

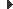
Sistemes de bases de dades i comunicacions
L’arquitectura d’un sistema de bases de dades està influenciada en gran mesura pel sistema informàtic subjacent en què s’executa, en particular per aspectes de l’arquitectura de l’ordinador com la connexió en xarxa, el paral·lelisme i la distribució:
- La connexió en xarxa de diverses computadores permet que algunes d’aquestes s’executin en un sistema servidor i que altres s’executin en els sistemes clients. Aquesta divisió de treball ha conduït al desenvolupament de sistemes de bases de dades client-servidor.
- El processament paral·lel dins d’un ordinador permet accelerar les activitats del sistema de base de dades, i proporciona a les transaccions unes respostes més ràpides i la capacitat d’executar més transaccions per segon. Les consultes es poden processar de manera que s’exploti el paral·lelisme ofert pel sistema informàtic subjacent. La necessitat del processament paral·lel de consultes ha conduït al desenvolupament dels sistemes de bases de dades paral·lels.
- La distribució de dades a través de les diferents seus o departaments d’una organització permet que aquestes dades es trobin on han estat generades o on són més necessàries, però continuen essent accessibles des d’altres llocs o departaments diferents. El fet de desar diverses còpies de la base de dades en diferents llocs permet que puguin continuar les operacions sobre la base de dades encara que algun lloc es vegi afectat per algun desastre natural com una inundació, un incendi o un terratrèmol. S’han desenvolupat els sistemes distribuïts de bases de dades per manejar dades distribuïdes geogràficament o administrativament al llarg de múltiples sistemes de bases de dades.
Estudiarem, doncs, l’arquitectura dels sistemes de bases de dades començant amb els tradicionals sistemes centralitzats i tractant, més endavant, els sistemes de bases de dades client-servidor, paral·lels i distribuïts.
Els sistemes de bases de dades centralitzats són aquells que s’executen en un únic sistema informàtic sense interaccionar amb cap altre ordinador. Aquests sistemes comprenen el rang des dels sistemes de bases de dades monousuari que s’executen en ordinadors personals fins als sistemes de bases de dades d’alt rendiment que s’executen en grans sistemes.
D’altra banda, els sistemes client-servidor tenen la seva funcionalitat dividida entre el sistema servidor i múltiples sistemes clients.
Sistemes centralitzats
Un ordinador modern de propòsit general consisteix en una o poques unitats centrals de processament i un nombre determinat de controladors per als dispositius que es troben connectats per mitjà d’un bus comú, el qual proporciona accés a la memòria compartida. Les CPU (unitats centrals de processament) tenen memòries cau locals on s’emmagatzemen còpies de certes parts de la memòria per accelerar l’accés a les dades. Cada controlador s’encarrega d’un tipus específic de dispositius (per exemple, una unitat de disc, una targeta de so o un monitor). Les CPU i els controladors de dispositius es poden executar concurrentment i competeixen així per l’accés a la memòria. La memòria cau redueix la disputa per l’accés a la memòria, ja que la CPU necessita accedir a la memòria compartida un nombre de vegades menor (figura).
Es distingeixen dues maneres d’utilitzar les computadores: com a sistemes monousuari o multiusuari.
En la primera classe tindrem els ordinadors personals i les estacions de treball. Un sistema monousuari típic és una unitat de sobretaula utilitzada per una única persona que disposa d’una sola CPU, d’un o dos discos fixos i que treballa amb un sistema operatiu que només permet un únic usuari.
En canvi, un sistema multiusuari típic té més discos i més memòria, pot disposar de diverses CPU i treballa amb un sistema operatiu multiusuari. S’encarrega de donar servei a un gran nombre d’usuaris que estan connectats al sistema per mitjà de terminals.
Normalment, els sistemes de bases de dades dissenyats per funcionar sobre sistemes monousuari no solen proporcionar moltes de les facilitats que ofereixen els sistemes multiusuari. En particular, no tenen control de concurrència, que no és necessari quan només un usuari pot generar modificacions.
Les facilitats de recuperació en aquests sistemes o no existeixen o són primitives; per exemple, fer una còpia de seguretat de la base de dades abans de qualsevol modificació.
La majoria d’aquests sistemes no admeten SQL i proporcionen un llenguatge de consulta molt simple que, en alguns casos, és una variant de QBE. En canvi, els sistemes de bases de dades dissenyats per a sistemes multiusuari suporten totes les característiques de les transaccions que s’han estudiat abans.
Encara que avui dia els ordinadors de propòsit general tenen diversos processadors, utilitzen paral·lelisme de gra gruixut, i disposen d’uns pocs processadors (normalment dos o quatre) que comparteixen la mateixa memòria principal. Les bases de dades que s’executen en aquestes màquines habitualment no intenten dividir una consulta simple entre els diferents processadors, sinó que executen cada consulta en un únic processador i així es possibilita la concurrència de diverses consultes. Així, aquests sistemes suporten més productivitat, és a dir, permeten executar més transaccions per segon, tot i que cada transacció individualment no s’executi més ràpid.
Les bases de dades dissenyades per a les màquines monoprocessador ja disposen de multitasca i això permet que diversos processos s’executin al mateix temps en el mateix processador, usant temps compartit, mentre que amb vista a l’usuari sembla que els processos s’estan executant en paral·lel. D’aquesta manera, des d’un punt de vista lògic, les màquines paral·leles de gra gruixut semblen idèntiques a les màquines monoprocessador, i poden adaptar fàcilment els sistemes de bases de dades dissenyats per a màquines de temps compartit per tal que es puguin executar sobre màquines paral·leles de gra gruixut.
Per contra, les màquines paral·leles de gra fi tenen un gran nombre de processadors i els sistemes de bases de dades que s’executen sobre aquestes intenten fer paral·leles les tasques simples (consultes, per exemple) que demanen els usuaris.
Bases de dades client/servidor
Com les computadores personals són ara més ràpides, més potents i més barates, els sistemes s’han anat distanciant de l’arquitectura centralitzada.
Els terminals connectats a un sistema central han estat suplantats per ordinadors personals. De la mateixa manera, la interfície d’usuari, que solia estar gestionada directament pel sistema central, està passant a ser gestionada, cada vegada més, per les computadores personals.
Com a conseqüència, els sistemes centralitzats actuen avui com a sistemes de servidor que satisfan les peticions generades pels sistemes clients.
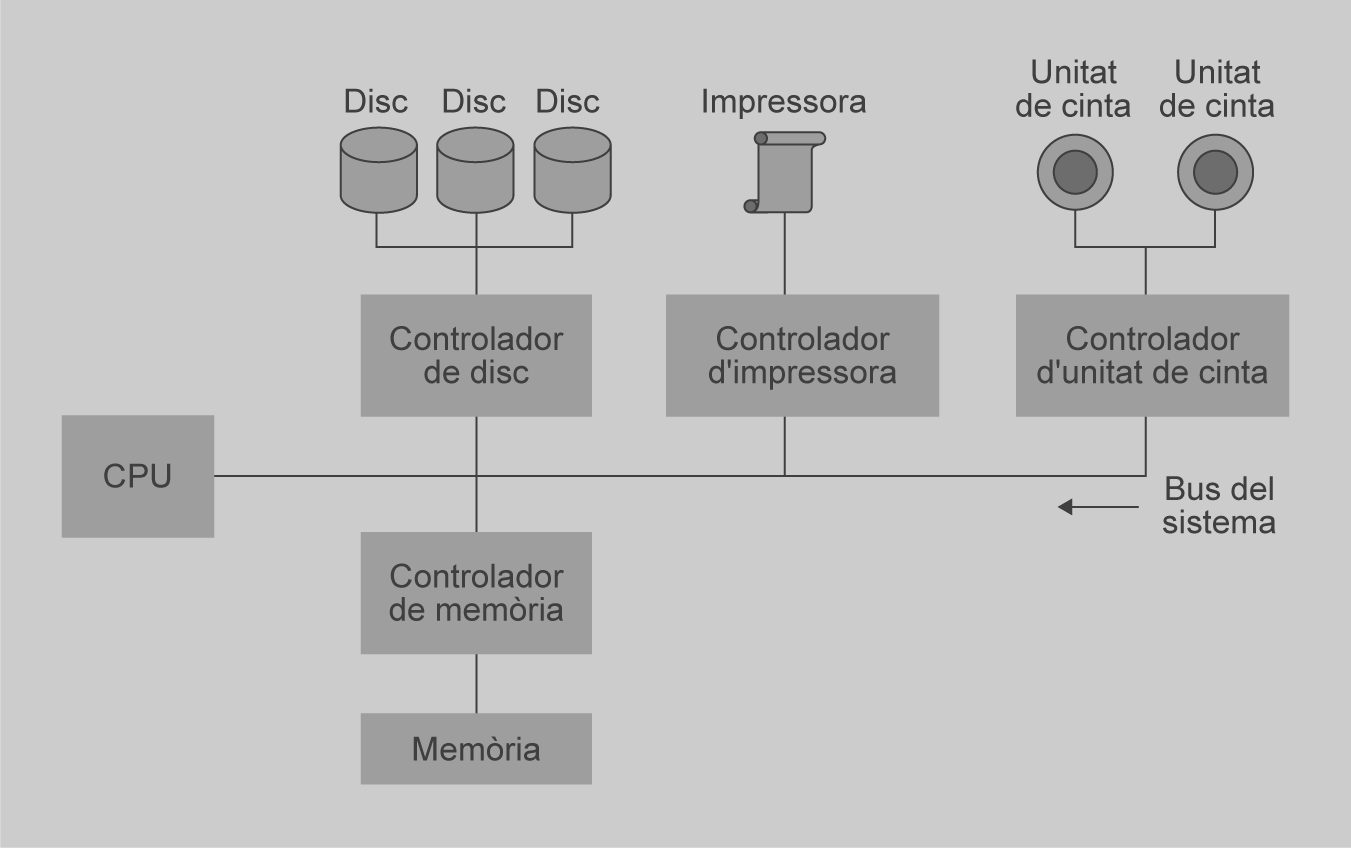
Aquest model es basa en la distribució de funcions entre dos tipus de processos independents i autònoms, servidors i clients.
Un client és un procés que sol·licita serveis específics als processos d’un servidor. Un servidor és un procés que proporciona serveis sol·licitats pels clients.
Els processos client i servidor poden estar al mateix ordinador o en diferents, sempre que estiguin connectats per una xarxa.
Segons el grau en què es comparteix el processament entre el client i el servidor, un servidor o un client es pot catalogar com a pesat o lleuger. Un client lleuger és el que fa un mínim de processament pel costat client, mentre que un client pesat és el que suporta una proporció relativament gran de càrrega de processament. De la mateixa manera, un servidor pesat fa la part preponderant de càrrega de processament, mentre que un servidor lleuger s’encarrega de menys càrrega de processament.
Finalment, val a dir que els sistemes client/servidor també es classifiquen com de 2 o 3 capes.
Sistema client/servidor de 2 capes
En un sistema client/servidor de 2 capes un client sol·licita serveis directament al servidor. A la figura es representa l’estructura general d’un sistema client-servidor.
En el cas del PostgreSQL, es pot accedir a les nostres bases de dades via sòcols.
Un sòcol és un concepte abstracte pel qual dos programes (possiblement situats en ordinadors diferents) poden intercanviar qualsevol flux de dades, generalment de manera fiable i ordenada. Tot sòcol està definit per una adreça de sòcol. L’adreça de sòcol és una combinació de tres elements: una adreça IP, un protocol de transport i un número de port (per exemple: 84.88.125.15, TCP, 5432).
Perquè dos programes es puguin comunicar entre si és necessari que es compleixin certs requisits:
- Que un programa sigui capaç de localitzar l’altre.
- Que tots dos programes siguin capaços d’intercanviar qualsevol seqüència de bytes, és a dir, dades rellevants a la seva finalitat.
Per a això són necessaris els tres recursos que originen el concepte de sòcol:
- Un protocol de comunicacions, que permet l’intercanvi de bytes.
- Una adreça del protocol de xarxa (adreça IP, si s’utilitza el protocol TCP/IP), que identifica un ordinador.
- Un número de port, que identifica un programa dins d’un ordinador.
Els sòcols permeten implementar una arquitectura client-servidor. La comunicació ha de ser iniciada per un dels programes, que s’anomena programa client. El segon programa espera que un altre iniciï la comunicació, i per aquest motiu s’anomena programa servidor.
Un sòcol és un fitxer informàtic existent a la màquina client i a la màquina servidora, que serveix en última instància perquè el programa servidor i el client llegeixin i escriguin la informació. Aquesta informació serà la transmesa per les diferents capes de xarxa.
En el cas del PostgreSQL inicialment el servidor queda configurat amb sòcols Unix. Podem comprovar que està funcionant el servidor (postmaster) des de l’intèrpret d’ordres amb:
# pgrep post
Per utilitzar el protocol TCP/IP per a connexions des de diferents màquines cal editar els fitxers pg_hba.conf i postgresql.conf.
En la secció “Annexos” del web del mòdul podeu veure com es fa la configuració del PostgreSQL mitjançant els arxius pg_hba.conf i postgresql.conf.
Sistema client/servidor de 3 capes
En un sistema client/servidor de 3 capes, les sol·licituds del client són manejades per servidors intermedis, i són aquests els que s’encarreguen de coordinar l’execució de les sol·licituds del client amb altres servidors subordinats.
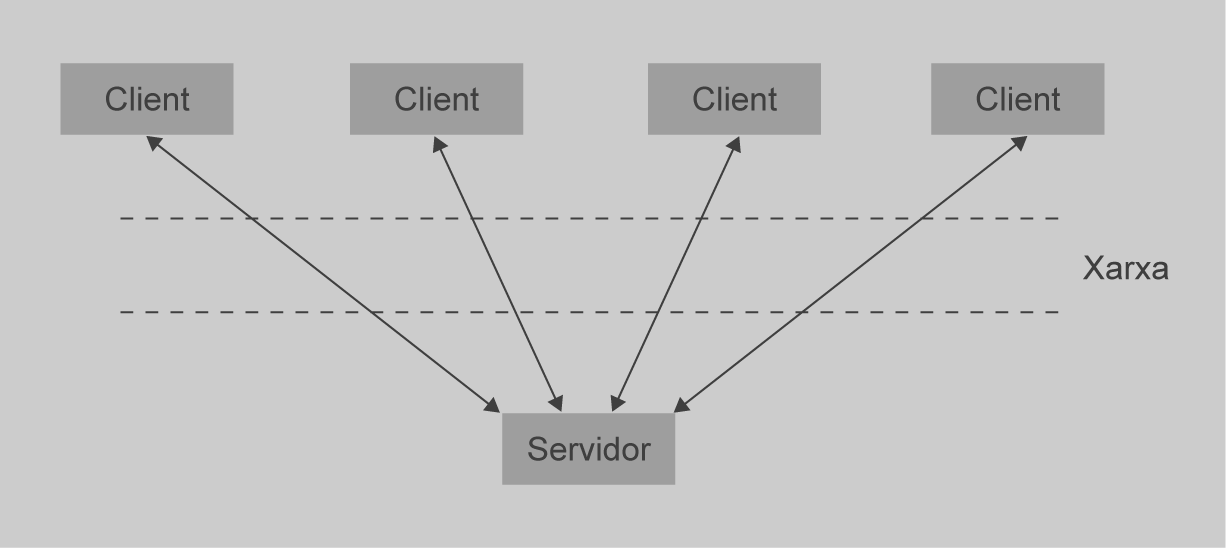
Com es mostra en la figura, la funcionalitat d’una base de dades es pot dividir a grans trets en tres parts: la part visible a l’usuari i el sistema subjacent s’interconnecten per una capa intermèdia.
El sistema subjacent gestiona l’accés a les estructures, l’avaluació i optimització de consultes, el control de concurrència i la recuperació. La part visible a l’usuari d’un sistema de base de dades està formada per eines com formularis, dissenyadors d’informes i facilitats gràfiques d’interfície d’usuari. La interfície entre la part visible a l’usuari i el sistema subjacent pot ser SQL o una aplicació.
Les normes com ODBC i JDBC es van desenvolupar per fer d’interfície entre clients i servidors. Qualsevol client que utilitzi interfícies ODBC o JDBC es pot connectar a qualsevol servidor que proporcioni aquesta interfície.
En les primeres generacions de sistemes de bases de dades, la manca d’aquestes normes feia que fos necessari que la interfície visible i el sistema subjacent fossin proporcionats pel mateix distribuïdor de programari. Amb l’augment de les interfícies estàndard, sovint diferents distribuïdors proporcionen la interfície visible a l’usuari i el servidor del sistema subjacent. Les eines de desenvolupament d’aplicacions s’utilitzen per construir interfícies d’usuari; proporcionen eines gràfiques que es poden utilitzar per construir interfícies sense programar.
Eines de desenvolupament d'aplicacions
Algunes de les eines de desenvolupament d’aplicacions més famoses són PowerBuilder, Magic i Borland Delphi. El Visual Basic també s’utilitza bastant en el desenvolupament d’aplicacions.
Interfícies client-servidor
Certes aplicacions com els fulls de càlcul i els paquets d’anàlisi estadística disposen d’una interfície client-servidor per accedir a les dades del servidor subjacent. De fet, proporcionen interfícies visibles especials per a diferents tasques.
Alguns sistemes de processament de transaccions proporcionen una interfície de crida a procediments remots per a transaccions per connectar els clients amb el servidor. Aquestes trucades apareixen per al programador com a crides normals a procediments, però totes les crides a procediments remots fetes des d’un client s’engloben en una única transacció al servidor final. D’aquesta manera, si la transacció es cancel·la, el servidor pot desfer els efectes de les crides a procediments remots de manera individual.
Arquitectura client/servidor
Una arquitectura client/servidor es basa en components de programari i maquinari que interactuen per formar un sistema.
Components d'una arquitectura client/servidor
Aquest sistema inclou 3 components principals: clients, servidors i programari intermediari de comunicacions.
- El client és qualsevol ordinador que sol·licita serveis al servidor. També es coneix com a aplicació frontal.
- El servidor és qualsevol procés de computadora que proporciona serveis als clients. També es coneix com a aplicació dorsal.
- El programari intermediari de comunicacions és qualsevol procés o conjunt d’aquests mitjançant els quals el procés client i el procés servidor es comuniquen. També és conegut com a middleware o estrat de comunicacions i es compon de diversos estrats de programari que ajuden a transmetre dades i a controlar la informació entre clients i servidors. El programari intermediari de comunicacions en general s’associa a una xarxa. Totes les sol·licituds del client i les respostes del servidor viatgen a través de la xarxa en forma de missatges que contenen dades i informació de control.
Principis client/servidor
Els components de l’arquitectura client/servidor cal que s’ajustin a alguns principis bàsics per assolir una interacció adequada. Aquest principis cal que siguin aplicables tant a clients, servidors i components de programari intermediari.
- Independència de maquinari: aquest principi requereix que tant els processos client, servidor i intermediari funcionin en diferents plataformes de maquinari sense cap diferència de funcionament.
- Independència de programari: requereix que els processos client, servidor i intermediari suportin diferents sistemes operatius, diversos protocols (IPX i TCP/IP) i diferents aplicacions.
- Accés obert a serveis: cal que tots els clients en el sistema tinguin accés obert a tots els serveis proveïts a la xarxa i que aquests serveis no depenguin de la ubicació del client o del servidor.
- Distribució de processos: els processos client i servidor cal que siguin entitats autònomes amb límits i funcions clarament definides. Això permet delimitar la funcionalitat per cada costat i millorar la modularitat i flexibilitat. Cal assolir el màxim d’utilització dels recursos, i per això el procés servidor cal que sigui compartit per tots els clients, és a dir, podrà atendre diferents sol·licituds de diferents clients. Cal que els processos client i servidor siguin fàcils d’actualitzar. Cal que el procés servidor i els clients s’integrin fàcilment per formar un sistema.
- Estàndards: tots aquests principis exposats s’han d’implementar seguint diferents estàndards, ja que així assolim que els diferents components interactuïn de manera ordenada per assolir els resultats que volem.
Protocol RDA (remote database access)
RDA és un protocol de comunicacions per a l’accés a remot a bases de dades que ha estat adoptat com un estàndard internacional per l’Organització Internacional de Normalització (ISO) i la Comissió Electrotècnica Internacional (IEC). També s’ha adoptat com a norma ANSI.
Proporciona protocols estàndard per establir una connexió remota entre un client i un servidor de base de dades. El client està actuant com un programa d’aplicació mentre el servidor fa d’interfície d’un procés que controla les transferències de dades cap a una base de dades i des d’aquesta.
L’objectiu és promoure la interconnexió de les aplicacions de bases de dades entre entorns heterogenis.
RDA va ser publicat com una combinació d’ANSI/ISO/IEC el 1993. Es compon de dues parts:
- Part 1 — RDA genèric ANSI/ISO/IEC 9579-1:1993
- Part 2 — Especialització SQL ANSI/ISO/IEC 9579-2:1993
La part 1 especifica el model general, el servei i el protocol per a una connexió a la base de dades i la part 2 especifica els protocols addicionals per a la connexió de bases de dades d’acord amb el llenguatge SQL.
Com a característiques generals podem dir que:
- L’aplicació interactua amb la base de dades mitjançant sentències SQL.
- Les seves sentències poden recuperar, actualitzar, eliminar o inserir registres.
- Les declaracions es poden agrupar en les transaccions, de manera que una transacció té èxit o fracassa en el seu conjunt.
- La ubicació de la base de dades és transparent.
Components del client
Com hem esmentat, un client correspon a qualsevol procés que sol·licita serveis a un procés servidor. El client és proactiu, és a dir, sempre iniciarà la conversa amb el servidor. Les característiques desitjables tant de programari com de maquinari que cal que tingui un client són:
- Maquinari poderós
- Sistema operatiu multitasca
- Interfície gràfica d’usuari (GUI)
- Capacitats de comunicació
Una aplicació client funciona sobre un sistema operatiu i es connecta al programari intermediari de comunicacions per accedir als serveis disponibles de la xarxa.
Es poden emprar tant llenguatges de 3a. generació com de 4a. generació (4GL) per crear l’aplicació frontal amb la qual interactuarà l’usuari.
La majoria de les aplicacions frontals estan basades en GUI per ocultar a l’usuari la complexitat dels components client/servidor.
Així aquest poder de processament permetrà el desenvolupament d’aplicacions amb capacitats multimèdia.
Sistemes de servidor
Els sistemes de servidor es poden dividir en servidors de transaccions i servidors de dades.
- Els sistemes de servidor de transaccions, també anomenats sistemes de servidor de consultes, proporcionen una interfície per mitjà de la qual els clients poden enviar peticions per fer una acció que el servidor executarà, i els resultats es tornaran al client. Normalment, les màquines client envien les transaccions als sistemes de servidor, lloc en què aquestes transaccions s’executen, i els resultats es retornen als clients, que són els encarregats de visualitzar les dades. Les peticions es poden especificar utilitzant SQL o mitjançant la interfície d’una aplicació especialitzada.
- Els sistemes de servidor de dades permeten als clients interaccionar amb els servidors fent peticions de lectura o modificació de dades en unitats com ara arxius o pàgines. Per exemple, els servidors de fitxers proporcionen una interfície de sistema d’arxius per mitjà de la qual els clients poden crear, modificar, llegir i esborrar fitxers. Els servidors de dades dels sistemes de bases de dades ofereixen moltes més funcionalitats, suporten unitats de dades de mida menor que els arxius, com pàgines, tuples o objectes. Proporcionen facilitats d’indexació de les dades, i també facilitats de transacció, de manera que les dades mai no es queden en un estat inconsistent si falla una màquina client o un procés.
D’aquestes, l’arquitectura del servidor de transaccions és, amb molt, l’arquitectura més àmpliament utilitzada.
Podeu veure l’arquitectura del PostgreSQL en la secció “Annexos” del web del mòdul.
Estructura de processos del servidor de transaccions
Avui dia, un sistema servidor de transaccions típic consisteix en múltiples processos que accedeixen a les dades en una memòria compartida, com mostra la figura.
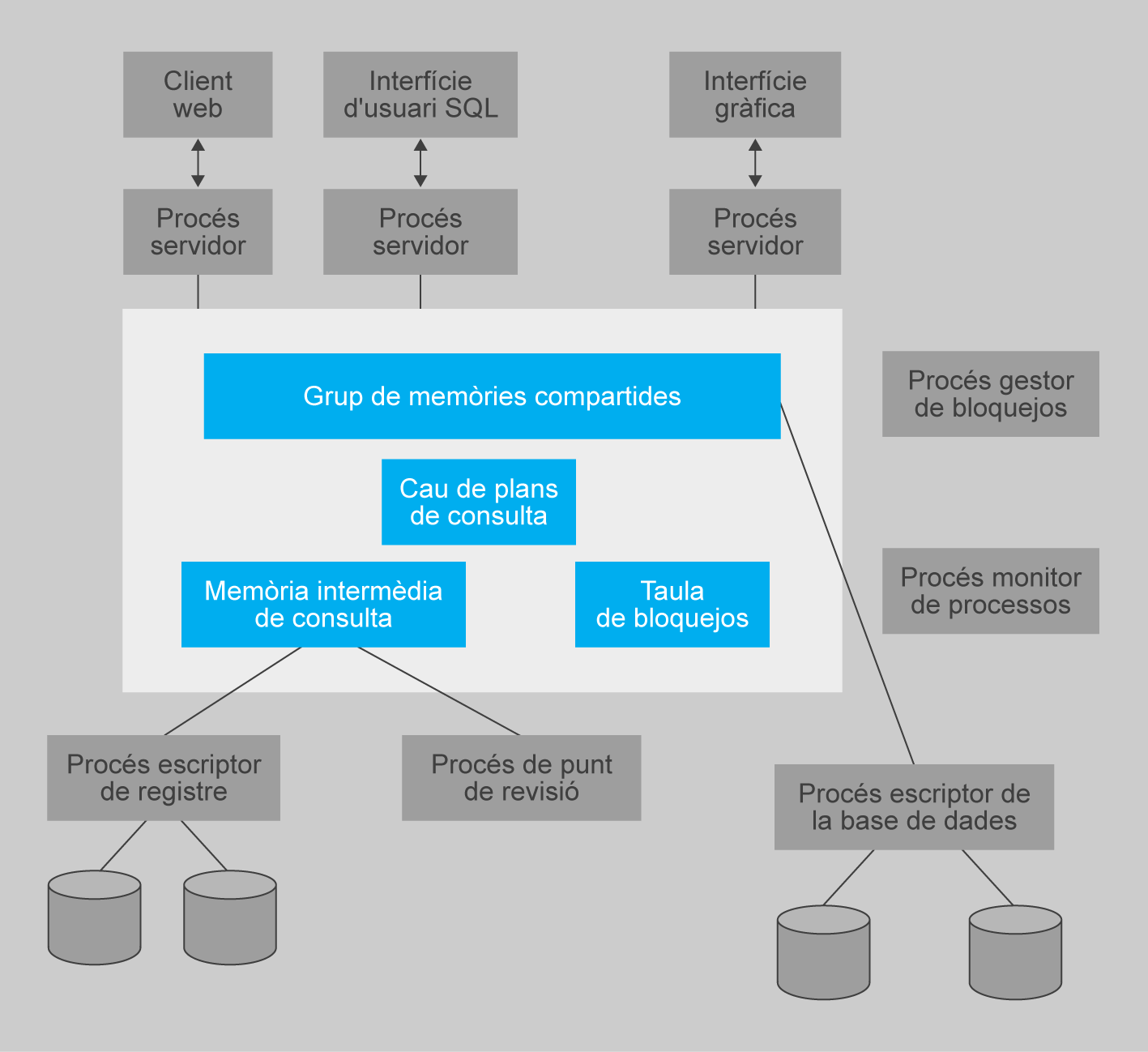
Els processos que formen part del sistema de bases de dades inclouen:
- Processos servidor: són processos que reben consultes de l’usuari (transaccions), les executen, i retornen els resultats. Les consultes s’han d’enviar als processos servidor des de la interfície d’usuari, o des d’un procés d’usuari que executa SQL incorporat, o mitjançant JDBC, ODBC o protocols similars. Alguns sistemes de bases de dades utilitzen un procés diferent per a cada sessió d’usuari, i algunes utilitzen un únic procés de la base de dades per a totes les sessions de l’usuari, però amb múltiples fils, de manera que es poden executar concurrentment múltiples consultes. (Un fil és com un procés, però diversos fils s’executen com a part del mateix procés, i tots els fils dins d’un procés s’executen en el mateix espai de memòria virtual. Dins d’un procés es poden executar concurrentment múltiples fils.) Alguns sistemes de bases de dades utilitzen una arquitectura híbrida, amb processos múltiples, cadascun amb diverses cadenes.
- Procés gestor de bloquejos: aquest procés implementa una funció de gestió de bloquejos que inclou concessió de bloquejos, alliberament de bloquejos i detecció d’interbloquejos.
- Procés escriptor de bases de dades: hi ha un o més processos que bolquen al disc els blocs de memòria intermèdia modificats de manera contínua.
- Procés escriptor del registre: aquest procés genera entrades del registre en l’emmagatzematge estable a partir de la memòria intermèdia del registre. Els processos servidor simplifiquen l’addició d’entrades a la memòria intermèdia del registre en memòria compartida i, si cal forçar l’escriptura del registre, demanen al procés escriptor del registre que bolqui les entrades del registre.
- Procés punt de revisió: aquest procés fa periòdicament punts de revisió.
- Procés monitor de procés: aquest procés observa altres processos i, si qualsevol falla, fa accions de recuperació per al procés, com ara cancel·lar qualsevol transacció que estigués executant el procés fallit, i reinicia el procés.
La memòria compartida conté totes les dades compartides, com:
- Grup de memòries intermèdies.
- Taula de bloquejos.
- Memòria intermèdia del registre, que conté les entrades del registre que esperen a ser abocades en l’emmagatzematge estable.
- Plans de consulta en memòria cau, que es poden reutilitzar si s’envia de nou la mateixa consulta.
Tots els processos de la base de dades poden accedir a les dades de la memòria compartida. Ja que múltiples processos poden llegir o fer actualitzacions en les estructures de dades en memòria compartida, hi ha d’haver un mecanisme que asseguri que només un està modificant una estructura de dades en un moment donat, i que cap procés no està llegint una estructura de dades mentre altres l’escriuen. Tal exclusió mútua es pot implementar per mitjà de funcions del sistema operatiu anomenades semàfors.
Implementacions alternatives, amb menys sobrecàrregues, utilitzen instruccions atòmiques especials suportades pel maquinari de l’ordinador, un tipus d’instrucció atòmica comprova una posició de la memòria i l’estableix a un automàticament. Es poden trobar més detalls sobre l’exclusió mútua en qualsevol llibre de text d’un sistema operatiu estàndard. Els mecanismes d’exclusió mútua també s’utilitzen per implementar sòcols.
Per evitar la sobrecàrrega del pas de missatges, en molts sistemes de bases de dades els processos servidor implementen el bloqueig actualitzant directament la taula de bloquejos (que està en memòria compartida), en lloc d’enviar missatges de sol·licitud de bloqueig a un procés administrador de bloquejos. El procediment de sol·licitud de bloquejos executa les accions que faria el procés administrador de bloquejos per processar la petició de bloqueig. Les accions de la sol·licitud i l’alliberament de bloquejos són les habituals, però amb dues diferències significatives:
- Atès que diversos processos servidor poden accedir a la memòria compartida, s’ha d’assegurar l’exclusió mútua en la taula de bloquejos.
- Si no es pot obtenir un bloqueig immediatament a causa d’un conflicte de bloquejos, el codi de la sol·licitud de bloqueig continua observant la taula de bloquejos fins a adonar-se que s’ha concedit el bloqueig. El codi d’alliberament de bloqueig actualitza la taula de bloquejos per indicar a quin procés s’ha concedit el bloqueig.
Per evitar comprovacions repetides de la taula de bloquejos, el codi de sol·licitud de bloqueig pot utilitzar els semàfors del sistema operatiu per esperar una notificació d’una concessió de bloqueig. El codi d’alliberament de bloqueig ha d’utilitzar llavors el mecanisme de semàfors per notificar a les transaccions que estan esperant que els seus bloquejos hagin estat concedits.
Fins i tot si el sistema gestiona les sol·licituds de bloqueig per mitjà de memòria compartida, encara utilitza el procés administrador de bloquejos per a la detecció d’interbloquejos.
Servidors de dades
Els sistemes de servidor de dades s’utilitzen en xarxes d’àrea local en què s’assoleix una alta velocitat de connexió entre els clients i el servidor, les màquines clients són comparables al servidor quant a poder de processament i s’executen tasques de còmput intensiu.
En aquest entorn té sentit enviar les dades a les màquines client, fer allà tot el processament (que pot durar un temps) i després enviar les dades de tornada al servidor. Noteu que aquesta arquitectura necessita que els clients tinguin totes les funcionalitats del sistema subjacent.
Les arquitectures dels servidors de dades s’han fet particularment populars en els sistemes de bases de dades orientades a objectes.
En aquesta arquitectura sorgeixen alguns aspectes interessants, ja que el cost en temps de comunicació entre el client i el servidor és alt comparat amb el d’accés a una memòria local (mil·lisegons enfront de menys de 100 nanosegons):
- Enviament de pàgines o enviament d’elements. La unitat de comunicació de dades pot ser de gra gruixut, com una pàgina, o de gra fi, com un tuple (o, en el context dels sistemes de bases de dades orientades a objectes, un objecte). S’usarà el terme element per referir-se tant a tuples com a objectes. Si la unitat de comunicació de dades és un únic element, la sobrecàrrega per la transferència de missatges és alta comparada amb el nombre de dades transmeses. En comptes de fer això, quan es necessita un element, pren sentit la idea d’enviar al costat d’aquell altres elements que probablement hagin de ser utilitzats en un futur pròxim. Es denomina preextracció l’acció de cercar i enviar elements abans que sigui estrictament necessari. Si diversos elements es troben en una pàgina, l’enviament de pàgines es pot considerar com una forma de preextracció, ja que, quan un procés vulgui accedir a un únic element de la pàgina, s’enviaran tots els elements d’aquesta pàgina.
- Bloqueig. La concessió del bloqueig dels elements de dades que el servidor envia als clients la fa habitualment el servidor mateix. Un inconvenient de l’enviament de pàgines és que els clients poden rebre bloquejos de gra gruixut: el bloqueig d’una pàgina bloqueja implícitament tots els elements que s’hi troben. El client adquireix implícitament bloquejos sobre tots els elements preextrets, fins i tot encara que no estigui accedint a alguns d’aquests. D’aquesta manera, pot aturar innecessàriament el processament d’altres clients que necessiten bloquejar aquests elements. S’han proposat algunes tècniques per a l’alliberament de bloquejos en què el servidor pot demanar als clients que li tornin el control sobre els bloquejos dels elements preextrets. Si el client no necessita l’element preextret pot retornar els bloquejos sobre aquest element al servidor perquè aquests puguin ser assignats a altres clients.
- Memòria cau de dades. Les dades que s’envien al client en favor d’una transacció es poden allotjar en una memòria cau del client fins i tot una vegada completada la transacció, si disposa de prou espai d’emmagatzematge lliure. Les transaccions successives en el mateix client poden fer ús de les dades en memòria cau. No obstant això, es presenta el problema de la coherència de cau: si una transacció troba les dades en la memòria cau, s’ha d’assegurar que aquestes dades estan al dia, ja que, després d’haver estat emmagatzemades en la memòria cau, poden haver estat modificades per un altre client. Així, s’ha d’establir una comunicació amb el servidor per comprovar la validesa de les dades i poder adquirir un bloqueig sobre aquestes.
- Memòria cau de bloquejos. Els bloquejos també poden ser emmagatzemats en la memòria cau del client si la utilització de les dades està pràcticament dividida entre els clients, de manera que un client poques vegades necessita dades que estan essent utilitzats per altres clients.
Exemple de cost en la comunicació
Suposem que es troben a la memòria cau tant l’element de dades que es busca com el bloqueig requerit per accedir-hi. Llavors, el client pot accedir a l’element de dades sense necessitat de comunicar res al servidor. No obstant això, el servidor ha de seguir el rastre dels bloquejos en memòria cau; si un client demana un bloqueig al servidor, aquest ha de comunicar a tots els bloquejos sobre l’element de dades que es troba en les memòries cau d’altres clients. La tasca es torna més complicada quan es tenen en compte els possibles errors de la màquina. Aquesta tècnica es diferencia de l’alliberament de bloquejos, en què la memòria cau de bloqueig es fa per mitjà de transaccions; d’una altra manera, les dues tècniques serien similars.
Programari intermediari de comunicacions
El programari intermediari proporciona les funcions següents:
- Homogeneïtzar els diferents components del maquinari, sistemes operatius i protocols de comunicació.
- En sistemes distribuïts, ocultar el fet que normalment una aplicació està formada per diferents parts interconnectades que s’executen en diferents localitzacions.
- Proporcionar interfícies uniformes d’alt nivell per als desenvolupadors i integradors d’aplicacions, i facilitar la composició, reutilització, portabilitat i interoperabilitat d’aquestes aplicacions.
- Proveir un sistema de serveis comuns per fer diverses funcions de finalitats generals, per tal d’evitar la duplicació d’esforços i facilitar la col·laboració entre les aplicacions.
Components del programari intermediari
Així doncs, el programari intermediari de base de dades consta de tres components principals:
- Interfície de programació d’aplicacions (API): la utilització dependrà de l’aplicació client. Aquesta API permet al programador escriure codi SQL genèric.
- Traductor de base de dades: tradueix aquestes sol·licituds fetes en format genèric a una sintaxi específica per a aquell servidor de bases de dades que serà utilitzat, ja que podria tenir algunes característiques no estàndard.
- Traductor de xarxa: que gestionarà els diferents protocols de comunicació de xarxa emprats per la part client i la part servidor.
Classificació del programari intermediari
El programari intermediari es pot classificar d’acord amb la manera com els clients i els servidors es comuniquen a través de la xarxa:
- Programari intermediari orientat a missatges (MOM). És un programari que suporta la infraestructura d’enviament i recepció de missatges entre sistemes distribuïts. MOM permet els mòduls d’aplicació per a la distribució a través de plataformes heterogènies i redueix la complexitat del desenvolupament d’aplicacions que abasten múltiples sistemes operatius i protocols de xarxa. El programari intermediari crea una capa de comunicacions distribuïdes que aïlla el desenvolupador de l’aplicació dels detalls del sistema operatiu i les interfícies de xarxa.
- Programari intermediari basat en crides a procediments remots (basat en RPC). RPC és una tecnologia que permet a un programa fer que una subrutina o procediment s’executi en un altre espai d’adreces (habitualment en un altre ordinador en una xarxa compartida) sense que s’hagin de programar explícitament els detalls d’aquesta interacció remota. Un RPC és instanciat pel client enviant un missatge de petició a un servidor remot conegut per executar el procediment especificat fent servir paràmetres subministrats. La resposta serà retornada al client de manera que continuarà amb el seu procés.
- Programari intermediari basat en objectes. Un exemple notable de programari intermediari orientat a objectes és la common object request broker architecture (CORBA). CORBA és un estàndard, no un producte, i va ser desenvolupat per l’Object Management Group (OMG), que és un consorci de gairebé tots els fabricants de programari importants i alguns grans usuaris. Malgrat la seva procedència, poques vegades es veu en les implementacions. Una de les raons de la manca d’implementació CORBA era la seva complexitat. Però, possiblement, la principal raó que CORBA mai no es vagi implementar a fons va ser el sorgiment de la tecnologia de components.
Iniciatives de programari intermediari
Algunes iniciatives de creació de programari intermediari són les següents:
- Call level interface
- ODBC
- iODBC
- unixODBC
- JDBC
- IDAPI
- OLE DB
Call Level Interface
Call level interface (CLI) és un estàndard de programari definit en la norma ISO/IEC 9075-3:2003. La interfície de nivell de crida defineix la manera com un programa ha d’enviar consultes SQL per al sistema de gestió de bases de dades i com els conjunts de registres retornats han de ser manejats per l’aplicació d’una manera coherent. Desenvolupat en la dècada de 1990, l’API es defineix només per als llenguatges C i COBOL.
Evolució de SAG
L’SQL Access Group (SAG) va ser un grup d’empreses de programari que es va formar el 1989 per definir i promoure normes per a la portabilitat i la interoperabilitat de bases de dades. Els membres inicials van ser Oracle Corporation, Informix, Ingres, DEC, Tandem, Sun i HP.
El SAG va iniciar el desenvolupament de l’SQL call level interface (SQL CLI), que més tard es va publicar com una especificació X/Open.
L’SQL Access Group va transferir les seves activitats i actius a X/Open al final de 1994.
ODBC
L’ús més estès de l’estàndard CLI és la base de l’ODBC (open database connectivity), la qual és àmpliament utilitzada per permetre que les aplicacions puguin accedir de manera transparent als sistemes de base de dades de diferents proveïdors.
Microsoft, en col·laboració amb Simba Technologies, va crear ODBC per adaptar-lo a les especificacions SQL CLI. ODBC aconsegueix la independència de la plataforma i el llenguatge mitjançant l’ús d’un controlador ODBC, com una capa de traducció entre l’aplicació i l’SGBD. L’aplicació, per tant, només necessita conèixer la sintaxi d’ODBC, i el controlador pot passar la consulta a l’SGBD en el seu format natiu i tornar les dades en un format que l’aplicació pugui comprendre.
A causa de les diferencies entre les tecnologies d’emmagatzematge de dades, tots els controladors ODBC no poden implementar totes les interfícies possibles disponibles en l’estàndard ODBC. Microsoft descriu la disponibilitat d’una interfície com a “específica del controlador”, ja que poden no ser aplicables en funció de la tecnologia d’emmagatzematge de dades.
Implementació d'ODBC en diferents sistemes operatius
Actualment diferents implementacions d’ODBC funcionen sobre diferents sistemes operatius, incloent-hi Microsoft Windows, Unix, Linux, OS/2, OS/400, IBM i5/OS, i Mac OS X. Hi ha gran quantitat de controladors ODBC per a diferents SGBD com Oracle, DB2, Microsoft SQL Server, Sybase, Pervasive SQL, IBM Lotus Domino, MySQL, PostgreSQL, OpenLink Virtuoso, i bases de dades d’escriptori com FileMaker i Microsoft Access.
iODBC
iODBC és una iniciativa de codi obert gestionada per OpenLink Software. Es tracta d’una plataforma independent SDK d’ODBC i permet el desenvolupament d’aplicacions compatibles amb ODBC i controladors que no siguin de plataforma Windows. Els principals objectius d’aquest projecte són els següents:
- Simplificar la portabilitat de les aplicacions basades en l’ODBC de Windows a altres plataformes.
- Simplificar la portabilitat dels controladors ODBC de Windows a altres plataformes.
- Crear dissenys coherents mitjançant l’experiència en la utilització d’ODBC en totes les plataformes.
unixODBC
unixODBC és un projecte de codi obert que implementa l’API d’ODBC. El codi es distribueix sota llicència GNU GPL/LGPL i pot ser construït i utilitzat en molts sistemes operatius diferents, incloent-hi la majoria de les versions de Unix, Linux, Mac OS X, IBM OS/2 i Interix de Microsoft.
Els objectius del projecte inclouen:
- Proporcionar als desenvolupadors les eines necessàries per portar aplicacions de Microsoft Windows ODBC a altres plataformes amb el mínim de canvis en el codi.
- Mantenir el projecte com un proveïdor SDK neutre d’interfície de base de dades.
- Proporcionar als desenvolupadors de controladors ODBC les eines per portar els seus controladors a les plataformes no-Windows.
- Proporcionar a l’usuari un conjunt d’eines de línia d’ordres i la interfície gràfica d’usuari per administrar l’accés de base de dades.
- Mantenir vincles amb la comunitat de programari lliure i els venedors de bases de dades comercials, per garantir la interoperabilitat.
JDBC
L’API JDBC (Java database connectivity) permet a les aplicacions en llenguatge Java accedir mitjançant una interfície comuna a les bases de dades per a les quals hi hagi JDBC.
Els controladors JDBC es poden classificar en 4 tipus:
- JDBC tipus 1: controladors que actuen com una passarel·la i que permeten l’accés a la base de dades per mitjà d’una altra tecnologia com és l’ODBC.
- JDBC tipus 2: controladors natius. Es tracta d’una barreja de controladors natius al sistema gestor de bases de dades i de programes de control de Java. Les crides JDBC es converteixen en crides natives al sistema gestor de bases de dades.
- JDBC tipus 3: en aquest cas els controladors converteixen les crides JDBC de les aplicacions Java a un protocol independent del sistema gestor de bases de dades. Posteriorment, una aplicació intermediària les converteix al protocol que requereix el sistema gestor, i permet que segueixi el model de 3 capes. Això el diferencia del controlador de tipus 4, ja que la lògica de la conversió de protocols no es troba en el client, sinó en el nivell intermedi. El mateix controlador serveix, doncs, per a diferents SGBD.
- JDBC tipus 4: els controladors converteixen les crides JDBC directament a un protocol que entén el sistema gestor de bases de dades. Com el protocol de base de dades és específic del proveïdor, el client JDBC requereix controladors diferents, que ofereix cada proveïdor de l’SGBD, per connectar-se a diferents tipus de bases de dades. Són els tipus de controladors que ofereixen una comunicació més ràpida i eficient amb el gestor de bases de dades.
IDAPI
IDAPI (integrated database application program interface o independent database application program interface), va ser originalment un component del sistema de bases de dades Paradox de Borland. Més endavant es va convertir en la interfície per a aplicacions del BDE o Borland database engine.
Ús actual de la tecnologia BDE
Actualment no s’utilitza, ja que la tecnologia BDE va ser discontinuada per Borland, si bé Code Gear, companyia filial de Borland dedicada a eines de desenvolupament, encara proveeix documentació per a aquesta.
OLE DB
OLE DB és la sigla d’object linking and embedding for databases (‘enllaç i incrustació d’objectes per a bases de dades’), i és una tecnologia desenvolupada per Microsoft usada per tenir accés a diferents fonts d’informació, o bases de dades, de manera uniforme.
OLE DB permet separar les dades de l’aplicació que les requereix. Això es va fer així, ja que diferents aplicacions requereixen accés a diferents tipus i magatzems de dades, i no necessàriament volen conèixer com poden tenir accés a certa funcionalitat amb mètodes de tecnologies específiques. OLE DB està conceptualment dividit en consumidors i proveïdors: el consumidor és l’aplicació que requereix accés a les dades i el proveïdor és el component de programari que exposa una interfície OLE DB per mitjà de l’ús del component object model (COM).
Microsoft data access components:
OLE DB és part dels components de Microsoft per a accés a dades o Microsoft data access components (MDAC); MDAC és un grup de tecnologies de Microsoft que interactua en conjunt com una infraestructura que brinda als programadors de la nova era una manera de desenvolupar aplicacions amb accés a gairebé qualsevol magatzem de dades. Els proveïdors OLE DB poden ser creats per tenir accés a magatzems de dades, que van des de simples arxius de text i fulls de càlcul fins a bases de dades complexes com Oracle, Microsoft SQL Server o Sybase ASE.