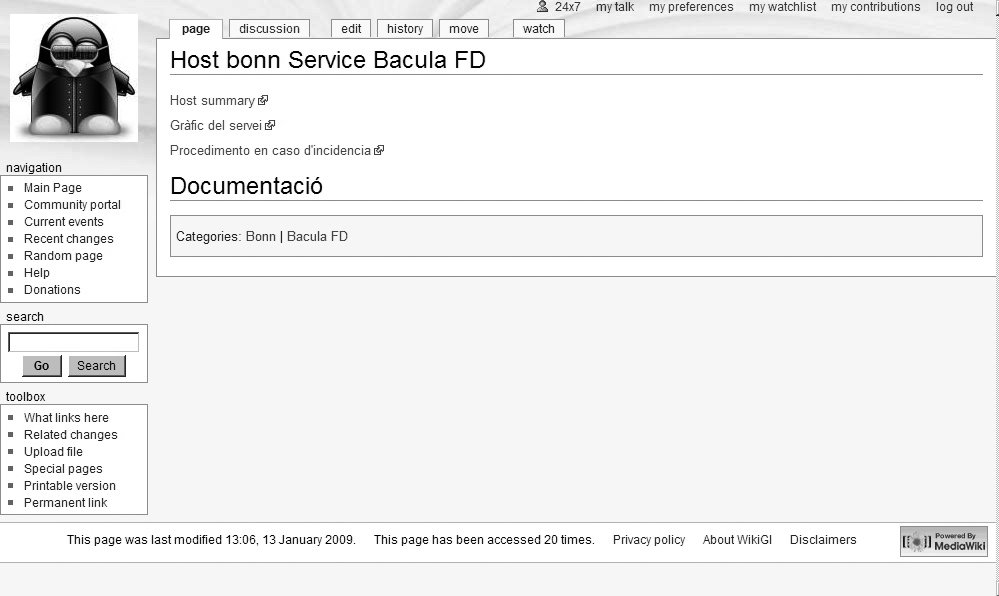
Procediments del sistema
Un cop el sistema s’ha instal·lat correctament, també cal documentar com cal operar-lo per mantenir-lo en funcionament. A continuació, s’exposen uns quants procediments bàsics que permeten operar qualsevol sistema.
- Arrencada. Un dels procediments més importants és saber com cal arrencar un servei determinat. Alguns sistemes poden ser tan simples que només faci falta prémer el botó d’arrencada per fer-los funcionar. Tanmateix, en altres sistemes, el procediment pot ser més complex. Per exemple, per arrencar un clúster compost per un conjunt de balanceigs de càrrega, un conjunt de servidors web i un conjunt de servidors de bases de dades, primer s’haurien d’arrencar les bases de dades, després els servidors web i finalment els balancejos. Si es fes a l’inrevés, les primeres capes saturarien les segones, que encara no estarien preparades, i l’arrencada podria fallar o trigar molt més temps.
- Comprovació del funcionament. Un cop arrencat el sistema, cal poder validar que funciona correctament. S’ha de comprovar que els components funcionen separadament i conjuntament. Per exemple, es pot comprovar separadament el funcionament d’un servidor web i el de la base de dades, però no es pot estar segur que funcionen en conjunt si no es fa una petició a la base de dades amb el servidor web.
- Comprovació de la configuració. En l’operació de qualsevol servei, el més normal és que s’hagin d’aplicar canvis en la configuració o que calgui afegir-hi entrades a mesura que passi el temps. Per això, cal saber com verificar la configuració abans d’aplicar-la.
Aplicar una configuració sense cap verificació (error d’operació) sol ser una de les causes de caiguda en dels serveis. Per això és important tenir ben documentats els passos que s’han de seguir per modificar-ne les configuracions i la manera adequada de verificar-hi els canvis. - Aturada. L’aturada d’un servei, com l’arrencada, pot ser molt simple en la majoria dels casos, però, quan l’entorn és complex, pot ser més complicat. Seguim l’exemple del clúster: si primer s’apaga la base de dades i els servidors web continuen rebent peticions, aquestes peticions inacabables els poden saturar perquè no hi ha base de dades. Així doncs, en un entorn com aquest, el més adequat seria redirigir primer les peticions a un altre entorn en els balanceig de càrrega, apagar els servidors web i, finalment, les bases de dades.
No es pot considerar que un sistema complex funciona correctament només pel bon funcionament, separadament, de les parts que l’integren, ja que el programari que fa interactuar aquests components també pot fallar.
Monitoratge del sistema
És important que un sistema estigui monitorat constantment abans que passi a producció. D’aquesta manera, les fallades es detectaran quan es produeixin i es podran solucionar al més aviat possible.
El monitoratge dels serveis és important per assegurar que es troben dins els paràmetres del nivell de servei establert (SLA: acord de nivell de servei, service level agreement).
Disponibilitat del sistema
La disponibilitat del sistema es calcula mitjançant el percentatge del temps durant el qual el servei ha estat disponible. En cas de càlcul anual, per als percentatges de disponibilitat que es mostren a continuació, el temps d’aturada seria el següent:
- 99%: 87 hores anuals (7 hores mensuals) d’aturada
- 99,9%: 8 hores anuals (43 minuts mensuals) d’aturada
- 99,99%: 52 minuts anuals (4 minuts mensuals) d’aturada
- 99,999%: 5 minuts anuals (26 segons mensuals) d’aturada
- 99,9999%: 30 segons anuals d’aturada
Supervisió i monitors reactius
Per millorar la disponibilitat del sistema, és una pràctica força comuna disposar d’un programari que supervisi els dimonis que hi pugui haver, sia en un clúster o només en un node.
Daemontools és un programari de codi lliure que reinicia automàticament els dimonis si s’han aturat.
Aquest tipus de supervisió dels dimonis acostuma a reduir considerablement el temps de caiguda dels serveis, ja que, en alguns casos, el problema se soluciona quan, simplement, el dimoni es torna a aixecar.
Si el problema no és simplement un dimoni que té un error intern i s’atura, sinó que es tracta d’un procés que, tot i estar actiu, ha deixat de respondre, cal tenir un monitor configurat amb una acció definida que ha de dur a terme en cas que passi.
MONIT és un programari de codi lliure dedicat a la gestió de processos i sistemes de fitxers que permet fer tasques de manteniment de manera automàtica: permet configurar monitors reactius.
Realització d'informes d'incidències de seguretat
Quan hi ha un incident de seguretat, primer cal notificar l’incident als responsables dels sistemes involucrats i procedir amb cautela.
Una de les tendències més comunes és entrar als equips involucrats i començar a buscar-hi sense saber exactament què passa. D’aquesta manera, es poden destruir pistes que poden ajudar a entendre què ha passat. Per tant, el primer que s’ha de fer és conservar la calma i seguir els punts següents:
- S’ha d’informar del possible incident de seguretat al responsable corresponent.
- Cal esbrinar si es tracta realment d’un incident de seguretat. Moltes vegades, un mal funcionament d’un sistema pot ser degut a una sobrecàrrega legítima o a una mala programació.
- Si realment és un incident, cal obtenir tota la informació possible per si pot servir de prova.
- S’ha d’intentar contenir l’incident per evitar que es propagui, sempre s’ha d’intentar reduir els danys que es pugin produir. Si és necessari, pot arribar a ser imprescindible bloquejar l’accés a l’equip o conjunt d’equips involucrats.
- Cal aplicar un pla per reduir o eliminar el risc que l’incident es torni a produir.
- Finalment, cal documentar tant l’incident com el procés i la metodologia seguida.
Per tal d’elaborar un informe complet sobre l’incident, cal que tingui els punts següents:
1) Descripció. El document ha de començar amb una introducció sobre l’incident i un conjunt de dades bàsiques. Són les següents:
- Breu descripció de l’incident a manera de títol.
- Personal implicat.
- Data i hora de l’inici de l’incident.
- Data i hora en què es dóna per finalitzat l’incident.
- Nivell d’afectació: es poden tenir diferents nivells amb diferents criteris, però això depèn de l’organització. De manera genèrica, es poden fer servir els nivells següents:
- Greu: implica un problema de seguretat que ha causat danys en els sistemes afectats. Per tant, cal resoldre’l al més aviat possible i de manera ininterrompuda. Per exemple, si la base de dades principal de l’entitat queda fora de línia, farà falta que hi hagi una implicació total per resoldre-ho.
- Moderada: implica un problema que només ha degradat el servei o ha afectat parts no crítiques. Això sol indicar que la resolució s’ha de dur a terme durant la jornada laboral següent. Per exemple, si arran d’un atac de denegació de servei un sistema intern queda aturat, es pot resoldre quan la jornada laboral es reprengui.
- Lleu: implica un problema que s’ha detectat, però no ha tingut cap impacte en els sistemes. Sol demanar un temps de resolució més llarg, per exemple, durant la setmana següent a la detecció. Quan apareix un error de programació en algun programari que s’utilitza i, per això, cal aplicar els pedaços adients durant els dies següents.

2) Resum. A continuació de la descripció, cal fer un resum breu del problema, l’afectació, les causes i la solució perquè no es repeteixi. Mitjançant aquest resum, una persona no tècnica hauria de ser capaç d’entendre què ha passat i quines mesures s’han pres per evitar el mateix incident en un futur.
3) Anàlisi. L’anàlisi de l’incident ha de ser el cos del document i s’hi ha de poder seguir, pas a pas, què ha passat i com s’ha solucionat. Per això cal dividir aquesta anàlisi en tres parts diferenciades. Són les següents:
a) Procediment i metodologia. És important definir com s’ha actuat envers l’incident per tal de poder entendre, posteriorment, les decisions que s’han pres durant l’actuació. Tot i que el resultat pot ser el mateix, el mètode utilitzat pot invalidar les conclusions. Per exemple, si no s’ha comprovat la integritat d’un fitxer de registre, aquest fitxer pot haver estat alterat.
Un cop recollides les dades, cal poder verificar la validesa de totes les dades recollides.
Per poder estar segurs que les dades que mostra el sistema són reals, convé tenir el conjunt d’eines que siguin necessàries compilades estàticament (sense llibreries del sistema que hagin pogut ser manipulades). Aquests fitxers s’han de transmetre al sistema d’una manera que impedeixi que es puguin modificar, per exemple, mitjançant un CD-ROM.
Amb aquests fitxers d’anàlisi cal anar escrivint els resultats en un sistema remot que tingui un sistema de comprovació, per exemple, l’MD5 o l’SHA1.
MD5 i SHA1...
… són dos algorismes que generen un número de longitud fixa, que permet detectar si un fitxer ha estat modificat respecte del moment de generació.
Per conservar l’estat del sistema adequadament, és útil obtenir la informació següent:
- Hora del sistema: permet identificar l’hora real dels registres. Si el sistema tingués una hora diferent de la real, els fitxers de registre també la tindrien modificada.
- Taules amb informació volàtil: per exemple, pot ser interessant obtenir la taula ARP i la taula d’encaminament del sistema.
- Connexions de xarxa: si l’atacant està connectat al sistema o envia ordres asincrònicament (sense mantenir una connexió activa) pot ser important tenir el conjunt de connexions actives i pendents.
La taula ARP conté les adreces físiques dels equips als que el sistema està directament connectat.
A continuació, caldria obtenir una còpia de totes les dades que puguin tenir alguna pista, com les dades i les metadades en disc. Convindria obtenir aquesta informació mitjançant una imatge completa del disc.
Seguidament, es poden investigar els processos del sistema. Així doncs, primer de tot cal esbrinar els mòduls que té carregats per si n’hi ha algun que pugui interferir en l’anàlisi. A continuació, pot ser útil verificar els processos actius, quins fitxers tenen oberts i quines crides al sistema estan fent.
El sistema de fitxers proc de Linux pot ajudar a fer una anàlisi dels processos actius.
Mitjançant totes aquestes dades, es pot obtenir una imatge bastant clara de l’estat d’un sistema.
b) Documentació. Durant la resolució d’un incident, el més normal és consultar documentació sobre el tema en qüestió, ja que és impossible tenir totes les dades al cap per poder actuar. Convé, doncs, apuntar tota la documentació, tant interna com externa.
En cas que sigui documentació interna, és especialment recomanable identificar quina s’ha fet servir per, després, poder-la corregir o adequar si és necessari.
Contràriament, si s’ha fet servir documentació externa, posteriorment es podrà contrastar la informació per veure si s’ha procedit adequadament i generar, després, documentació interna per poder actuar més ràpidament i no haver de dependre de tercers.
c) Incidències detectades. Finalment, cal destacar la incidència o conjunt d’incidències detectades. Quan s’investiga un incident determinat, no és estrany detectar altres possibles punts d’accés al sistema.
4) Pla d’acció. Un cop s’ha entès el problema, convé prendre mesures per evitar que es repeteixi en un futur. En determinar un pla d’acció, és possible trobar diverses situacions. A continuació, se n’exposen unes quantes.
- Una mala configuració. Si el problema ha estat una configuració deficient, caldrà verificar tota la configuració del servei implicat, ja que s’hi podrien detectar altres problemes de configuració.
- Un error (bug) sense cap pedaç disponible. Si el problema detectat és un error en la programació del servei que necessita un pedaç que encara no ha estat disponible, convindrà considerar diverses opcions:
Si és possible desactivar el servei fins que se solucioni el problema, es pot deixar desactivat per evitar futures intrusions mentre els desenvolupadors corregeixen el problema. En cas contrari, si el servei no es pot desactivar, caldrà veure si és possible mitigar el risc mitjançant alguna tècnica.
Generalment, s’utilitza una gàbia mitjançant el chroot per evitar que una fallada en un servei afecti tot el sistema.
El chroot permet aïllar un servei de la resta del sistema.
- Un error amb un pedaç disponible. És possible que un cop investigat un incident, es detecti que cal aplicar un pedaç al sistema per corregir la porta d’entrada que s’ha fet servir per atacar-lo.
En aquest cas, cal deixar especificat el pedaç que s’hi ha d’aplicar per comprovar-lo en un entorn de proves abans d’aplicar-lo al sistema de producció. - Un mal ús dels serveis de xarxa. També és possible que es tracti d’un mal ús dels serveis publicats. Per tant, en aquest cas convindrà veure si és possible establir una política d’ús màxim del recurs per evitar que, en un futur, el mal ús del recurs per part d’un usuari provoqui la fallada del sistema per a tots els usuaris.
En alguns casos, és possible que el problema no sigui un mal ús de la xarxa ni un abús per part de l’usuari, sinó que el protocol mateix permeti comportaments no desitjats. Un exemple molt clar és el protocol SMTP i el problema del correu no desitjat. L’entrega d’un correu electrònic es basa en els dominis que té el servidor destinació i no hi ha manera de comprovar l’autenticitat de l’emissor. Per l’arquitectura del correu electrònic, un servidor qualsevol no es pot saber a priori si és un intermediari legítim o un servidor que envia correu no desitjat.
El problema se sol mitigar mitjançant llistes de servidors coneguts que envien correu no desitjat i un sistema de puntuacions heurístiques.
5) Annexos. Finalment, en els annexos es fan constar totes les dades que es creguin rellevants per entendre l’informe, com parts dels registres o ordres que s’han executat que puguin ser útils de cara a una anàlisi posterior.
Sol ser útil incloure-hi el registre complet de la sessió, perquè la resta de personal implicat en la resolució de la incidència la pugui veure.
Un guió (script en anglès) és una eina present en la majoria de distribucions Linux que permet enregistrar una sessió de consola.