

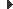
El dialecte SQL de PostgreSQL
PostgreSQL és un sistema de bases de dades relacionals (RDBMS). Això significa que és un sistema de gestió de dades en què aquestes estan emmagatzemades en relacions. Com coneixem, el terme relació és el terme matemàtic que emprem per designar una taula. La idea d’emmagatzemar dades en les taules és molt comuna avui dia i fins i tot pot semblar una cosa òbvia, però com sabem, hi ha altres models.
Cada taula és un conjunt de files. Cada fila d’una taula donada té el mateix conjunt d’atributs, representats sota els noms de cada columna o camp, i cada columna és d’un tipus de dades específic. Mentre que les columnes tenen un ordre fix en cada fila, és important recordar que l’SQL no garanteix l’ordre de les files de la taula, encara que poden ser ordenades de manera explícita per ser visualitzades.
Les taules s’agrupen en diferents esquemes i aquests conformen les bases de dades. Una col·lecció de bases de dades gestionades per una instància de servidor PostgreSQL constitueix un conjunt de bases de dades (clúster).
Tipus de dades
Una taula d’una base de dades relacional és molt similar a una taula en paper: es compon de files i columnes. El nombre i ordre de les columnes és fix, i cada columna té un nom. El nombre de files és variable, ja que reflecteix la quantitat de dades emmagatzemades en un moment donat. Quan una taula es llegeix, les files es mostren sense cap ordre, llevat que es demani expressament un criteri d’ordenació. Això és una conseqüència del model matemàtic subjacent en SQL, el model relacional.
Cada columna té un tipus de dades. El tipus de dades limita el conjunt de valors possibles que es poden assignar a una columna i assigna la semàntica de les dades emmagatzemades a la columna perquè puguin ser utilitzades en diferents càlculs. Per exemple, en una columna declarada com de tipus numèric no s’accepten cadenes de text arbitràries, i les dades emmagatzemades en una columna d’aquest tipus es poden utilitzar per a càlculs matemàtics. D’altra banda, una columna declarada com de tipus cadena de caràcters accepta gairebé qualsevol tipus de dades, però no es presta a càlculs matemàtics, encara que sí a altres operacions, com la concatenació de cadenes de caràcters.
El PostgreSQL inclou un conjunt important de tipus de dades que s’adapten a moltes aplicacions. Els usuaris també poden definir els seus tipus de dades propis. La majoria dels tipus predefinits de dades tenen noms i semàntica bastant òbvia. Alguns dels tipus de dades utilitzats amb freqüència són integer per a nombres enters, numeric per als nombres fraccionaris, text per a cadenes de caràcters, date per a les dates, time per a valors de temps del dia, i timestamp per a valors que contenen la data i l’hora.
Tipus lògics
El PostgreSQL incorpora el tipus lògic boolean, també anomenat bool. Ocupa un byte d’espai d’emmagatzemament i pot emmagatzemar els valors fals i veritable (taula).
| Valor | Nom |
|---|---|
| Fals | false, ‘f’, ‘n’, ‘no’, 0 |
| Vertader | true, ‘t’, ‘y’, ‘yes’, 1 |
El PostgreSQL suporta els operadors lògics següents: and, or i not.
Encara que els operadors de comparació s’apliquen sobre pràcticament tots els tipus de dades proporcionades pel PostgreSQL, atès que el seu resultat és un valor lògic, en descriurem el comportament en la taula.
| Operador | Descripció |
|---|---|
| > | Major que |
| < | Menor que |
| <= | Menor o igual que |
| >= | Major o igual que |
| <> | Diferent de |
| != | Diferent de |
Tipus numèrics
El PostgreSQL disposa dels tipus enters smallint, int i bigint, que es comporten com ho fan els enters en molts llenguatges de programació.
Els nombres amb punt flotant, dels tipus real i double precision, emmagatzemen quantitats amb decimals. Una característica dels nombres de punt flotant és que perden exactitud a mesura que creixen o decreixen els valors.
Espai dels valors de tipus numeric
Sens dubte, aquest avantatge té un cost, i els valors de tipus numeric ocupen un espai d’emmagatzemament considerablement gran i les operacions s’executen sobre aquests molt lentament. Per tant, no és aconsellable utilitzar el tipus numeric si no es necessita una alta precisió o es prioritza la velocitat de processament.
Encara que aquesta pèrdua d’exactitud no sol tenir importància en la majoria de vegades, el PostgreSQL inclou el tipus numeric, que permet emmagatzemar quantitats molt grans o molt petites sense pèrdua d’informació. Vegeu la taula.
| Nom | Mida | Altres noms | Comentari |
|---|---|---|---|
| smallint | 2 bytes | int2 | |
| int | 4 bytes | int4, integer | |
| bigint | 8 bytes | int8 | |
| numeric(p,e) | 11 + (p/2) | ‘p’ és la precisió, ‘e’ és l’escala | |
| real | 4 bytes | float, float4 | |
| double precision | 8 bytes | float8 | |
| serial | No és un tipus, és un enter autoincrementable |
La declaració serial és un cas especial, ja que no es tracta d’un nou tipus. Quan s’utilitza com a nom de tipus d’una columna, aquesta prendrà automàticament valors consecutius en cada registre nou.
CREATE
Si es declaren diverses columnes amb serial en una taula, es crearà una seqüència i un índex per a cada una.
Exemple d’una taula que defineix la columna foli com a tipus serial.
El PostgreSQL respondria aquesta instrucció amb dos missatges:
- En el primer avisa que s’ha creat una seqüència de nom
factura_foli_seq:
- En el segon avisa de la creació d’un índex únic en la taula utilitzant la columna foli:
Operadors numèrics
El PostgreSQL ofereix un conjunt d’operadors numèrics predefinits, que presentem en la taula.
Teniu més informació sobre la gestió de seqüències en la secció “Annexos” del web del mòdul.
| Símbol | Operador |
|---|---|
| + | Addició |
| - | Resta |
| * | Multiplicació |
| / | Divisió |
| % | Mòdul |
| ^ | Exponenciació |
| |/ | Arrel quadrada |
| ||/ | Arrel cúbica |
| ! | Factorial |
| !! | Factorial com a operador fix |
| @ | Valor absolut |
| & | AND binari |
| | | OR binari |
| # | XOR binari |
| ~ | Negació binària |
| << | Corriment binari a l’esquerra |
| >> | Corriment binari a la dreta |
A continuació tenim alguns exemples de l’ús d’aquests operadors:
Tipus de caràcters
Els valors de cadena de PostgreSQL es delimiten per cometes simples.
Es pot incloure una cometa simple dins d’una cadena amb \’ o ’ ‘:
Caràcters especials
Les cadenes poden contenir caràcters especials amb les anomenades seqüències d’escapament, que s’inicien amb el caràcter ‘\’:
| Caràcter | Descripció |
|---|---|
| \n | nova línia |
| \r | retorn |
| \t | tabulador |
| \b | retrocés |
| \f | canvi de pàgina |
| \ | el caràcter \ |
Les cometes dobles delimiten identificadors que contenen caràcters especials.
Les seqüències d’escapament se substitueixen pel caràcter corresponent:
El PostgreSQL ofereix els tipus següents per a cadenes de caràcters (taula):
| Tipus | Altres noms | Descripció |
|---|---|---|
| char(n) | character(n) | Reserva n espais per emmagatzemar la cadena |
| varchar(n) | character varying(n) | Utilitza els espais necessaris per emmagatzemar una cadena més petita o igual que n |
| text | Emmagatzema cadenes de qualsevol magnitud |
Operadors amb cadenes de caràcters
En la taula es descriuen els operadors per a cadenes de caràcters.
| Operador | Descripció | Distingeix majúscules i minúscules? |
|---|---|---|
| || | Concatenació | - |
| ~ | Correspondència amb expressió regular | Sí |
| ~* | Correspondència amb expressió regular | No |
| !~ | No correspondència amb expressió regular | Sí |
| !~* | No correspondència amb expressió regular | - |
Sobre les cadenes també podem utilitzar els operadors de comparació que ja coneixem.
En aquest cas, el resultat de la comparació “més petit que” és fals:
Dates i hores
En la taula es mostren els tipus de dades referents al temps que ofereix el PostgreSQL.
| Tipus de dada | Unitats | Mida | Descripció | Precisió |
|---|---|---|---|---|
| date | dia-mes-any | 4 bytes | Data | Dia |
| time | hrs:min:seg:micro | 4 bytes | Hora | Microsegon |
| timestamp | dia-mes-any | 8 bytes | Data més hora | Microsegon |
Hi ha un tipus de dada timez que inclou les dades del tipus time i, a més, la zona horària.
El tipus de dades date emmagatzema el dia, mes i any d’una data donada i es mostra per omissió amb el format següent: YYYY-MM-DD
Per canviar el format de presentació, hem de modificar la variable d’entorn datestyle:
Matrius
El tipus de dades array és una de les característiques especials de PostgreSQL, i permet l’emmagatzemament de més d’un valor del mateix tipus en la mateixa columna.
La columna parcials accepta tres qualificacions dels estudiants.
Definició
Les matrius no compleixen la primera forma normal de Cood, per la qual cosa molts els consideren inacceptables en el model relacional.
Les matrius, igual que qualsevol columna quan no s’especifica el contrari, accepten valors nuls. Els valors de la matriu s’escriuen sempre entre claus.
També és possible assignar un sol valor de la matriu:
Per seleccionar un valor d’una matriu en una consulta s’especifica entre claudàtors la cel·la que es visualitzarà:
Només en Joan té qualificació en el tercer parcial.
En molts llenguatges de programació, les matrius s’implementen amb longitud fixa; PostgreSQL en permet augmentar la mida dinàmicament.
La columna parcials del registre Pau inclou quatre cel·les i només l’última té valor.
Mitjançant la funció array_dims() podem conèixer les dimensions d’una matriu:
Funcions
Una funció és una agrupació de sentències que s’executa com una unitat. Són molt útils quan cal fer sovint manipulacions automatitzades de taules. Aquestes s’emmagatzemen en la base de dades.
En el PostgreSQL una funció i un procediment emmagatzemat és exactament el mateix. La diferència és més conceptual que concreta.
Les funcions accepten uns valors d’entrada, fan alguna consulta o manipulació sobre aquests, i tornen un valor de sortida.
El PostgreSQL proporciona tres tipus de funcions:
- Funcions de llenguatge de consultes, escrites en SQL: aquestes funcions executen una llista arbitrària de consultes SQL, i tornen els resultats de la darrera consulta de la llista. Poden ser:
- Funcions sobre tipus base: no té arguments i sols retorna un tipus base, com per exemple un int4.
- Funcions sobre tipus compostos: en especificar funcions amb arguments de tipus compostos també cal especificar els atributs d’aquests arguments.
- Funcions de llenguatge procedural, escrites, per exemple en PL/PgSQL.
- Funcions de llenguatge de programació, escrites en un llenguatge de programació compilat, com per exemple en C.
Un exemple d’una funció SQL sobre tipus base pot ser la següent:
Si fem la consulta d’aquesta funció passant dos nombres com a paràmetres, com per exemple el 3 i el 7:
Després veurem detalladament la sintaxi de la creació de les funcions, però ja podem avançar que $n significa l’ordre dels paràmetres, $1 el primer paràmetre, $2 el segon, etc.
Les funcions en PostgreSQL es poden escriure en diferents llenguatges, com per exemple en C, SQL i PL/PgSQL.
Es creen amb CREATE FUNCTION i s’eliminen amb DROP FUNCTION.
El PostgreSQL disposa de diverses funcions predefinides que es poden consultar amb l’ordre \df de psql, des del terminal.
La consulta ens informa de l’esquema a què pertany, el nom de la funció, el tipus de dades de sortida i el tipus de dades dels arguments.
Podeu veure exemples de funcions predefinides en la secció “Annexos” del web del mòdul.
També és pot utilitzar per veure aquesta informació d’una funció especifica, com per exemple per a UPPER. Farem: \df UPPER i ens informa en concret d’aquesta funció:
Provem la funció i veiem que accepta una sèrie de caràcters, els converteix en majúscules i torna la nova sèrie:
Transaccions i bloquejos
Fins ara, hem evitat qualsevol discussió en profunditat sobre els aspectes multiusuari del PostgreSQL, i simplement hem indicat la visió idealitzada que, com qualsevol base de dades relacional amb bones prestacions, el PostgreSQL oculta els detalls de suport a múltiples usuaris concurrents.
El PostgreSQL proporciona un servidor de base de dades ràpid i eficient que ofereix un servei als seus clients com si tots els usuaris simultanis hi tinguessin accés exclusiu. No obstant això, la realitat és que el PostgreSQL, encara que és molt capaç, no pot fer màgia, i l’aïllament de cada usuari de tots els altres requereix un treball de fons.
En aquest apartat, tindrem en compte dos aspectes importants que han de suportar els SGBD per a múltiples usuaris: les transaccions i el bloqueig.
Les transaccions permeten recopilar una sèrie de canvis discrets en la base de dades en una unitat de treball única.
El bloqueig evita conflictes quan diferents usuaris volen fer canvis en la base de dades al mateix temps.
Per tant, tractarem els temes següents:
- Què constitueix una transacció
- Els beneficis de les transaccions en una base de dades d’un sol usuari
- Transaccions amb múltiples usuaris
- Bloqueig de taula i fila.
Concepte de transacció
Com hem esmentat anteriorment, en una situació ideal com la que hem estat suposant fins ara, s’han enregistrat els canvis en la base de dades mitjançant accions declaratives simples.
No obstant això, en aplicacions del món real, aviat arriba un punt en el qual s’han de fer diversos canvis en una base de dades que no es poden expressar en una sola sentència d’SQL.
Tot i que no es fan en una sola declaració, nosaltres necessitem que tots els canvis que es produeixin per actualitzar la base de dades es facin correctament. Si ocorre un problema amb qualsevol part del grup dels canvis, llavors cal que cap dels canvis fets a la base de dades no sigui enregistrat com a definitiu. En altres paraules, cal fer una sola unitat de treball indivisible, en la qual s’executin diverses instruccions SQL per executar-les completament, ja sigui amb totes les declaracions SQL executades amb èxit o sense l’execució de cap d’aquestes.
Exemple d'unitat de treball indivisible en la qual s'executen diverses instruccions
L’exemple clàssic és el procés de transferència de diners entre dos comptes d’un banc, que poden estar representats en les diferents taules d’una base de dades, de manera que a un compte se li carrega una quantitat de diners i en l’altre s’ingressen. Cap banc no pot romandre en el negoci si de tant en tant desapareixen diners en algunes operacions, tan comunes com pot ser una transferència entre comptes (en cas de fer-se la primera operació i fallar la segona).
En bases de dades basades en ANSI SQL, i PostgreSQL ho és, dur a terme aquesta tasca de tot o res s’aconsegueix amb les transaccions.
Una transacció és una unitat lògica de treball que no ha de ser dividida.
Agrupació dels canvis fets en les dades en unitats lògiques
Què s’entén per una unitat lògica de treball?
És simplement un conjunt de canvis lògics de la base de dades, en el qual es produeixen tots els canvis o cap d’aquests, igual que l’exemple anterior de la transferència de diners entre comptes. En PostgreSQL, aquests canvis són controlats per quatre sentències clau:
STARToBEGINinicia una transacció.SAVEPOINTnom_punt_de_salvaguarda demana al servidor que recordi l’estat actual de la transacció. Aquesta declaració només es pot utilitzar després d’unBEGINi abans d’unaCOMMIToROLLBACK, és a dir, mentre que una transacció s’està fent.COMMITdiu que tots els elements de la transacció s’han completat (accions sobre les dades dins de la base de dades), i el nou estat ha de ser persistent i accessible a totes les transaccions simultànies i posteriors.ROLLBACK[TO nom_punt_de_salvaguarda] diu que la transacció hagi de ser abandonada, i que es cancel·lin tots els canvis fets en les dades de transaccions d’SQL. La base de dades ha d’aparèixer en tots els usuaris, com si cap dels canvis s’hagués produït després delBEGINanterior, i la transacció es tanca. En la versió alternativa, amb l’addició de la clàusulaTO, es permet revertir a un punt_de_ salvaguarda, i no es completa una transacció.
Accés multiusuari simultani a les dades
Un segon aspecte de les transaccions és que tota transacció a la base de dades està aïllada d’altres transaccions que tenen lloc en la base de dades al mateix temps. Idealment cada transacció es comporta com si no tingués accés exclusiu a la base de dades. Malauradament, com veurem més endavant quan ens fixem en les transaccions amb múltiples usuaris, la possibilitat real d’aconseguir un bon rendiment significa que cal prendre compromisos amb freqüència.
Vegem un exemple diferent de quan una operació és necessària.
Exemple de reserva d'un bitllet d'avió en línia
Suposeu que esteu tractant de reservar un bitllet d’avió en línia. Comproveu el vol que voleu i descobriu un bitllet disponible.
Encara no ho sabem, però és l’últim bitllet en aquest vol. Mentre esteu escrivint les dades de la targeta de crèdit, un altre client amb un compte especial en l’aerolínia fa la comanda per al bitllet. Nosaltres encara no hem pagat el bitllet i l’altra persona ha vist un seient lliure i l’ha reservat mentre estem escrivint les dades de la targeta de crèdit. Ara confirmem la compra del bitllet, i ja que el sistema sabia que hi havia un seient disponible quan es va iniciar la transacció, de manera incorrecta assumeix que un seient està disponible, i es fa el pagament amb la targeta. (Per descomptat, les línies aèries tenen sistemes més sofisticats d’evitar aquest tipus bàsic d’errors de reserva de bitllets, però aquest exemple serveix per il·lustrar el principi.)
El codi executat per la sol·licitud de reserva pot ser com aquest:
- Comprovar si hi ha seients disponibles.
- Si és així, oferir seient al client.
- Si el client accepta l’oferta, preguntarà pel nombre de targeta de crèdit.
- Autoritzar les transaccions de targetes de crèdit amb el banc.
- Dèbit a la targeta.
- Assignar seients.
- Reduir el nombre de places lliures disponibles segons la quantitat comprada.
La seqüència de les dues accions concurrents la veiem a la taula.
| Client A | Client B | Seients disponibles |
|---|---|---|
| Comprova si hi ha seients disponibles | 1 | |
| Comprova si hi ha seients disponibles | 1 | |
| Si és així, s’ofereix seient al client | 1 | |
| Si és així, s’ofereix seient al client | 1 | |
| Si el client accepta l’oferta se li pregunta si fa servir targeta de crèdit o té un compte de la companyia | 1 | |
| Si el client accepta l’oferta se li pregunta si fa servir targeta de crèdit o té un compte de la companyia | 1 | |
| Donem el codi de la targeta de crèdit | Donem el compte de client | 1 |
| Demana autorització de transacció en el banc | 1 | |
| Verifica si el compte és vàlid | 1 | |
| Actualitza el compte amb la nova transacció | 1 | |
| Ho carrega al compte del banc | Assigna seient | 1 |
| Assigna seient | Actualitza el nombre de seients disponibles | 0 |
| Actualitza el nombre de seients disponibles | -1 |
Com podem resoldre aquest problema pel que fa a la reserva de bitllets?
Podem millorar el codi verificant si el seient estava disponible tan bon punt com ens disposem a carregar els diners, però encara que reduïm l’interval de temps el risc continua existint.
Podríem anar a l’extrem oposat per resoldre el problema, i permetre que una sola persona tingui accés al sistema de tiquets de reserva en qualsevol moment, però el rendiment seria terrible i els clients se n’anirien a un altre lloc.
Pel que fa a l’aplicació, el que tenim és una secció crítica de codi, una petita secció de codi que necessita accés exclusiu a algunes de les dades. Podríem escriure la nostra aplicació utilitzant un semàfor, o una tècnica similar, per administrar l’accés a la secció crítica de codi. Per a això seria necessari que totes les aplicacions d’accés a la base de dades haguessin d’utilitzar el mateix semàfor. En lloc d’escriure la lògica de l’aplicació, és més fàcil emprar l’SGBD per resoldre el problema.
Pel que fa a la base de dades, el que tenim aquí és una transacció, un conjunt de manipulacions de dades de comprovació de la disponibilitat de places per mitjà de fer el dèbit del compte o targeta i l’assignació del seient, la qual cosa ha de passar com una sola unitat de treball.
Regles ACID
ACID és un acrònim d’ús freqüent per descriure les quatre propietats que ha de tenir una transacció:
- Atòmica (atomic): una transacció, tot i que és un grup d’accions individuals sobre la base de dades, ha d’ocórrer com una sola unitat. Una transacció ha de passar exactament una vegada, sense subconjunts i sense la repetició involuntària de cap acció. En el nostre exemple la banca, el moviment de diners, ha de ser atòmic. El dèbit d’un compte i el crèdit dels altres dos han de passar com si fossin una sola acció, tot i que les sentències SQL són consecutives.
- Consistent (consistent): al final d’una transacció, el sistema ha de ser deixat en un estat coherent. En el nostre exemple de la banca, al final d’una transacció tots els comptes han de reflectir amb precisió els crèdits i dèbits produïts.
- Aïllada (isolated): això significa que cada transacció, sense importar quantes transaccions hi hagi en aquell moment en progrés en una base de dades, ha d’aparèixer com a independent de totes les altres transaccions. En el nostre exemple d’avió de reserva, les transaccions de processament de dos clients simultanis que es comporten com si cada un tingués l’ús exclusiu de la base de dades. En la pràctica, sabem que això no pot ser veritat si volem tenir un rendiment raonable sobre la base de dades multiusuari, i de fet resulta ser un dels punts que cal tenir en compte des d’un punt de vista pràctic en aplicacions en el món real i pot ser un obstacle molt important perquè la nostra base de dades tingui un comportament ideal.
- Durable (durable): una vegada que una transacció s’hagi completat, ha de romandre completada. Una vegada que els diners han estat transferits amb èxit entre els comptes, han de romandre transferits, fins i tot si falla l’alimentació i la màquina que executa la base de dades té un poder sense control cap avall. En el PostgreSQL, com en la majoria de bases de dades relacionals, això s’aconsegueix utilitzant un fitxer de registre de transaccions, tal com es descriu a continuació. La durabilitat de la transacció passa sense intervenció de l’usuari.
El registre de transaccions
Els arxius de registre de transaccions s’utilitzen internament a la base de dades per assegurar-se que una transacció perdura.
La manera com treballa l’arxiu de registre de transaccions és molt senzilla. Quan s’executa una transacció, no solament s’escriuen els canvis a la base de dades, sinó també en un registre. Quan es completa una transacció, s’escriu un marcador per dir que la transacció ha acabat, i les dades del fitxer de registre es veuen obligades a emmagatzemar-se permanentment, de manera segura, encara que es bloquegi el servidor de base de dades.
Si el servidor de bases de dades per alguna raó cau, enmig d’una transacció, i a continuació, es torna a arrencar el servidor, aquest ha de ser capaç de garantir de manera automàtica que les transaccions fetes es reflecteixin correctament en la base de dades (per mitjà d’operacions a termini en el registre de transaccions, però no en la base de dades). En cap cas no hi ha hagut cap canvi en les transaccions que encara estaven en curs quan el servidor va deixar de donar servei.
El registre de transaccions que manté PostgreSQL no solament és el registre de tots els canvis que s’estan fent en la base de dades, sinó que també registra la manera de revertir. Òbviament, aquest arxiu es pot fer ràpidament molt gran. Una vegada que s’executa una sentència COMMIT per a una transacció, llavors el PostgreSQL sap que ja no és necessari emmagatzemar la informació sobre “com es desfà”, ja que el canvi de base de dades ara és irrevocable, si més no per a la base de dades (l’aplicació podria executar codi addicional per revertir els canvis).
El PostgreSQL en realitat utilitza una tècnica en què les dades s’escriuen en el registre de transaccions abans que s’escriguin al disc per a les taules, perquè sap que una vegada que les dades s’escriuen en el fitxer de registre, es pot recuperar l’estat previst de les dades de la taula a partir del registre, encara que el sistema falli abans que els arxius de dades reals hagin estat actualitzats. Això es diu escriptura anticipada de registre (WAL).
Podeu trobar més detalls sobre el funcionament de WAL en la documentació del PostgreSQL.
Dinàmica de transaccions
Abans d’examinar els aspectes més complexos de les transaccions i com es comporten amb múltiples usuaris concurrents de la base de dades, hem de veure com es comporten amb un sol usuari. Fins i tot d’aquesta manera més aviat simplista de treball, hi ha avantatges reals per a l’ús de transaccions.
El gran avantatge de les transaccions és que permeten executar diverses instruccions SQL, i després, en una etapa posterior, permeten desfer la feina que han fet, si així ho decideixen, com es mostra a la figura, figura i figura. D’altra banda, si un dels seus estats d’SQL falla, pot desfer la feina que han fet de nou al punt predeterminat.
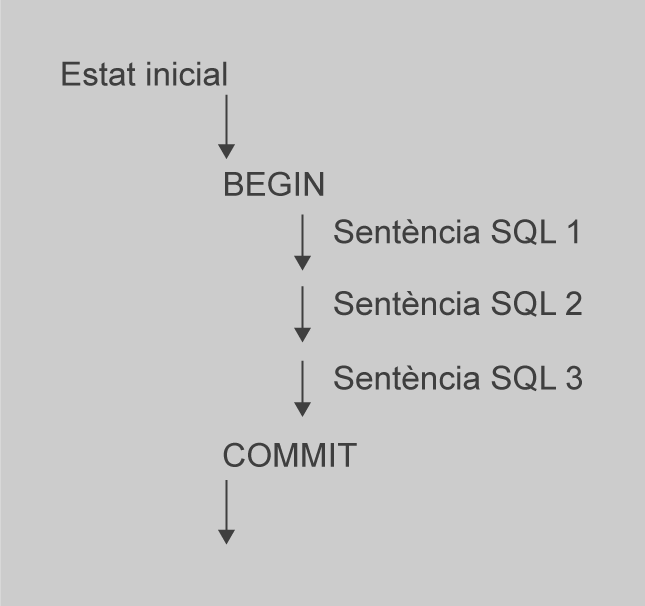
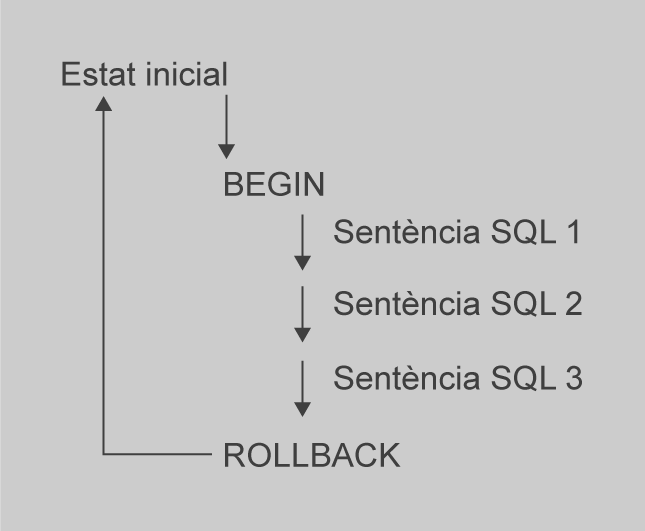
Mitjançant una transacció, l’aplicació no s’ha de preocupar per si s’han fet els canvis en l’emmagatzematge a la base de dades ni de la manera de desfer. Simplement pot demanar al motor de la base de dades per desfer un lot de canvis alhora.
Nivells d’aïllament
El nivell d’aïllament d’una transacció determina quines dades podem veure de la transacció quan altres transaccions estan funcionant en el mateix moment.
Mentre es consulta una base de dades, cada transacció veu una imatge de les dades, és a dir, una versió de la base de dades, sense tenir en compte l’estat actual de les dades que hi ha per sota. Així s’evita que la transacció vegi dades inconsistents produïdes per l’actualització d’una altra transacció concurrent, i proporciona aïllament transaccional per a cada sessió de la base de dades.
L’estàndard SQL defineix quatre nivells d’aïllament d’una transacció tenint en compte tres fenòmens dels quals hem de ser previnguts quan es fan transaccions concurrents.
Aquests fenòmens no desitjats són:
- Lectura bruta (dirty read): una transacció llegeix dades escrites per una transacció concurrent no confirmada.
- Lectura no repetida (nonrepeatable read): una transacció torna a llegir dades que prèviament ha llegit i troba que les dades han estat modificades per una altra transacció (que va ser confirmada des de la lectura inicial de la primera).
- Lectura fantasma (phantom read): una transacció torna a executar una consulta que retorna un conjunt de files que satisfan una condició de cerca i troba que el conjunt de files que satisfà la condició ha canviat pel fet que s’ha comès recentment una altra transacció.
Per assolir això es defineixen els nivells d’aïllament següents:
READ COMMITTED, quan una transacció només pot veure els canvis confirmats abans que ella comenci. És el valor per defecte.SERIALIZABLE, quan totes les instruccions de la transacció en curs poden veure sols els canvis confirmats abans que la primera consulta o la primera instrucció de modificació de dades s’hagi executat en aquesta transacció.
L’SQL estàndard defineix dos nivells addicionals, READ UNCOMMITTED i REPEATABLE READ.
El PostgreSQL utilitza el que s’anomena aïllament transaccional i regles de resolució de conflictes per resoldre operacions concurrents, i té dos nivells d’aïllament: serialitzable i lectura confirmada (SERIALIZABLE i READ COMMITTED).
En el PostgreSQL, sols tenim els dos primers nivells d’aïllament, ja que READ UNCOMMITTED és tractat com READ COMMITTED i REPEATABLE READ és tractat com SERIALIZABLE.
- En el nivell serialitzable (
SERIALIZABLE) es pren una instantània al començament de la transacció. Es fixa una vista de la lectura de la base de dades durant la transacció. - En el nivell de lectura confirmada (
READ COMMITTED) es pren una nova instantània al començament de cada consulta. Així, la vista de la base de dades és estable durant la iteració d’una consulta, però pot canviar durant les altres consultes que es facin dins d’una transacció.
Com veurem a la taula, l’estàndard ANSI defineix quins nivells d’aïllament diferents d’una base de dades es poden utilitzar per fer front a la possibilitat de tipus de fenòmens indesitjables, dirty reads, unrepeatable reads i phantom reads.
| Definició del nivell d’aïllament | Dirty Read | Unrepeatable Read | Phantom Read |
|---|---|---|---|
| Read Uncommitted | Possible | Possible | Possible |
| Read Committed | No possible | Possible | Possible |
| Repeatable Read | No possible | No Possible | Possible |
| Serializable | No possible | No possible | No possible |
Sentències SQL implicades en la gestió de transaccions
Inici d'una transacció
Cal remarcar que en el PostgreSQL la sentència START TRANSACTION té la mateixa funció que BEGIN, i com hem vist, serveixen per iniciar una transacció.
La sintaxi és així:
O també així:
En tots dos casos el mode_transacció pot ser un dels següents:
Canvi de nivell d'aïllament
Si cal es pot canviar el nivell d’aïllament utilitzant la sentència següent:
La sentència SET TRANSACTION afecta només la transacció actual i n’inicialitza les característiques.
Si es vol canviar el nivell d’aïllament per a la sessió es pot utilitzar la sentència SET SESSION:
En el PostgreSQL, les transaccions per defecte funcionen amb el nivell d’aïllament READ COMMITTED.
El nivell d’aïllament de la transacció no es pot modificar després que la primera consulta o la primera instrucció de modificació de dades (SELECT, INSERT, DELETE, UPDATE, FETCH o COPY) d’una transacció hagi estat executada.
Finalització d'una transacció
Per donar per finalitzat una transacció s’utilitza indistintament el COMMIT i l’END.
L’ordre END és un sinònim de COMMIT. La sintaxi és la següent:
La sintaxi de COMMIT és:
Avortar una transacció
Per avortar la transacció s’utilitza ROLLBACK:
En tots els casos WORK | TRANSACTION són opcionals i poden ser ignorats o utilitzar-los per fer el nostre SQL més llegible.
Bloquejos
La majoria de bases de dades de les aplicacions de transaccions, en particular, en aïllar les transaccions d’usuari diferents l’una de l’altra, utilitza els bloquejos per restringir l’accés a les dades d’altres usuaris.
De manera simplista, hi ha dos tipus de bloquejos:
- El bloqueig compartit, que permet a altres usuaris llegir, però no actualitzar les dades.
- El bloqueig exclusiu, que impedeix altres transaccions, fins i tot la lectura de les dades.
Per exemple, el servidor bloqueja les files que estan essent modificades per una transacció fins que es completi la transacció, i llavors els bloquejos (LOCK) són alliberats. Tot això es fa automàticament, en general sense que els usuaris de la base de dades siguin conscients del bloqueig que està duent a terme.
La mecànica real i les estratègies necessàries per al bloqueig són molt complexes, i s’utilitzen diferents tipus de LOCK, depenent de les circumstàncies.
La documentació del PostgreSQL descriu vuit tipus diferents de combinacions de bloqueig. El PostgreSQL també implementa un mecanisme inusual per a l’aïllament de les transaccions utilitzant un model multiversió, cosa que redueix els conflictes entre els bloquejos i en millora significativament el rendiment en comparació d’altres règims.
Afortunadament, els usuaris de la base de dades, en general s’han de preocupar pel que fa als bloquejos només en dues circumstàncies: evitar abraçades mortals (i la recuperació d’aquestes) i el bloqueig explícit generat per una aplicació.
Control de concurrència multiversió
El PostgreSQL manté la consistència de les dades en un model multiversió: control de la concurrència multiversió (MVCC). Aquesta és una tècnica avançada per millorar les prestacions d’una base de dades en un entorn multiusuari que implementa el PostgreSQL des de la versió 6.5 del juny de 1999.
L’MVCC és la tecnologia utilitzada per evitar bloquejos innecessaris. Si alguna vegada hem utilitzat algun SGBD amb capacitats SQL, com ara MySQL, probablement hem pogut notar que hi ha vegades en què una lectura ha d’esperar per accedir a la informació de la base de dades. L’espera està provocada per usuaris que estan escrivint en aquesta base de dades. Resumint, el lector està bloquejat pels escriptors que estan actualitzant els registres.
Mitjançant l’ús d’MVCC, el PostgreSQL evita aquest problema per complet. L’MVCC està considerat millor que el bloqueig en l’àmbit de fila perquè un lector mai no és bloquejat per un escriptor. En comptes d’això, el PostgreSQL manté un registre de totes les transaccions fetes pels usuaris de la base de dades. El PostgreSQL és capaç de manipular els registres sense necessitat que els usuaris hagin d’esperar que els registres estiguin disponibles.
Abraçades mortals
Què passa quan dues aplicacions diferents intenten canviar les mateixes dades al mateix temps?
És fàcil de veure: només cal posar en marxa dues sessions de psql i tractar de canviar la mateixa fila en les dues transaccions (taula).
| Sessió 1 | Sessió 2 |
|---|---|
| Actualitza fila 10 | |
| Actualitza fila 11 | Actualitza fila 10 |
| Actualitza fila 11 |
En aquest punt, les dues sessions estan bloquejades, ja que cada una està esperant que l’altra faci COMMIT.
Aquest comportament és la clau per entendre per què el valor per defecte que assigna el PostgreSQL al mode d’aïllament d’una transació és READ COMMITED.
Cal un compromís (trade-off) entre la concurrència, el rendiment i minimitzar el nombre de bloquejos per una banda, i la consistència i el comportament ideal per l’altra. A mesura que augmenta el nivell d’aïllament, el rendiment de la base de dades multiusuari es degrada.
A mesura que intentem ajustar el comportament de la base de dades com a ideal, observem que el nombre de bloquejos necessaris augmenta, la concurrència entre els diferents usuaris disminueix, i també les caigudes de rendiment en general. Es tracta d’un lamentable però inevitable trade-off.
En general, si dues sessions d’usuari intenten accedir a la mateixa fila, no hi ha un impacte real sobre els usuaris, tret que el segon usuari ha d’esperar l’accés del primer usuari per completar el seu. Una situació molt més greu és quan dues sessions es fan una abraçada mortal entre si.
Bloqueig explícit
De tant en tant, és possible que el bloqueig automàtic que ofereix PostgreSQL no sigui suficient per a les nostres necessitats. En aquest cas, pot ser que hàgim de bloquejar de manera explícita algunes files o potser tota la taula.
És possible bloquejar files o només les taules dins d’una transacció.
Un cop finalitzi la transacció, ja sigui amb un COMMIT o ROLLBACK, tots els bloquejos adquirits durant l’operació s’alliberaran automàticament.
No hi ha manera d’alliberar bloquejos de manera explícita durant una transacció, per la senzilla raó que el fet d’alliberar el bloqueig en una fila que es canvia durant una operació pot permetre a una altra aplicació fer el canvi, cosa que impediria fer correctament l’acció d’una ordre ROLLBACK i poder desfer el canvi inicial.
Bloquejos a escala de fila
Aquest tipus de bloquejos es produeixen quan s’actualitzen camps interns d’una fila (o s’esborren o es marquen per ser actualitzats). El PostgreSQL no reté en memòria cap informació sobre les files modificades.
La necessitat més comuna és la de bloquejar un nombre de files abans de fer-hi canvis. Això pot ser útil per evitar abraçades mortals. Mitjançant el bloqueig “per endavant” podem preveure quin és el conjunt de files que hauran de canviar i assegurar-nos que no tindrem cap conflicte amb altres transaccions.
Per bloquejar un conjunt de files, simplement emetem una instrucció SELECT query FOR UPDATE, com en aquest exemple:
I ens retorna tantes files com resultin d’aquesta consulta O també:
I això no ens retorna cap fila, ja que possiblement les hem previstes acuradament i de moment no ens interessa conèixer-ne el valor, amb la qual cosa minimitzem la quantitat de retorn de dades.
En aquest instant, hi podria haver dues files amb la variable customer_id amb valors 3 i 6. Si nosaltres les volguéssim actualitzar en una sessió psql concurrent:
Ara veiem que aquesta segona sessió roman bloquejada fins que premem Ctrl+C per avortar-la o la primera sessió faci un COMMIT o un ROLLBACK.
Cal tenir en compte que SELECT FOR UPDATE modificarà les files seleccionades marcant-les de tal manera que no puguin ser escrites en disc per part d’altres transaccions.
Els bloquejos a escala de fila no afecten les dades consultades. Aquests s’utilitzen només per bloquejar escriptures a la mateixa fila.
Bloquejos a escala de taula
El bloqueig de taula és altament recomanable per assegurar l’aïllament en la transacció.
El PostgreSQL ofereix diferents tipus de bloqueig per controlar l’accés concurrent a les dades d’una taula.
La sintaxi del bloqueig de taules és la següent:
Generalment si volem blocar una taula podem emprar la sintaxi més simple:
Que seria el mateix com fer:
Totes les formes de bloqueig (excepte el tipus de bloqueig ACCESS SHARE) adquirides en una transacció es mantenen fins al final d’aquesta.
Dues transaccions no poden conservar bloquejos de tipus en conflicte sobre una mateixa taula en el mateix moment. No obstant això, una transacció no entra mai en conflicte amb ella mateixa.
Guions
De vegades pot interessar agrupar en seqüència diferents instruccions SQL que cal executar repetidament i, per a aquests casos, els SGBD acostumen a oferir la possibilitat de crear guions que agrupen les diverses sentències, de manera seqüencial.
Els guions no són altra cosa que la seqüència ordenada d’instruccions SQL, que sol proporcionar el següent:
- Establiment de variables d’entorn.
- Connexió com a superusuari.
- Eliminació de l’usuari o esquema corresponent si ja existia.
- Creació d’un usuari o esquema corresponent.
- Concessió de privilegis al nou usuari.
- Connexió com a nou usuari.
- Creació de taules i índexs amb inserció de dades.
Creació i execució de guions
Podem recollir un grup de sentències de psql (SQL i intern) en un arxiu i l’utilitzem com un simple script.
La instrucció \i interna llegirà un conjunt d’ordres psql des d’un arxiu.
Aquesta característica és especialment útil per crear i omplir taules.
Creem un script amb un editor i donem l’extensió .sql a l’arxiu per una qüestió de convenció, i executem la instrucció interna \i :
A més de ser interactiu, el psql pot processar guions (ordres per lots emmagatzemades en un arxiu del sistema operatiu) mitjançant la sintaxi següent:
Encara que l’ordre següent també funciona en el mateix sentit, no és recomanable usar-lo perquè d’aquesta manera el psql no mostra informació de depuració important, com els nombres de línia on es localitzen els errors, si n’hi ha:
Es pot sol·licitar l’execució d’una sola ordre i acabar immediatament mitjançant la manera següent:
El PgAdmin 3 ofereix una interfície gràfica per a l’edició i execució de guions.
Formats de sortida
L’intèrpret psql mateix ens proporciona mecanismes per emmagatzemar en fitxer el resultat de les sentències:
- Especificant el fitxer destinació directament en finalitzar una sentència:
- Mitjançant una canonada enviem la sortida a una ordre Unix:
Podem veure que hem emmagatzemat el resultat en el fitxer /tmp/a.txt.
- Mitjançant l’ordre
\oes pot indicar on ha d’anar la sortida de les sentències SQL que s’executin d’ara endavant:
- Quan es vulgui tornar a la sortida estàndard
STDOUT, simplement es donarà l’ordre\osense cap paràmetre.
En l’ordre \o s’ha d’especificar un fitxer o bé una ordre que anirà rebent els resultats mitjançant una canonada.
- Es pot especificar el format de sortida dels resultats d’una sentència. Per defecte, el psql els mostra en forma tabular mitjançant text. Per canviar-ho, s’ha de modificar el valor de la variable interna
formatmitjançant l’ordre\pset.
Vegem, en primer lloc, l’especificació del format de sortida:
En haver especificat que es vol la sortida en HTML, la podríem redirigir a un fitxer (ja hem vist com s’ha de fer) i generar un arxiu HTML que permetés veure el resultat de la consulta mitjançant un navegador web convencional.
Hi ha altres formats de sortida, com aligned, unaligned, html i latex. Per defecte, el psql mostra el resultat en format aligned.
Tenim també multitud de variables per ajustar els separadors entre columnes, el nombre de registres per pàgina, el separador entre registres, el títol de la pàgina HTML, etc.
Amb aquesta configuració, i dirigint la sortida a un fitxer, generaríem un fitxer CSV preparat per ser llegit en un full de càlcul o un altre programa d’importació de dades.