

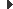
DDL
A banda de les conegudes instruccions per consultar i modificar les dades, el llenguatge SQL aporta instruccions per definir les estructures en què s’emmagatzemen les dades. Així, per exemple, tenim instruccions per a la creació, eliminació i modificació de taules i índexs, i també instruccions per definir vistes.
En el MySQL, l’SQLServer i el PostgreSQL qualsevol instància de l’SGBD gestiona un conjunt de bases de dades o esquemes, anomenat cluster database, el qual pot tenir definit un conjunt d’usuaris amb els privilegis d’accés i gestió que corresponguin.
En el MySQL, l’SQLServer i el PostgreSQL, el llenguatge SQL proporciona una instrucció CREATE DATABASE <nom_base_dades> que permet crear, dins la instància, les diverses bases de dades. Aquesta instrucció CREATE DATABASE es pot considerar dins l’àmbit del llenguatge LDD.
La sentència CREATE SCHEMA en l’àmbit del llenguatge LDD està destinada a la creació d’un esquema en què es puguin definir taules, índexs, vistes, etc. En MySQL, CREATE SCHEMA i CREATE TABLE són sinònims.
Distinció entre àmbits LDD i LCD en el llenguatge SQL
Sovint, els àmbits LDD (llenguatge de definició de dades) i LCD (llenguatge per al control de les dades) es fonen en un únic àmbit i es parla únicament d’LDD.
Disposem, també, de la instrucció USE <nom_base_dades> per decidir la base de dades en què es treballarà (establiment de la base de dades de treball per defecte).
Regles i indicacions per anomenar objectes en MySQL
Dins de MySQL, a banda de taules, trobarem altres tipus d’objectes: índexs, columnes, àlies, vistes, procediments, etc.
Els noms dels objectes dins d’una base de dades, i les bases de dades mateixes, en MySQL actuen com a identificadors, i, com a tals no es podran repetir en un mateix àmbit. Per exemple, no podem tenir dues columnes d’una mateixa taula que s’anomenin igual, però sí en taules diferents.
Els noms amb què anomenem els objectes dins d’un SGBD hauran de seguir unes regles sintàctiques que hem de conèixer.
En general, les taules i les bases de dades són not case sensitive, és a dir, que hi podem fer referència en majúscules o minúscules i no hi trobarem diferència, si el sistema operatiu sobre el qual estem treballant suporta not case sensitive.
Per exemple, en Windows podem executar indiferentment:
O bé:
El que no acostumem a fer, però, és que dins d’una mateixa sentència ens referim a un mateix objecte en majúscules i en minúscules a la vegada:
Els noms de columnes, índexs, procediments i disparadors (triggers), en canvi, sempre són not case sensitive.
Els noms dels objectes en MySQL admeten qualsevol tipus de caràcter, excepte / \ i .
De totes maneres, es recomana utilitzar caràcters alfabètics estrictament. Si el nom inclou caràcters especials és obligatori fer-hi referència entre cometes del tipus accent greu (`). Per exemple:
S’admeten també les cometes dobles (“) si activem el mode ANSI_QUOTES:
Qualsevol objecte pot ser referit utilitzant les cometes, encara que no calgui, com ara en l’exemple:
Tot i que no és recomanable, es poden anomenar objectes amb paraules reservades del mateix llenguatge com ara SELECT, INSERT, DATABASE, etc. Aquests noms, però, s’hauran de posar obligatòriament entre cometes.
La longitud màxima dels objectes de la base de dades és 64 caràcters, excepte per als àlies, que poden arribar a ser de 256.
Finalment, vegem algunes indicacions per anomenar objectes:
- Utilitzar noms sencers, descriptius i pronunciables i, si no és factible, bones abreviatures. En anomenar objectes, sospeseu l’objectiu d’aconseguir noms curts i fàcils d’utilitzar davant l’objectiu de tenir noms que siguin descriptius. En cas de dubte, escolliu el nom més descriptiu, ja que els objectes de la base de dades poden ser utilitzats per molta gent al llarg del temps.
- Utilitzar regles d’assignació de noms que siguin coherents. Així, per exemple, una regla podria consistir a començar amb gc_ tots els noms de les taules que formen part d’una gestió comercial.
- Utilitzar el mateix nom per descriure la mateixa entitat o el mateix atribut en diferents taules. Així, per exemple, quan un atribut d’una taula és clau forana d’una altra taula, és molt convenient anomenar-lo amb el nom que té en la taula principal.
Comentaris en MySQL
El servidor MySQL suporta tres estils de comentaris:
#fins al final de la línia.—<espai en blanc>fins al final de la línia./* fins a la propera seqüència */. Aquests tipus de comentaris admeten diverses línies de comentari.
Exemples dels diferents tipus de comentaris són els següents:
Motors d'emmagatzematge en MySQL
MySQL suporta diferents tipus d’emmagatzematge de taules (motors d’emmagatzemament o storage engines, en anglès). I quan es crea una taula cal especificar en quin sistema dels possibles el volem crear.
Per defecte, MySQL a partir de la versió 5.5.5 crea les taules de tipus InnoDB, que és un sistema transaccional, és a dir, que suporta les característiques que fan que una base de dades pugui garantir que les dades es mantindran consistents.
Les propietats que garanteixen els sistemes transaccionals són les característiques anomenades ACID. ACID és l’acrònim anglès d’atomicity, consistency, isolation, durability:
- Atomicitat: es diu que un SGBD garanteix atomicitat si qualsevol transacció o bé finalitza correctament (commit), o bé no deixa cap rastre de la seva execució (rollback).
- Consistència: es parla de consistència quan la concurrència de diferents transaccions no pot produir resultats anòmals.
- Aïllament (o isolament): cada transacció dins del sistema s’ha d’executar com si fos l’única que s’executa en aquell moment.
- Definitivitat: si es confirma una transacció, en un SGBD, el resultat d’aquesta ha de ser definitiu i no es pot perdre.
Només el motor InnoDB permet crear un sistema transaccional en MySQL. Els altres tipus d’emmagatzemament no són transaccionals i no ofereixen control d’integritat a les bases de dades creades.
Evidentment, aquest sistema (InnoDB) d’emmagatzematge és el que sovint interessarà utilitzar per a les bases de dades que creem, però hi pot haver casos en què sigui interessant considerar altres tipus de motors d’emmagatzematge. Per això, MySQL també ofereix altres sistemes com ara, per exemple:
- MyISAM: era el sistema per defecte abans de la versió 5.5.5 de MySQL. S’utilitza molt en aplicacions web i en aplicacions de magatzem de dades (datawarehousing).
- Memory: aquest sistema emmagatzema tot en memòria RAM i, per tant, s’utilitza per a sistemes que requereixin un accés molt ràpid a les dades.
- Merge: agrupa taules de tipus MyISAM per optimitzar llistes i cerques. Les taules que cal agrupar han de ser de semblants, és a dir, han de tenir el mateix nombre i tipus de columnes.
Per obtenir una llista dels motors d’emmagatzemament suportats per la versió MySQL que tingueu instal·lada, podeu executar l’ordre SHOW ENGINES.
Creació de taules
La sentència CREATE TABLE és la instrucció proporcionada pel llenguatge SQL per a la creació d’una taula.
És una sentència que admet múltiples paràmetres, i la sintaxi completa es pot consultar en la documentació de l’SGBD que correspongui, però la sintaxi més simple i usual és aquesta:
Recordeu que els elements que es posen entre claudàtors ([ ]) són opcionals.
Fixem-nos que hi ha força elements que són optatius:
- Les parts obligatòries són el nom de la taula i, per cada columna, el nom i el tipus de dada.
- El nom de l’esquema en què es crea la taula és optatiu i, si no s’indica, la taula s’intenta crear dins l’esquema en què estem connectats.
- Cada columna té permès definir-hi un valor per defecte (opció default) a partir d’una expressió, el qual utilitzarà l’SGBD en les instruccions d’inserció quan no s’especifiqui un valor per a les columnes que tenen definit el valor per defecte. En MySQL el valor per defecte ha de ser constant, no pot ser, per exemple, una funció com ara
NOW()ni una expressió com araCURRENT_DATE. - La definició de les restriccions per a una o més columnes també és optativa en el moment de procedir a la creació de la taula.
També és molt usual crear una taula a partir del resultat d’una consulta, amb la sintaxi següent:
En aquesta sentència, no es defineixen els tipus de camps que es corresponen amb els tipus de les columnes recuperades en la sentència SELECT. La definició dels noms dels camps és optativa; si no s’efectua, els noms de les columnes recuperades passen a ser els noms dels camps nous. Caldrà, però, afegir-hi les restriccions que corresponguin. La taula nova conté una còpia de les files resultants de la sentència SELECT.
A l’hora de definir taules, cal tenir en compte diversos conceptes:
- Els tipus de dades que l’SGBD possibilita.
- Les restriccions sobre els noms de taules i columnes.
- La integritat de les dades.
L’SGBD MySQL proporciona diversos tipus de restriccions (constraints en la nomenclatura que s’ha d’utilitzar en els SGBD) o opcions de restricció per facilitar la integritat de les dades. En general, es poden definir en el moment de crear la taula, però també es poden alterar, afegir i eliminar amb posterioritat.
En l’apartat “Consultes de selecció simples” de la unitat “Llenguatge SQL. Consultes”, es presenten àmpliament els tipus de dades més importants en l’SGBD MySQL.
Cada restricció porta associat un nom (únic en tot l’esquema) que es pot especificar en el moment de crear la restricció. Si no s’especifica, l’SGBD n’assigna un per defecte.
Vegem, a continuació, els diferents tipus de restriccions:
Clau primària
Per definir la clau primària d’una taula, cal utilitzar la constraint primary key.
Si la clau primària és formada per una única columna, es pot especificar en la línia de definició de la columna corresponent, amb la sintaxi següent:
En canvi, si la clau primària és formada per més d’una columna, s’ha d’especificar obligatòriament en la zona final de restriccions sobre columnes de la taula, amb la sintaxi següent:
Les claus primàries que afecten una única columna també es poden especificar amb aquest segon procediment.
Obligatorietat de valor
Per definir l’obligatorietat de valor en una columna, cal utilitzar l’opció not null.
Aquesta restricció es pot indicar en la definició de la columna corresponent amb aquesta sintaxi:
Per descomptat, no cal definir aquesta restricció sobre columnes que formen part de la clau primària, ja que formar part de la clau primària implica, automàticament, la impossibilitat de tenir valor nuls.
Unicitat de valor
Per definir la unicitat de valor en una columna, cal utilitzar la constraint unique.
Si la unicitat s’especifica per a una única columna, es pot assignar en la línia de definició de la columna corresponent, amb la sintaxi següent:
En canvi, si la unicitat s’aplica sobre diverses columnes simultàniament, cal especificar-la obligatòriament en la zona final de restriccions sobre columnes de la taula, amb la sintaxi següent:
Aquest segon procediment també es pot emprar per aplicar la unicitat a una única columna.
Per descomptat, no cal definir aquesta restricció sobre un conjunt de columnes que formen part de la clau primària, ja que la clau primària implica, automàticament, la unicitat de valors.
Condicions de comprovació
Per definir condicions de comprovació en una columna, cal utilitzar l’opció check (<condició>).
Aquesta restricció es pot indicar en la definició de la columna corresponent:
També es pot indicar en la zona final de restriccions sobre columnes de la taula, amb la sintaxi següent:
AUTO_INCREMENT
Podem definir les columnes numèriques amb l’opció AUTO_INCREMENT. Aquesta modificació permet que en inserir un valor null o no inserir valor explícitament en aquella columna definida d’aquesta manera, s’hi afegeixi un valor per defecte consistent en el més gran ja introduït incrementat en una unitat.
Comentaris de columnes
Podem afegir comentaris a les columnes de manera que puguin quedar guardats a la base de dades i ser consultats. La manera de fer-ho és afegir la paraula COMMENT seguida del text que calgui posar com a comentari entre cometes simples.
Integritat referencial
Per definir la integritat referencial, cal utilitzar la constraint foreign key.
Si la clau forana és formada per una única columna, es pot especificar en la línia de definició de la columna corresponent, amb la sintaxi següent:
En canvi, si la clau forana és formada per més d’una columna, cal especificar-la obligatòriament en la zona final de restriccions sobre columnes de la taula, amb la sintaxi següent:
Les claus foranes que afecten una única columna també es poden especificar amb aquest segon procediment.
En qualsevol dels dos casos, es fa referència a la taula principal de la qual estem definint la clau forana, la qual cosa es fa amb l’opció references <taula>.
En MySQL la integritat referencial només s’activa si es treballa sobre el motor InnoDB i s’utilitza la sintaxi de constraint de la zona de definició de restriccions del final i, a més, es defineix un índex per a les columnes implicades en la clau forana.
La sintaxi per a la integritat referencial activa en MySQL és la següent (si s’utilitzen altres sintaxis, l’SGBD les reconeix però no les valida):
La sintaxi que hem presentat per tal de definir la integritat referencial no és completa. Ens falta tractar un tema fonamental: l’actuació que esperem de l’SGBD davant possibles eliminacions i actualitzacions de dades en la taula principal, quan hi ha files en altres taules que hi fan referència.
La constraint foreign key es pot definir acompanyada dels apartats següents:
on delete <acció>, que defineix l’actuació automàtica de l’SGBD sobre les files de la nostra taula que es veuen afectades per una eliminació de les files a les quals fan referència.on update <acció>, que defineix l’actuació automàtica de l’SGBD sobre les files de la nostra taula que es veuen afectades per una actualització del valor al qual fan referència.
Per si no us ha quedat clar, pensem en les taules DEPT i EMP de l’esquema empresa. La taula EMP conté la columna dept_no, que és clau forana de la taula DEPT. Per tant, en la definició de la taula EMP hem de tenir definida una constraint foreign key en la columna dept_no fent referència a la taula DEPT. En definir aquesta restricció de clau forana, el dissenyador de la base de dades va haver de prendre decisions respecte al següent:
- Com ha d’actuar l’SGBD davant l’intent d’eliminació d’un departament en la taula DEPT si hi ha files en la taula EMP que hi fan referència? Això es defineix en l’apartat
on delete <acció>. - Com ha d’actuar l’SGBD davant l’intent de modificació del codi d’un departament en la taula DEPT si hi ha files en la taula EMP que hi fan referència? Això es defineix en l’apartat
on update <acció>.
En general, els SGBD ofereixen diverses possibilitats d’acció, però no sempre són les mateixes. Abans de conèixer aquestes possibilitats, també ens cal saber que alguns SGBD permeten diferir la comprovació de les restriccions de clau forana fins a la finalització de la transacció, en lloc d’efectuar la comprovació -i actuar en conseqüència- després de cada instrucció. Quan això és factible, la definició de la constraint va acompanyada del mot deferrable o not deferrable. L’actuació per defecte acostuma a ser no diferir la comprovació.
Per tant, la sintaxi de la restricció de clau forana es veu clarament ampliada. Si s’efectua en el moment de definir la columna, tenim el següent:
Les opcions que ens podem arribar a trobar en referència a l’acció que acompanyi els apartats on update i on delete són aquestes: RESTRICT | CASCADE | SET NULL | NO ACTION
NO ACTIONoRESTRICT: són sinònims. És l’opció per defecte i no permet l’eliminació o actualització de dades en la taula principal.CASCADE: quan s’actualitza o elimina la fila pare, les files relacionades (filles) també s’actualitzen o eliminen automàticament.SET NULL: quan s’actualitza o elimina la fila pare, les files relacionades (filles) s’actualitzen a NULL. Cal haver-les definit de manera que admetin valors nuls, és clar.SET DEFAULT: quan s’actualitza o elimina la fila pare, les files relacionades (filles) s’actualitzen al valor per defecte. MySQL suporta la sintaxi, però no actua, davant d’aquesta opció.
L’opció CASCADE és molt perillosa en utilitzar-la amb on delete. Pensem què passaria, en l’esquema empresa, si algú decidís eliminar un departament de la taula DEPT i la clau forana en la taula EMP fos definida amb on delete cascade: tots els empleats del departament serien, immediatament, eliminats de la taula EMP.
De vegades, però, és molt útil acompanyant on delete. Pensem en la relació d’integritat entre les taules COMANDA i DETALL de l’esquema empresa. La taula DETALL conté la columna com_num, que és clau forana de la taula COMANDA. En aquest cas, pot tenir molt de sentit tenir definida la clau forana amb on delete cascade, ja que l’eliminació d’una ordre provocarà l’eliminació automàtica de les seves línies de detall.
A diferència de la caució en la utilització de l’opció cascade per a les actuacions on delete, s’acostuma a utilitzar molt per a les actuacions on update.
La taula mostra les opcions proporcionades per alguns SGBD actuals.
| SGBD | on update | on delete | Diferir actuació | no action | restrict | cascade | set null | set default |
|---|---|---|---|---|---|---|---|---|
| Oracle | No | Sí | No | Sí | No | Sí | Sí | No |
| MySQL | Sí | Sí | No | Sí | Sí | Sí | Sí | Sí |
| PostgreSQL | Sí | Sí | Sí | Sí | Sí | Sí | Sí | Sí |
| SQLServer 2005 | Sí | Sí | No | Sí | No | Sí | Sí | Sí |
| MS-Access 2003 | Sí | Sí | No | Sí | No | Sí | 3 | No |
Exemple 1 de creació de taules. Taules de l'esquema empresa
En primer lloc, cal destacar l’opció IF NOT EXISTS, opció molt utilitzada a l’hora de crear bases de dades per tal d’evitar errors en cas que la taula ja existeixi prèviament.
D’altra banda, cal destacar que la taula es defineix amb el nom de l’esquema `empresa`. Això no és necessari si prèviament es defineix aquest esquema com a esquema per defecte. Això es pot fer amb la sentència USE:
En les dues definicions de taula, la clau primària s’ha definit en la part inferior de la sentència, no pas en la mateixa definició de la columna, malgrat que es tractava de claus primàries que només tenien una única columna.
Fixeu-vos com s’han definit dos índexs per a les columnes CAP i DEPT_NO per tal de crear a posteriori les claus foranes corresponents. En el moment de la creació es crea la clau forana que fa referència de EMP a DEPT. No es crea, en canvi, la que fa referència de EMP a la mateixa taula i que serveix per referir-se al cap d’un empleat. El motiu és que si es definís aquesta clau forana en el moment de la creació de la taula, no hi podríem inserir valors fàcilment, ja que no tindria el valor de referència prèviament introduït a la taula. Per exemple, si hi volem inserir l’empleat número (EMP_NO) 7369 que té com a empleat cap el 7902 i aquest no és encara a la taula, no el podríem inserir perquè no existeix el 7902 encara a la taula. Una possible solució a aquest problema que s’anomena interbloqueig o deadlock, en anglès, és definir la clau forana a posteriori de les insercions. O bé, si l’SGBD ho permet, desactivar la foreign key abans d’inserir-la i tornar-la a activar en acabar. Així, doncs, després de les insercions caldrà modificar la taula i afegir-hi la restricció de clau forana.
Observeu, també, que s’ha utilitzat el modificador de tipus UNSIGNED per tal de definir els camps que necessàriament són considerats positius. De manera que si es fa una inserció del tipus següent, l’SGBD ens retornarà un error:
Fixem-nos, també, en la importància de l’ordre en què es defineixen les taules, ja que no seria possible definir la integritat referencial en la columna dept_no de la taula EMP sobre la taula DEPT si aquesta encara no fos creada.
En aquesta taula, en canvi, la clau primària s’ha definit en la mateixa definició de la columna.
Exemple 2 de creació de taules. Taules de l'esquema sanitat
Recordem que la taula es defineix amb el nom de l’esquema `sanitat`, però que això no és necessari si prèviament es defineix aquest esquema com a esquema per defecte:
La definició de la taula SALA necessita declarar la constraint PRIMARY KEY al final de la definició de la taula, ja que és formada per més d’un camp. En casos com aquest, aquesta és l’única opció i no és factible definir la constraint PRIMARY KEY al costat de cada columna, ja que una taula només admet una definició de constraint PRIMARY KEY.
La definició de la taula PLANTILLA necessita declarar les restriccions PRIMARY KEY i FOREIGN KEY al final de la definició de la taula perquè ambdues fan referència a una combinació de columnes.
Eliminació de taules
La sentència DROP TABLE és la instrucció proporcionada pel llenguatge SQL per a l’eliminació (dades i definició) d’una taula.
La sintaxi de la sentència DROP TABLE és aquesta:
L’opció if exists es pot especificar per tal d’evitar un error en cas que la taula no existeixi.
També es poden afegir les opcions cascade o restrict que en alguns SGBD fan que s’eliminin totes les definicions de restriccions d’altres taules que fan referència a la taula que es vol eliminar abans de fer-ho, o que s’impedeixi l’eliminació, respectivament. Sense l’opció cascade la taula que és referenciada per altres taules (a nivell de definició, independentment que hi hagi o no, en un moment determinat, files referenciades), l’SGBDR no l’elimina.
En MySQL, però, no es tenen efecte les opcions cascade o restrict i sempre cal eliminar les taules referides per tal de poder eliminar la taula referenciada.
Exemple d'eliminació de taules
Suposem que volem eliminar la taula DEPT de l’esquema empresa.
L’execució de la sentència següent és errònia:
L’SGBD informa que hi ha taules que hi fan referència i que, per tant, no es pot eliminar. I és lògic, ja que la taula DEPT està referenciada per la taula EMP.
Si de veritat es vol aconseguir eliminar la taula DEPT i provocar que totes les taules que hi fan referència eliminin la definició corresponent de clau forana, caldrà eliminar EMP prèviament. I, abans que aquesta, les altres taules que fan referència a aquesta altra. De forma que l’ordre per eliminar les taules sol ser l’ordre invers en què les hem creades.
Modificació de l'estructura de les taules
De vegades, cal fer modificacions en l’estructura de les taules (afegir-hi o eliminar-ne columnes, afegir-hi o eliminar-ne restriccions, modificar els tipus de dades…).
La sentència ALTER TABLE és la instrucció proporcionada pel llenguatge SQL per modificar l’estructura d’una taula.
La seva sintaxi és aquesta:
És a dir, una sentència alter table pot contenir diferents clàusules (com a mínim una) que modifiquin l’estructura de la taula. Hi ha clàusules de modificació de taula que poden anar acompanyades, en una mateixa sentència alter table, per altres clàusules de modificació, mentre que n’hi ha que han d’anar soles.
Cal tenir present que, per efectuar una modificació, l’SGBD no hauria de trobar cap incongruència entre la modificació que s’ha d’efectuar i les dades que ja hi ha en la taula. No tots els SGBD actuen de la mateixa manera davant aquestes situacions.
Així, l’SGBD MySQL, per defecte, no permet especificar la restricció d’obligatorietat (not null) a una columna que ja conté valors nuls (cosa lògica, no?) ni tampoc disminuir l’amplada d’una columna de tipus varchar a una amplada inferior a l’amplada màxima dels valors continguts en la columna.
En canvi, però, si s’activa l’opció ignore, la modificació especificada s’intenta fer, encara que calgui truncar o modificar dades de la taula ja existent. Per exemple, si intentem modificar la característica not null de la columna telèfon de la taula hospital, de l’esquema sanitat, atès que hi ha un valor nul, la sentència següent no s’executarà:
I el resultat de l’execució d’aquesta modificació serà un missatge tipus Error: Data truncated for column telefon at row 5.
En canvi, si utilitzem l’opció ignore podem executar la sentència següent que ens permetrà modificar l’opció not null de telèfon de manera que posarà un string buit en lloc de valor nul en les columnes que no compleixin la condició:
De manera similar, si volem disminuir la mida de la columna adreça de la taula hospital:
Aquest codi mostrarà un error similar a Error: Data truncated for column adreca at row 1 i no s’executarà la sentència. En canvi, si hi afegim l’opció ignore, el resultat serà la modificació de l’estructura de la taula i el truncament dels valors de les columnes afectades.
Vegem, a continuació, les diferents possibilitats d’alteració de taula, tenint en compte que en MySQL s’admeten diversos tipus d’alteracions en una mateixa clàusula d‘alter table, separades per coma:
1. Per afegir una columna
O bé, si cal definir-ne unes quantes de noves:
ADD [COLUMN] (nom_columna definició_columna,...)
2. Per eliminar una columna
3. Per modificar l’estructura d’una columna
O bé:
CHANGE [COLUMN] nom_columna_antic nom_columna_nou definició_columna
[FIRST|AFTER nom_columna]
4. Per afegir restriccions
Concretament, les restriccions que es poden afegir en MySQL són les següents:
ADD [CONSTRAINT [símbol]] PRIMARY KEY [tipus_index] (nom_columna_index,...) [opcions_index] ... ADD [CONSTRAINT [símbol]] UNIQUE [INDEX|KEY] [nom_index] [tipus_index] (nom_columna_index,...) [opcions_index] ... ADD [CONSTRAINT [símbol]] FOREIGN KEY [nom] (nom_columna1,...) REFERENCES taula (columna1, ....)
5. Per eliminar restriccions
6. Per afegir índexs
7. Per habilitar o deshabilitar els índexs
8. Per reanomenar una taula
9. Per reordenar les files d’una taula
10. Per canviar o eliminar el valor per defecte d’una columna
Exemple 1 de modificació de l'estructura d'una taula
Recordem l’estructura de la taula DEPT de l’esquema empresa:
Es vol modificar l’estructura de la taula DEPT de l’esquema empresa de manera que passi el següent:
- La columna loc passi a ser obligatòria.
- Afegim una columna numèrica de nom numEmps destinada a contenir el nombre d’empleats del departament.
- Eliminem l’obligatorietat de la columna nom.
- Ampliem l’amplada de la columna dnom a vint caràcters.
Ho podem aconseguir fent el següent:
Exemple 2 de modificació de l'estructura d'una taula, per problemes de deadlock
Per tal de crear l’estructura de les taules DEPT i EMP de l’empresa es creen les taules següents i s’hi afegeixen les files amb els valors introduint les sentències següents:
Per tal d’afegir la restricció que la columna cap fa referència a un empleat, de la mateixa taula, cal afegir-hi la restricció següent:
Fixeu-vos que no es podria haver definit aquesta restricció abans d’inserir els valors en les files perquè ja la primera fila inserida ja no compliria la restricció que el codi del seu cap fos prèviament inserit en la taula.
Índexs per a taules
Els SGBD utilitzen índexs per accedir de manera més ràpida a les dades. Quan cal accedir a un valor d’una columna en què no hi ha definit cap índex, l’SGBD ha de consultar tots els valors de totes les columnes des de la primera fins a l’última. Això resulta molt costós en temps i, com més files té la taula en qüestió, més lenta és l’operació. En canvi, si tenim definit un índex en la columna de cerca, l’operació d’accedir a un valor concret resulta molt més ràpid, perquè no cal accedir a tots els valors de totes les files per trobar el que es busca.
Índex tipus B-tree i hash
Els índexs B-tree són una organització de les dades en forma d’arbre, de manera que buscar un valor d’una dada resulti més ràpid que buscar-la dins d’una estructura lineal en què s’hagi de buscar des de l’inici fins al final passant per tots els valors.
Els índexs tipus hash tenen com a objectiu accedir directament a un valor concret mitjançant una funció anomenada funció de hash. Per tant, buscar un valor és molt ràpid.
MySQL utilitza índexs per facilitar l’accés a columnes que són PRIMARY KEY o UNIQUE i sol emmagatzemar els índexs utilitzant el tipus d’índex B-tree. Per a les taules emmagatzemades en MEMORY s’utilitzen, però, índexs de tipus HASH.
És lògic crear índexs per facilitar l’accés per a les columnes que necessitin accessos ràpids o molt freqüents. L’administrador de l’SGBD té, entre les seves tasques, avaluar els accessos que s’efectuen a la base de dades i decidir, si escau, l’establiment d’índexs nous. Però també és tasca de l’analista i/o dissenyador de la base de dades dissenyar els índexs adequats per a les diferents taules, ja que és la persona que ha ideat la taula pensant en les necessitats de gestió que tindran els usuaris.
La sentència CREATE INDEX és la instrucció proporcionada pel llenguatge SQL per a la creació d’índexs.
La seva sintaxi simple és aquesta:
Tot i que la creació d’un índex té associades moltes opcions, que en MySQL poden ser les següents:
En MySQL podem definir índexs que mantinguin valors no repetits, especificant la clàusula UNIQUE. També podem indicar que indexin tenint en compte el camp sencer d’una columna de tipus TEXT, si utilitzem un motor d’emmagatzemament de tipus MyISAM. MySQL suporta índexs sobre els tipus de dades geomètriques que suporta (SPATIAL).
Les opcions USING BTREE i USING HASH permeten forçar la creació d’un índex d’un tipus o un altre (índex tipus B-tree o tipus hash).
La modificació ASC o DESC sobre cada columna, però, és suportada sintàcticament donant suport a l’estàndard SQL però no té efecte: tots els índexs en MySQL són ascendents.
La sentència DROP INDEX és la instrucció proporcionada pel llenguatge SQL per a l’eliminació d’índexs.
La seva sintaxi és aquesta:
Exemple 1 de creació d'índexs. Taules de l'esquema empresa
El dissenyador de les taules de l’esquema empresa va considerar oportú crear els índexs següents:
Tots aquests índexs s’afegeixen als existents a causa de les restriccions de clau primària i d’unicitat.
Exemple 2 de creació d'índexs. Taules de l'esquema sanitat
El dissenyador de les taules de l’esquema sanitat va considerar oportú crear els índexs següents:
Tots aquests índexs s’afegeixen als existents a causa de les restriccions de clau primària i d’unicitat. Per visualitzar tots els índexs existents sobre una taula concreta podem utilitzar l’ordre:
En el cas de la taula doctor de l’esquema sanitat, podem observar el resultat visualitzat en l’eina Workbench de MySQL, en la figura.
Definició de vistes
Una vista és una taula virtual per mitjà de la qual es pot veure i, en alguns casos canviar, informació d’una o més taules.
Les vistes es corresponen amb els diferents tipus de consultes que proporciona l’SGBDR MS-Access.
Una vista té una estructura semblant a una taula: files i columnes. Mai no conté dades, sinó una sentència SELECT que permet accedir a les dades que es volen presentar per mitjà de la vista. La gestió de vistes és semblant a la gestió de taules.
La sentència CREATE VIEW és la instrucció proporcionada pel llenguatge SQL per a la creació de vistes.
La seva sintaxi és aquesta:
Com observareu, aquesta sentència és similar a la sentència per crear una taula a partir del resultat d’una consulta. La definició dels noms dels camps és optativa; si no s’efectua, els noms de les columnes recuperades passen a ser els noms dels camps nous. La sentència SELECT es pot basar en altres taules i/o vistes.
L’opció with check option indica a l’SGBD que les sentències INSERT i UPDATE que es puguin executar sobre la vista han de verificar les condicions de la clàusula where de la vista.
L’opció or replace en la creació de la vista permet modificar una vista existent amb una nova definició. Cal tenir en compte que aquesta és l’única via per modificar una vista sense eliminar-la i tornar-la a crear.
La sentència DROP VIEW és la instrucció proporcionada pel llenguatge SQL per a l’eliminació de vistes.
La seva sintaxi és aquesta, que permet eliminar una o diverses vistes:
La sentència ALTER VIEW és la instrucció proporcionada per modificar vistes. La seva sintaxi és aquesta:
alter view <nom_vista> [(columna1, ....)] as <sentència_select>;
Exemple 1 de creació de vistes
En l’esquema empresa, es demana una vista que mostri totes les dades dels empleats acompanyades del nom del departament al qual pertanyen.
La sentència pot ser la següent:
Una vegada creada la vista, es pot utilitzar com si fos una taula, com a mínim per executar-hi sentències SELECT:
Exemple 2 de creació de vistes
En l’esquema empresa, es demana una vista per visualitzar els departaments de codi parell.
La sentència pot ser aquesta:
Operacions d'actualització sobre vistes en MySQL
Les operacions d’actualització (INSERT, DELETE i UPDATE) són, per als diversos SGBD, un tema conflictiu, ja que les vistes es basen en sentències SELECT en què poden intervenir moltes o poques taules i, fins i tot, altres vistes, i per tant cal decidir a quina d’aquestes taules i/o vistes correspon l’operació d’actualització sol·licitada.
Per a cada SGBD, caldrà conèixer molt bé les operacions d’actualització que permet sobre les vistes.
Cal destacar que les vistes en MySQL poden ser actualitzables o no actualitzables: les vistes en MySQL són actualitzables, és a dir, admeten operacions UPDATE, DELETE o INSERT com si es tractés d’una taula. Altrament són vistes no actualitzables.
Les vistes actualitzables han de tenir relacions un a un entre les files de la vista i les files de les taules a què fan referència. Així, doncs, hi ha clàusules i expressions que fan que les vistes en MySQL siguin no actualitzables, per exemple:
- Funcions d’agregació (SUM( ), MIN( ), MAX( ), COUNT( ), etc.)
DISTINCTGROUP BYHAVINGUNION- Subconsultes en la sentència
select - Alguns tipus de
join - Altres vistes no actualitzables en la clàusula
from - Subconsultes en la sentència
whereque facin referència a taules de la clàusulaFROM
Una vista que tingui diverses columnes calculades no és inserible, però sí que es poden actualitzar les columnes que contenen dades no calculades.
Exemple d'actualització en una vista
Recordem una de les vistes creades sobre l’esquema empresa:
Si volem modificar la comissió d’un empleat concret (emp_no=7782) mitjançant la vista EMPD ho podem fer tal com segueix:
Amb el resultat esperat, que s’haurà canviat la comissió de l’empleat, també, en la taula EMP.
Si volem canviar, però, el nom de departament d’aquest empleat (emp_no=7782) i ho fem amb la instrucció següent:
El resultat serà que també s’hauran canviat els noms dels departament de comptabilitat dels companys del mateix departament, ja que, efectivament, s’ha canviat el nom del departament dins de la taula de DEPT, i potser aquest no és el resultat que esperàvem.
Exemple d'eliminació i inserció en una vista
Recordem la vista EMPD creada sobre l’esquema empresa:
Si intentem executar una sentència DELETE sobre la vista EMPD, el sistema no ho permetrà, en tractar-se d’una vista que conté una join i, per tant, dades de dues taules diferents.
Podem executar INSERT sobre la vista EMPD i tampoc no ho podrem fer.
Exemple d'operacions d'actualització sobre vistes
Recordem la vista DEPT_PARELL creada sobre l’esquema empresa:
Ara efectuarem algunes insercions, alguns esborraments i algunes modificacions de departaments parells per mitjà de la vista DEPT_PARELL.
Aquesta instrucció provoca la inserció d’una fila sense cap problema en la taula DEPT.
Aquesta instrucció provoca la inserció d’una fila sense cap problema, però aquesta inserció no es produiria si la vista hagués estat creada amb l’opció with check option, ja que en aquesta situació els departaments inserits en la taula DEPT per mitjà de la vista DEPTPARELL haurien de verificar la clàusula where* de la definició de la vista.
Podem comprovar que si fem aquesta modificació, ens dóna un error en la inserció d’un codi no parell:
La instrucció següent provoca error perquè s’ha definit l’opció with check option, ja que en aquesta situació el departament 50 ha estat seleccionat però no ha pogut canviar a 51 perquè no compleix la clàusula where de la vista. Si tornem a evitar l’opció with check option en la definició de la vista, l’actualització del departament 50 (seleccionable per la vista, en ser parell) cap a departament 51 no donarà cap error i farà el canvi de codi volgut:
delete from DEPT_PARELL where dept_no IN (50, 55);
Aquesta instrucció no esborra cap departament, ja que el 50 no existeix (l’hem canviat a 51), i el 55 existeix però no és seleccionable per mitjà de la vista ja que no és parell.
Sentència RENAME
La sentència RENAME és la instrucció proporcionada pel llenguatge SQL per modificar el nom d’una o diverses taules del sistema.
La seva sintaxi és aquesta:
Sentència TRUNCATE
La sentència TRUNCATE és la instrucció proporcionada pel llenguatge SQL per eliminar totes les files d’una taula.
La seva sintaxi és aquesta:
TRUNCATE és similar a delete de totes les files (sense clàusula where). Funciona, però, eliminant la taula (DROP TABLE) i tornant-la a crear (CREATE TABLE).
Creació, actualització i eliminació d'esquemes o bases de dades en MySQL
Recordem que en MySQL un SCHEMA és sinònim de DATABASE i que consisteix en una agrupació lògica d’objectes de base de dades (taules, vistes, procediments, etc.).
Per crear una base de dades o un esquema es pot utilitzar la sintaxi bàsica següent:
Per modificar una base de dades o un esquema es pot utilitzar la sintaxi següent, que permet canviar el nom del directori en què està mapada la base de dades o el conjunt de caràcters:
Per eliminar una base de dades o un esquema es pot utilitzar la sintaxi bàsica següent:
Com es poden conèixer els objectes definits en un esquema de MySQL
Una vegada que sabem definir taules, vistes, índexs o esquemes, i com modificar, en alguns casos, les definicions existents ens sorgeix un problema: com podem accedir de manera ràpida als objectes existents?
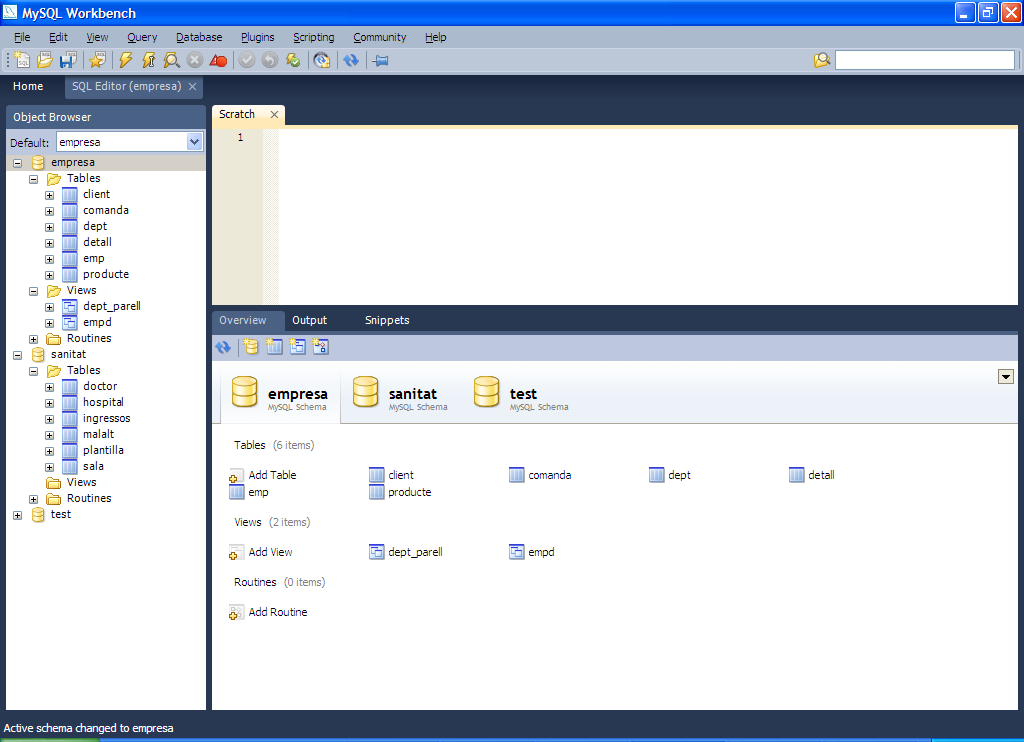
L’eina MySQL Workbench és una eina gràfica que permet, entre altres coses, veure els objectes definits dins del SGBD MySQL i explorar les bases de dades que integra.
Es pot veure en la figura l’eina MySQL Workbench en l’apartat SQL Development com es pot navegar pels diferents objectes de les bases de dades que gestiona MySQL.
És important saber, també, que l’SGBD MySQL ens proporciona un conjunt de taules (que formen el diccionari de dades de l’SGBD) que permeten accedir a les definicions existents. N’hi ha moltes, però ens interessa conèixer les de la taula. Totes incorporen una gran quantitat de columnes, la qual cosa fa necessari esbrinar-ne l’estructura, per mitjà de la instrucció desc, abans d’intentar trobar-hi una informació.
| Taula | Contingut | Exemple d’ús |
|---|---|---|
| information_schema.schemata | Informació sobre les bases de dades de l’SGBD. | select * from information_schema.schemata; |
| information_schema.tables | Informació sobre les taules de les diferents bases de dades de MySQL. | select * from information_schema.TABLES where table_schema=‘sanitat’; |
| information_schema.columns | Informació sobre columnes de les taules de les diferents bases de dades de MySQL. | SELECT COLUMN_NAME, DATA_TYPE, IS_NULLABLE, COLUMN_DEFAULT FROM INFORMATION_SCHEMA.COLUMNS WHERE table_name = ‘doctor’ AND table_schema = ‘sanitat’; |
| information_schema.table_constraints | Informació sobre les restriccions de les taules de la base de dades. | SELECT * from information_schema.TABLE_CONSTRAINTS where table_schema=‘sanitat’ ; |
| information_schema.views | Informació sobre les vistes de les diferents bases de dades de MySQL. | select * from information_schema.views where table_schema=‘empresa’; |
| information_schema.referential_constraints | Informació sobre les claus foranes de les taules de la base de dades. | select * from information_schema.REFERENTIAL_CONSTRAINTS; |
Hi ha formes abreujades, però, de mostrar la informació d’aquestes taules del diccionari; per exemple, per mostrar les taules o les columnes de les taules, podem utilitzar aquestes formes simplificades: